UP-DETR: Unsupervised Pre-Training for Object Detection With Transformers
UP-DETR: Unsupervised Pre-Training for Object Detection With Transformers
CVPR 2021, 2024-04-18 기준 482회 인용
Task
- Object Detection
- DETR
Contribution
- DETR 에서 backbone 에 해당하는 CNN 은 풍부한 데이터에 pre-trained 된 모델이다
- 왜 transformer module 은 pre-training 하지 않는가?
- unsupervised 로 large scale dataset (ImageNet) 으로 transformer module 도 pre-training 하자!
- human annotation 이 없는 데이터셋에서 random query patch detection 을 통해 pre-training 하는 Unsupervised Pre-Training DETR (UP-DETR) 구조 제안
Proposed Method
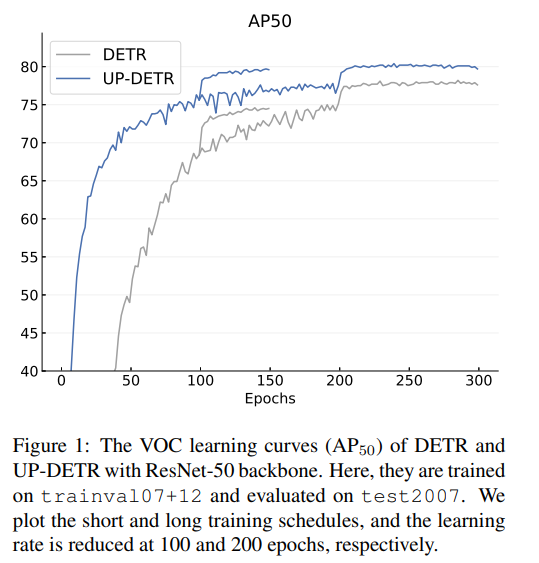
기존의 DETR 보다 성능이 좋고 학습 수렴 속도가 빨라졌다
Single-Query Patch
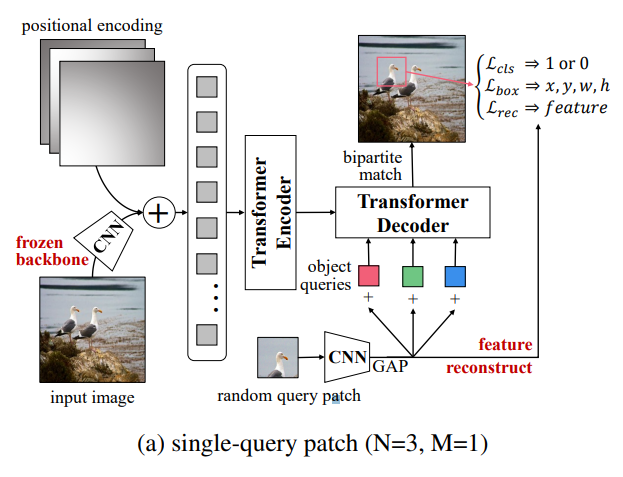
