Sparse DETR: Efficient end-to-end object detection with learnable sparsity
Sparse DETR: Efficient end-to-end object detection with learnable sparsity
ICLR 2022, 2024-04-08 기준 108회 인용
Task
- Object Detection
- DETR
Contribution
- Encoder token 을 일부분만 선택해서 업데이트 하는 구조 제안
- token 선택을 위해서 Decoder cross-attention map 을 활용
- object query 로 encoder output feature를 사용 (Efficient DETR과 비슷한 방식)
Proposed Method
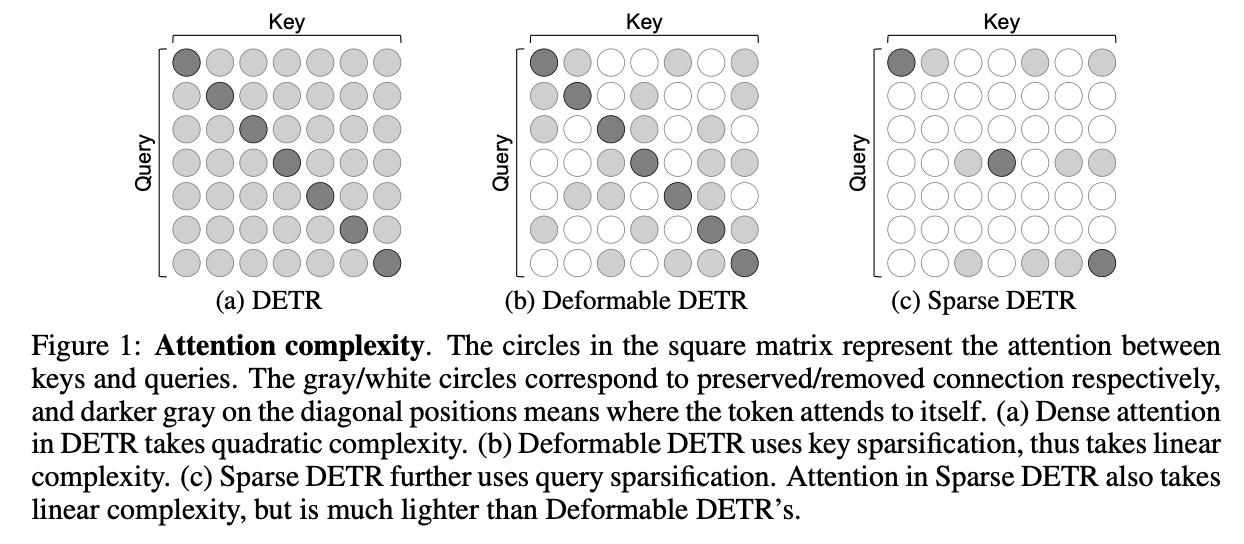
기존의 DETR 은 (a) 와 같이 dense 하게 모든 attention 연산을 해야함
Deformable DETR 은 (b) 와 같이 key sparsification 으로 key에 대해서만 일부분 sparse
본 논문에서 제안하는 Sparse DETR 은 (c) 와 같이 query sparsification 도 사용하여 훨씬 더 sparse 하다
