TR-DETR: Task-Reciprocal Transformer for Joint Moment Retrieval and Highlight Detection
TR-DETR: Task-Reciprocal Transformer for Joint Moment Retrieval and Highlight Detection
AAAI 2024, 2024-03-18 기준 0회 인용
Task
- Video moment retrieval
- Highlight detection
Contributions
- Video Moment Retrieval (MR), Highlight Detection (HD) 을 동시에 해결
- DETR-based method 로 두 가지 task 다룸
- Task-reciprocal transformer based on DETR (TR-DETR) 구조를 제안
Proposed Method
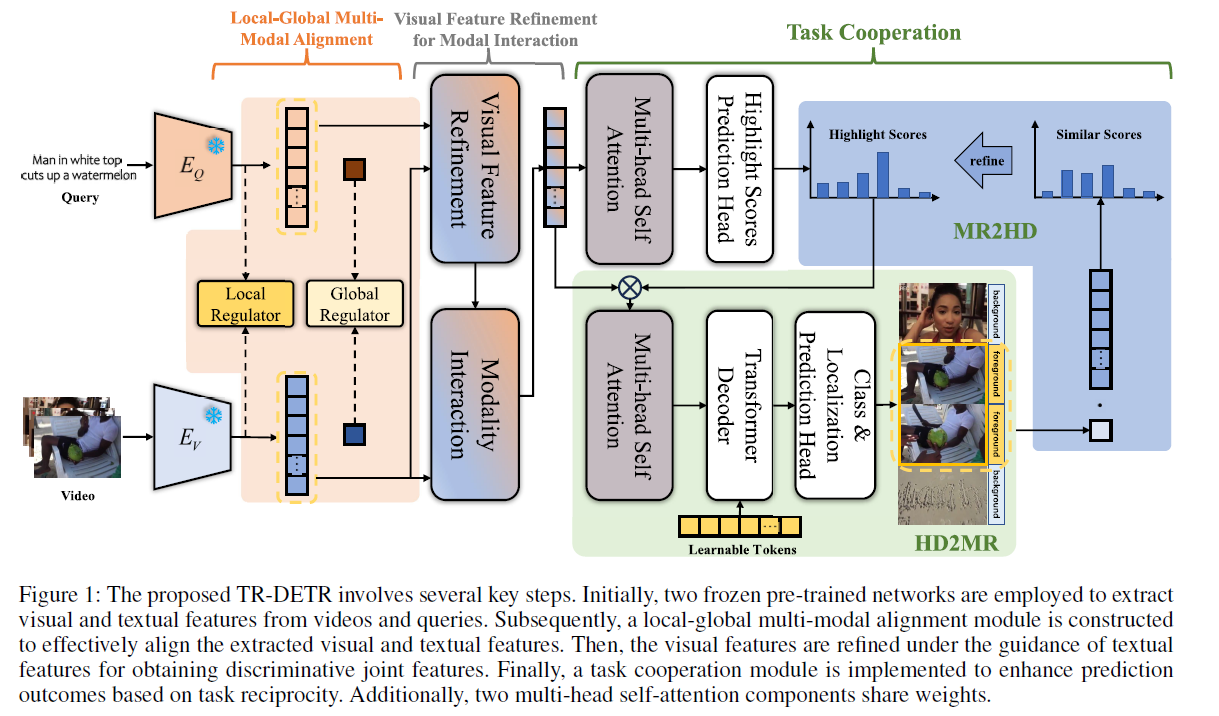
Feature Extraction
비디오를 2s 간격으로 안겹치기 나누어서 사용
CLIP 을 통해서 visual feature extraction
$F_v = [f^1_v,f^2_v, …, f^L_v] \in \mathbb{R}^{L \times d_v}$
“UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection”
위 논문에서 제안된 방법을 기반으로 audio feature extraction
$F_a \in \mathbb{R}^{L \times d_a}$
natural language query 를 위해서 CLIP textual encoder 사용
$F_t = [f^1_t,f^2_t, …, f^N_t] \in \mathbb{R}^{N \times d_t}$
Local-Global Multi-Modal Alignment
visual feature 와 textural feature 에 대한 alignment
Local regulator
각 clip 별로 text 와 관련있는 feature 만 고려할 수 있도록