human annotation 이 필요없는 데이터를 활용 (ImageNet)
Image 로 부터 random crop → random crop 된 box를 GT로 활용
random query patch 를 backbone CNN로 부터 feature를 추출하고 GAP 를 통해서 아래와 같이 된다
$p \in \mathbb{R}^C$
이를 N개의 object queries 에 더해준다
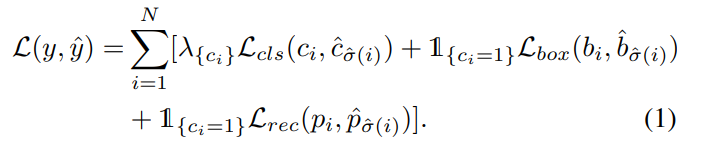
object queries로 부터 class 와 box 를 예측
여기서 class 는 query patch 인지 아닌지에 대한 정보 (0 or 1)
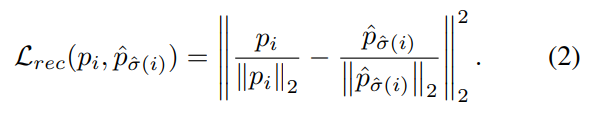
localization 에 대해서 학습되는 과정에서 classification 을 위한 feature 가 망가지는 것을 방지하기 위해서 reconstruction loss를 추가
backbone CNN 으로 부터 얻은 feature 와 transformer를 통과한 feature를 비교
같은 이유로 pre-training stage 에서 CNN 은 고정
Multi-Query Patches
general object detection 에서 한 장의 이미지에 instances 가 여러개 존재 (COCO 데이터셋에서는 평균적으로 1장에 7.7개의 instances 존재)
