SimPLR: A Simple and Plain Transformer for Object Detection and Segmentation
SimPLR: A Simple and Plain Transformer for Object Detection and Segmentation
Under Review ICLR 2024, 2024-02-21 기준 0회 인용 (Withdraw 한 것 같음)
Task
- Object Detection
- DETR
Contribution
- Multi-sacle feature 를 사용하는 것이 성능 향상에 좋지만 꼭 필요할까?
- Plain Backbone Vision Transformer (ViT) 를 사용, Feature pyramids 는 필요없다
- Sacle-aware attention 을 제안하여 SimPLR 을 제안
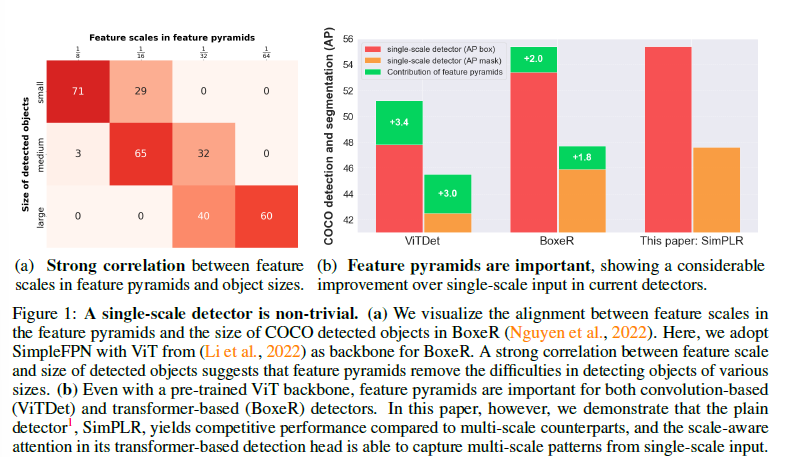
Feature scale 과 object size 와의 correlation 은 크다
그렇기에 기존의 방법들은 single-scale 만 사용했을 때 성능은 multi-scale 일때보다 떨어진다
본 논문에서 제안하는 방법은 scae-ware attention 을 적용시켜 single-scale 에서도 좋은 성능을 보여준다
Proposed Method
Background (BoxeR)
BoxeR 에서 제안한 box-attention mechanism 을 strong baseline 으로 사용

reference windows 를 transform 해서 사용하겠다는 수식
(본 논문에서의 거의 유일한 수식..)
Single-scale detector
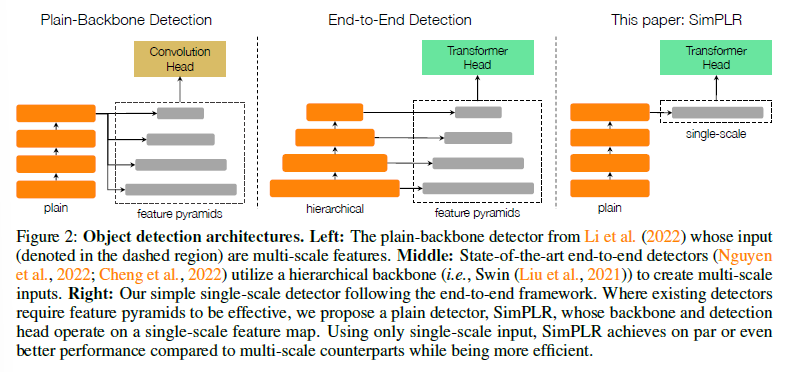
Multi-scale feature 를 만들어서 사용하는 것이 아닌 single-scale 으로만 설계
Scale-aware attention
Box-Attention 을 그대로 사용
저자들은 아래와 같이 설명
- 각 query 마다 reference windows 를 만들고 mutli-head attention
- reference windows transform 하면서 attention 하니까 여러 scale, translation 을 고려
-> 그러니 scale-aware mechanisms 이다!