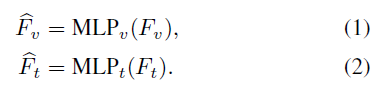
동일한 dimension 으로 조절
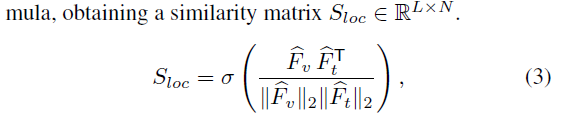
similiarty matrix 를 연산
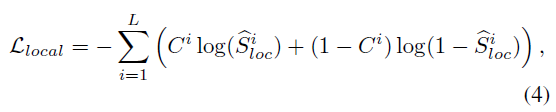
Moment Retrieval (MR) 에 있는 정보 활용
text query 와 clip 간의 relevant 있는 경우 1, 없는 경우 0
Global regulator
전체적인 semantic space 가 가까워지도록
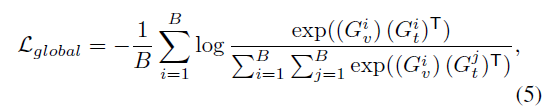
$G^i_v$ 는 $\hat F_v$ 의 모든 clip feature 를 average
$G^i_t$ 는 $\hat F_t$ 의 모든 word feature 를 average
Visual Feature Refinement for Modal Interaction
visual feature 와 textual feature 간 interaction 을 한번 더 강화
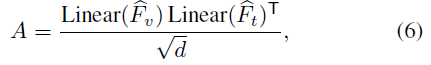
visual feature 와 textual feature 에 대해서 similarity matrix 생성
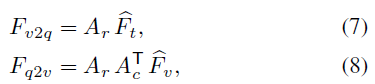
$A_r$ - row 방향으로 softmax
$A_c$ - column 방향으로 softmax
$F_{v2q}$ - visual 에 대한 값들을 textual feature 에 곱
$F_{q2v}$ - textual 에 대한 값들을 visual feature 에 곱
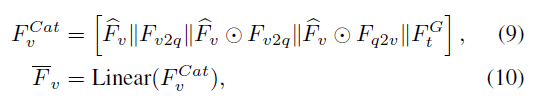
구해진 feature 들을 concatenate 하고 Linear Layer 통과
$F^G_t$ 는 textual global features 를 단순히 copying 해서 $\mathbb{R}^{L \times d}$ 로 만든 것
그러고 한번 더 textual feature 랑 cross-attention 진행