single query patch 로만으로는 이를 모두 처리하기 한계가 있음
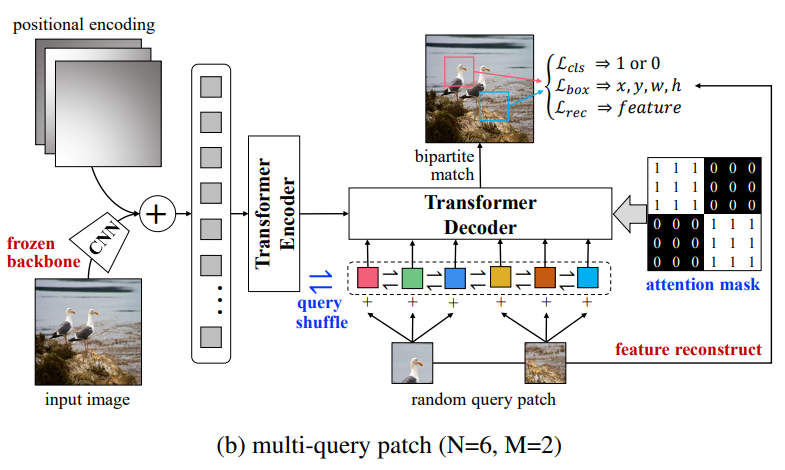
이미지에서 다수의 query patch 를 추출
순서대로 object queries 에 할당 (N/M 만큼)
각 query patches 마다의 independence 를 위해서 attention mask를 만들어서 추가
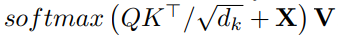

같은 query patch 으로 부터 만들어진 query 끼리만 interaction 하도록 (Figure 에서는 직관을 위해서 1, 0 으로 표현)
Experimental Results
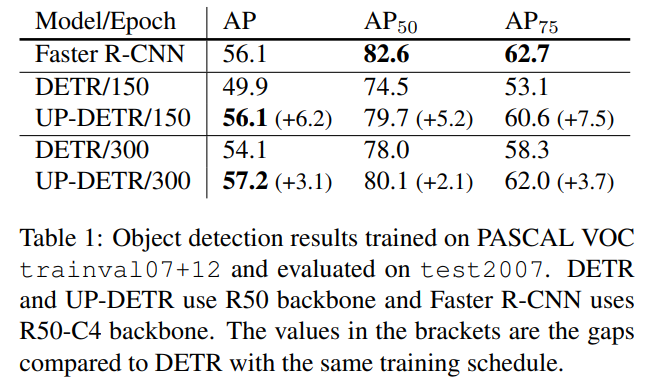
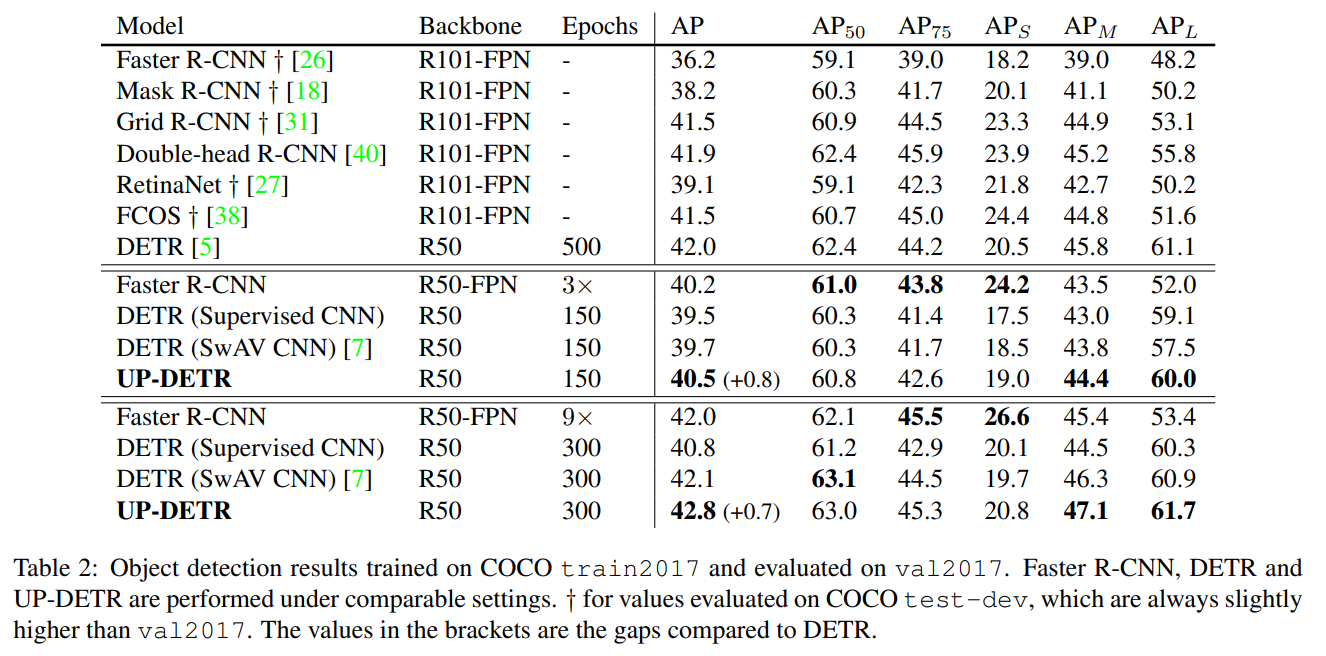
VOC, COCO 데이터셋에 대해서 기존의 DETR 보다 성능이 향상 되었다
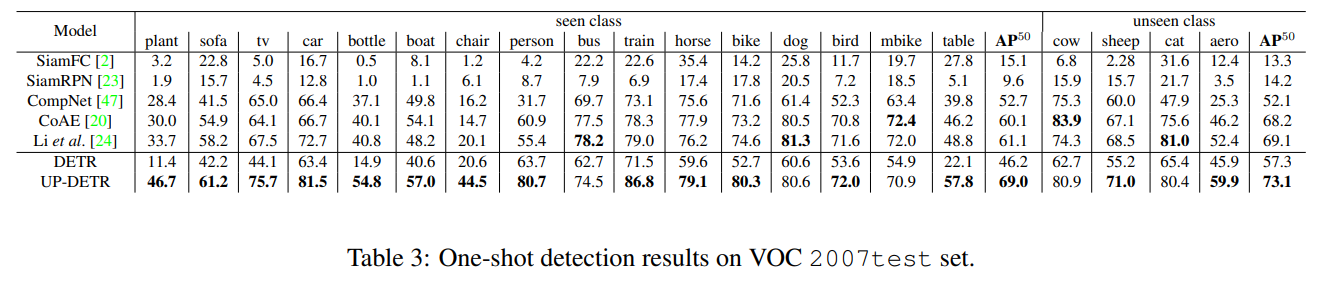
One-Shot Detection 실험
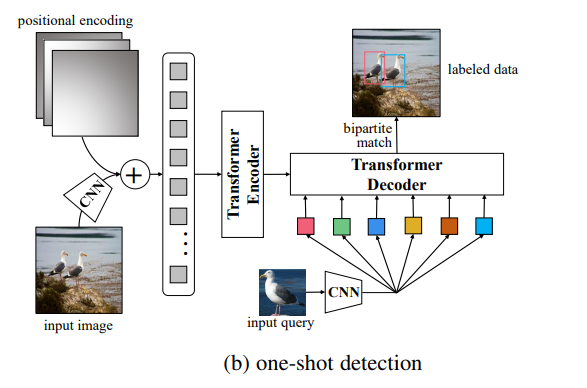
해당 figure 는 Github issues 에서 저자가 공유해준 것
one-shot 에 해당하는 이미지를 query patch 로 여기고 pre-training