하지만 Box-Attention 에서 reference windows 를 transform 하더라도 전체 size 자체는 고정되어있고 조금씩 움직이는 것이기 때문에 여러 scale 의 object 를 커버해주지는 못한다
While this behaviour may not impact the multi-scale box-attention
그래서 두 가지 scale attention 을 제안
- Fixed-Scale Attention
- 단순하게 그전에는 고정된 사이즈의 reference windows 를 사용했더라면 $m$ 개의 다른 scale 의 reference windows 를 사용
- $w=h \in {s \cdot 2^j }^{m-1}_{j=0}$
- 최소 size $s$ 로부터 키워나가는 방식
- $m$ 개의 scale 에 대한 reference windows 들을 $n$ 개의 multi-head 에 uniform 하게 배분
- Adaptive-Scale Attention
- Fixed-Scale Attention 과 거의 동일
- query vector 로 부터 $m$ 개의 scale 에 대한 attention weights 를 prediction
- small object 는 fine-grained scale 의 reference windows를 더 보도록 설계
Experimental Results
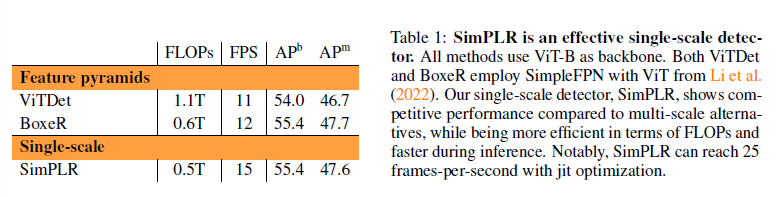
single-scale 로 해더 성능차이가 크지 않다
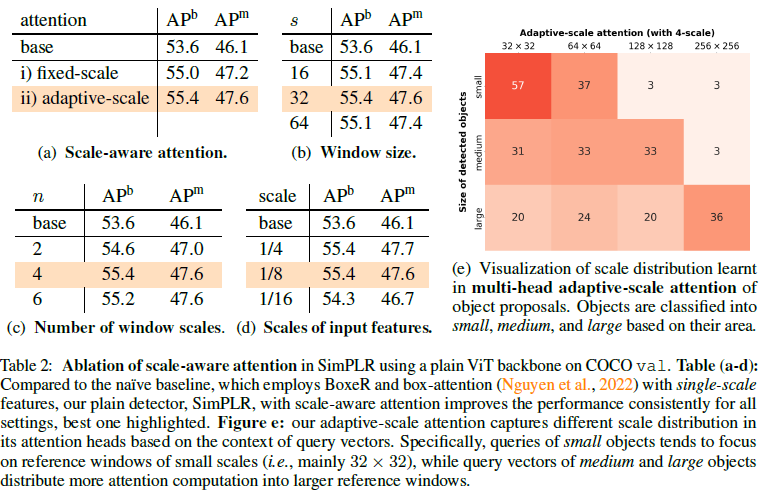
Ablation study & Adative-scale attention 에서의 각 scale과 검출된 object 크기에 따른 수
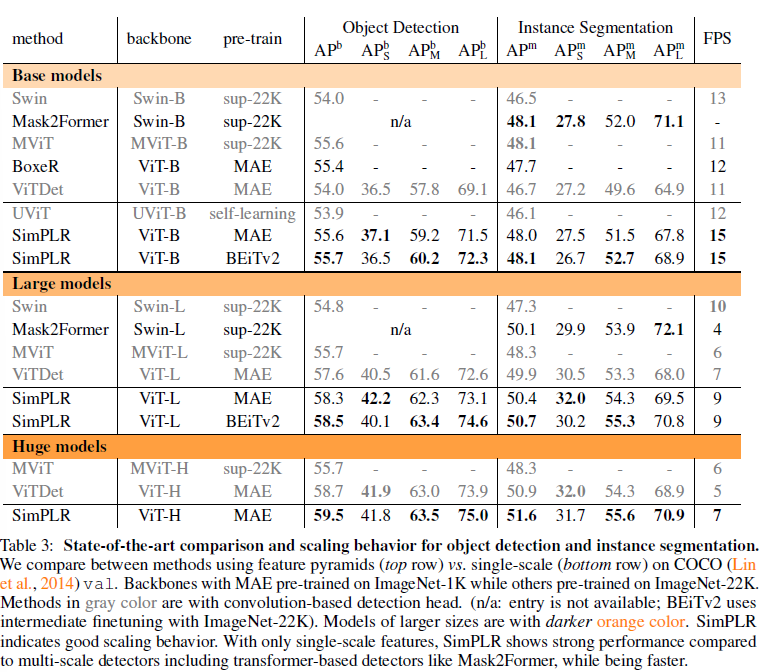
다른 방법들과 비교했을 때 성능이 비교할만 하다