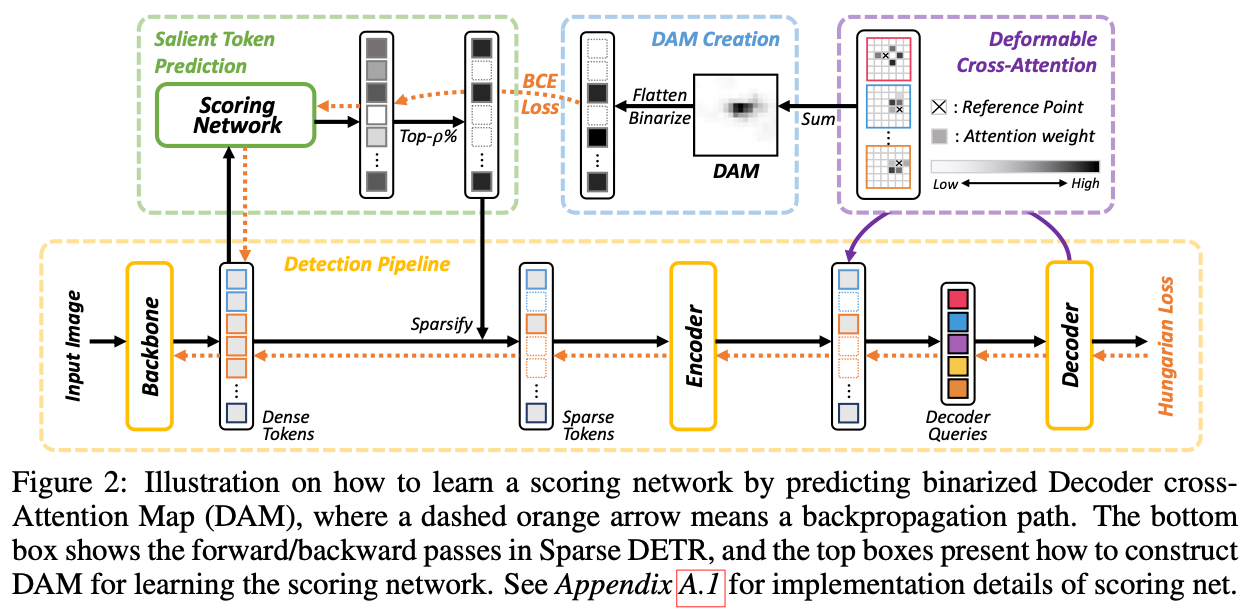
$g : \mathbb{R}^d \rightarrow \mathbb{R}$
score network - 4 linear layers
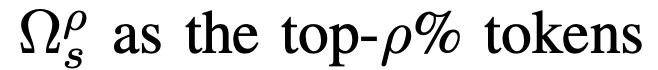
top p% tokens 를 뽑는다
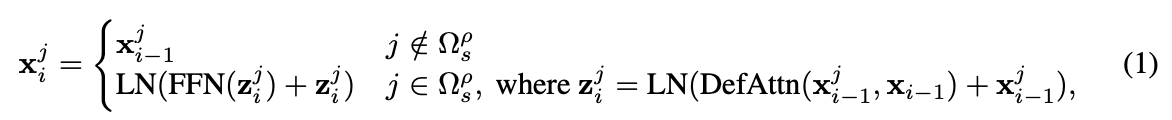
top p% 안에 들어오는 token은 deformable attention 을 진행
들어오지 않는 token 은 값을 그대로 사용
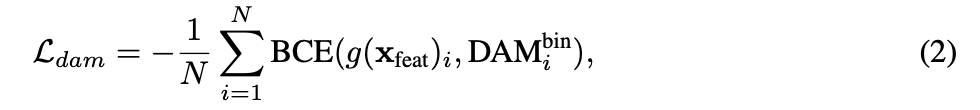
Encoder token sparsity 를 위한 score network 학습 loss
Complexity of Attention Modules in Encoder
DETR - O(N * N)
Deformable DETR - O(N * K)
Sparse DETR - O(S * K)

Encoder Auxiliary Loss
기존의 DETR 은 dense 하게 token 을 사용하므로 encoder layer에서 auxiliary head를 사용하는건 부담