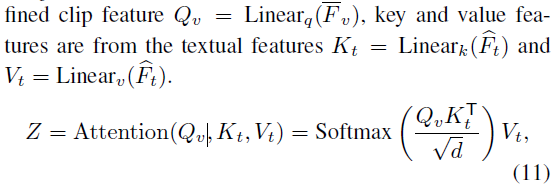
Task Cooperation
Highlight score 는 MR 하는데 도움을 줄 수 있다
MR 의 결과 또한 Highlight score 예측에 도움을 줄 수 있다
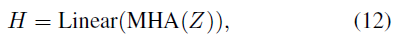
Multi-head attention, Linear 를 통해서 Highlight score 를 예측
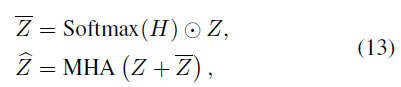
기존에 있던 feature $Z$ 에 연산하고 MHA 를 통해서 강화된 feature $\hat Z$ 를 연산
해당 값을 Transformer Decoder 입력으로 사용해서 MR 결과를 prediction

gated recurrent unit (GRU) 를 통해서 global information 을 포함하는 feature를 연산
$m$ 은 MR 에서 예측된 moment
$\hat F_v$ 에서 해당 moment의 feature
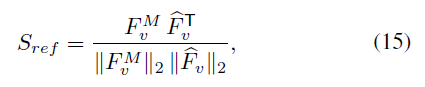
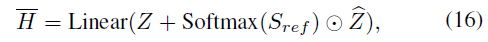
moment 에 해당하는 feature 와 전체 clip 에 대한 feature 와 correlation 을 연산
이를 기반으로 Highlight score 를 refine
Experimental Results
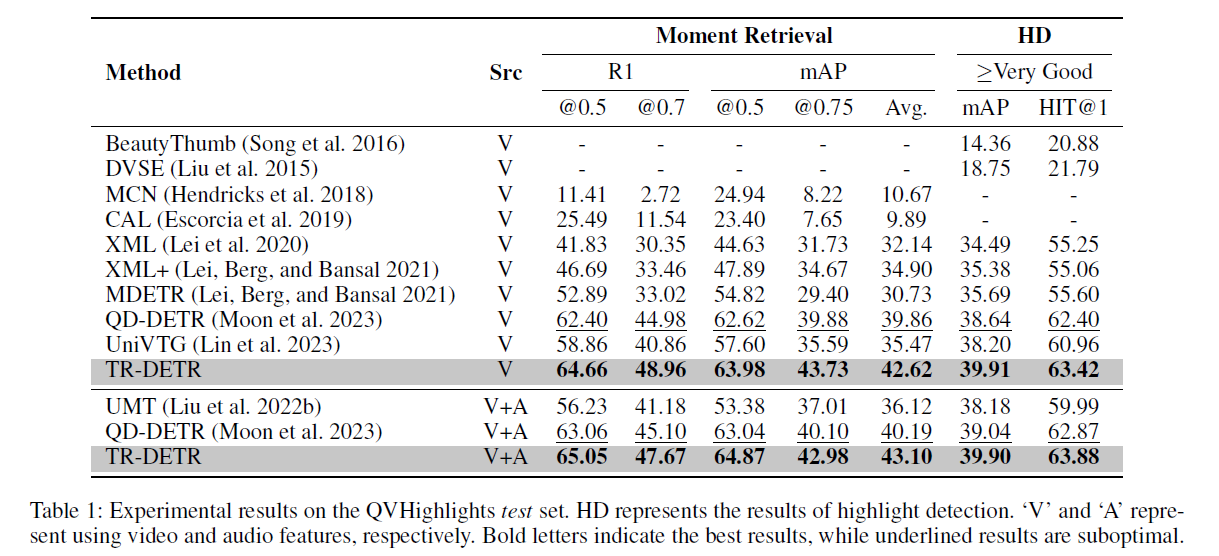
Moment Retrieval (MR) 과 Highlight Detection (HD) 에 대한 실험 결과
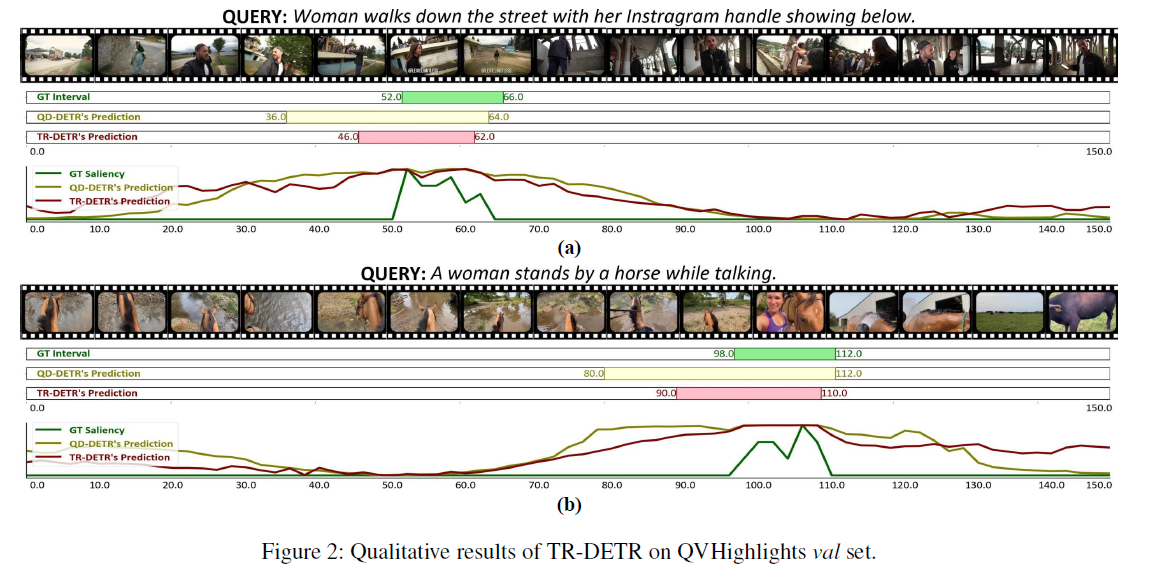
Highlight score 를 visualization
제안하는 TR-DETR 은 높은 threshold 를 사용
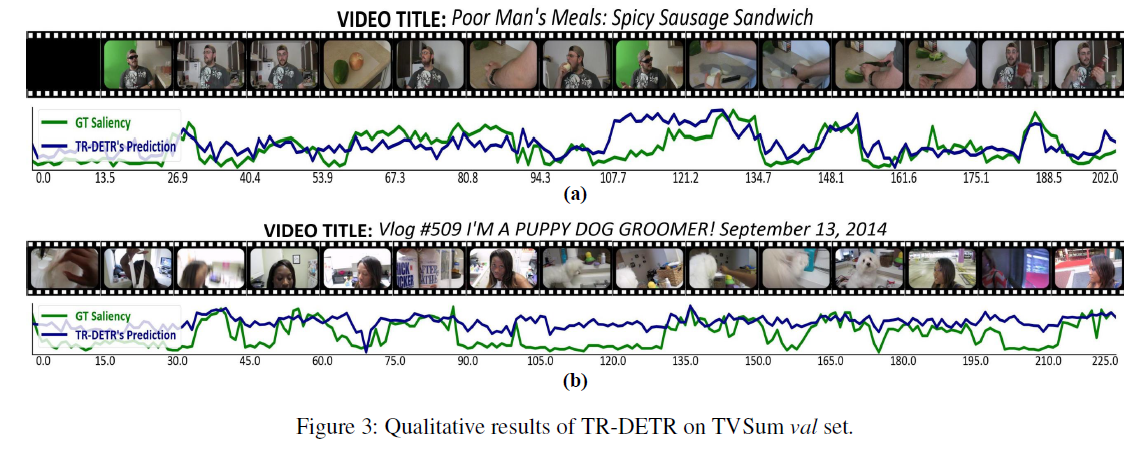
TVSum 데이터셋에 대해서 Highlight score 와 GT 와 visulaization