Sparse DETR은 sparse 하게 token을 사용하기 때문에 encoder layer에서 auxiliary head를 사용해도 cost 면에서 부담없다라고 주장
Encoder layer 에 각각 auxiliary head 추가, decoder layer에도 각각 추가
Top-k Decoder Queries
Encoder outputs 을 decoder의 input로 사용하기 위해서 head 추가
head calculates the objectness (class) score of each encoder output
k-top score 로 선택
Experimental Results
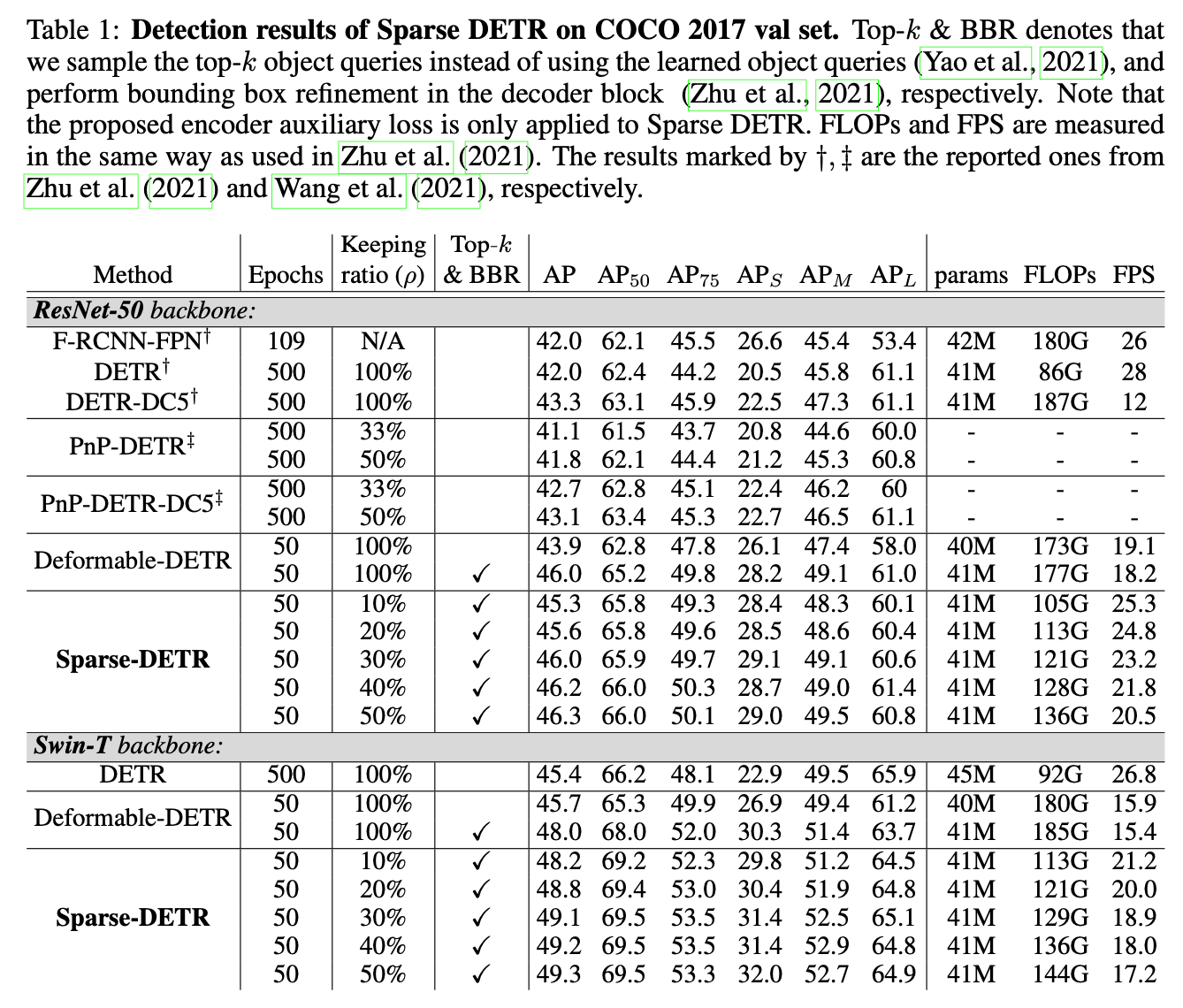
keeping ratio - encoder token 유지 수 비율
Top-k & BBR - object query 로 Encoder output를 head를 통과시키고 top k 사용한 것 + bounding box refinement 한 것
Deformable-DETR 에 비해 제안하는 방법이 성능이 향상되고 FPS 가 증가함
덕지덕지 붙인 head들 때문에 FLOPs 가 증가하고 inference time이 증가할 것 같았는데 논문에서 주장하는 것과 같이 encoder 의 token 수를 줄인 것이 굉장한 효과가 있는 것으로 보인다