Siamese DETR
Siamese DETR
CVPR 2023, 2024-04-18 기준 2회 인용
Task
- Object Detection
- DETR
Contribution
- 기존의 방법들은 view-invariant representations 학습을 고려하고 있지 않다
- multi-view self-supervised learning for DETR pre-training 을 제안한다
- Siamese network 구조로 제안
Proposed Method
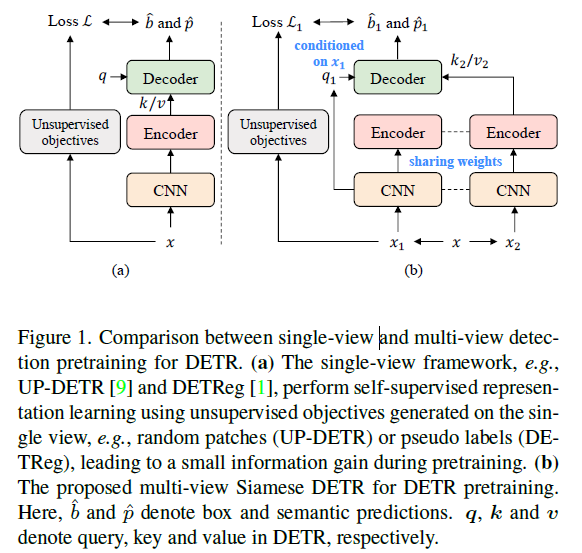
(a) - 기존의 방법들(UP-DETR, DETReg)
(b) - multi-view Siamese DETR 구조
View Construction
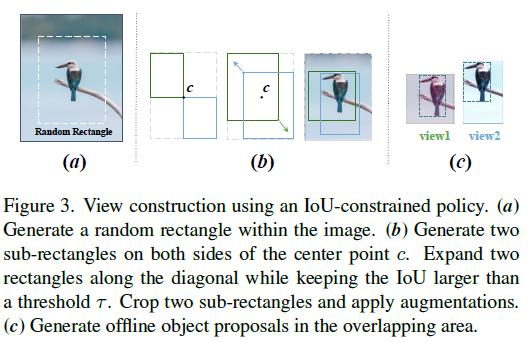
(a) 전체 이미지의 50%~100%를 차지하는 random rectangle 을 생성
(b) rectangle 의 center point를 기반으로 두개의 rectangle 생성 → 두개의 rectangles 의 IoU > 0.5 가 되도록 rectangles 들을 확장
(c) 두개의 rectangles 에서 cropping
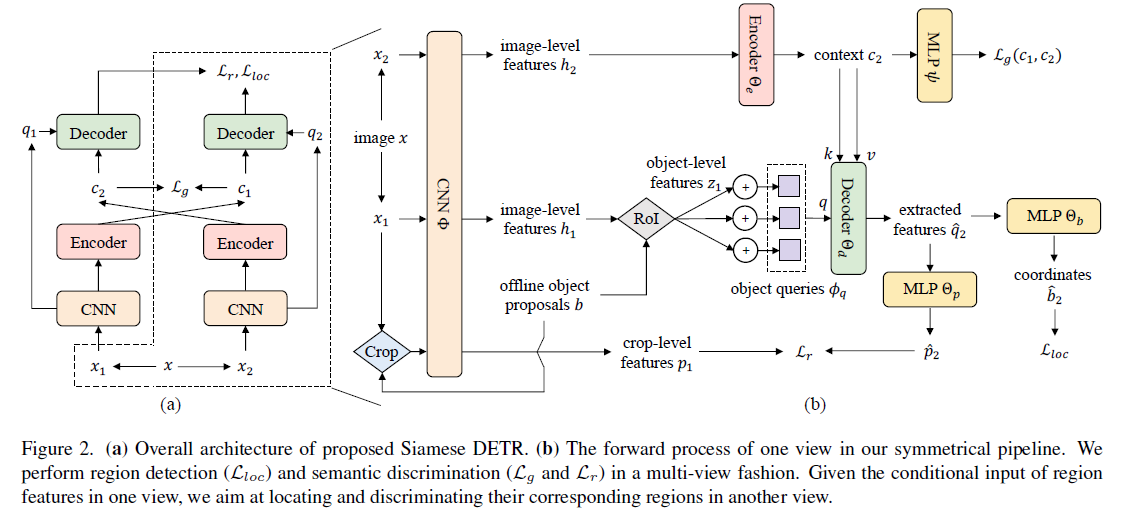
Multi-view Detection Pretraining
$c= \text{Encoder}(h)$
$h = \text{Backbone}(x)$, $x$ 는 이미지
$c$ 는 Encoder 를 통과한 값
DETEReg 에서 Selective Search 쓴것과 마친가지로 여기선 EdgeBoxes를 사용
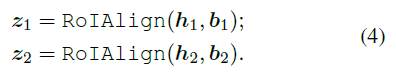
EdgeBoxes로 부터 얻어진 $b1, b2$를 통해서 $z1, z2$ 를 얻어낸다
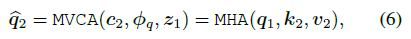
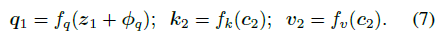
$x_2$ 이미지로 부터 얻어진 $c_2$ 와 $x_1$ 으로 부터 얻어진 query와 cross attention
view $x_1$ 에서의 region feature $z_1$에 해당하는 semantic 정보가 view $x_2$의 feature에 aggregation 될 수 있도록 해준다 → view-invariant representations 학습을 위해서
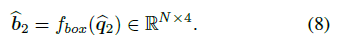
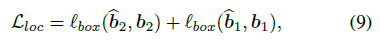
box prediction head 를 통과시키고 localization loss 계산
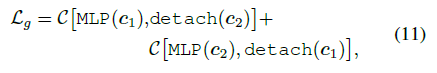
$C$ - negative cosine similarity
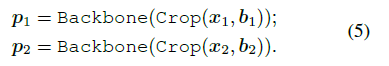
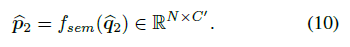
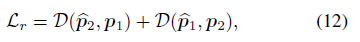
crop-level region 에 대해서도 semantic consistency 가져가기 위한 loss 계산
$D$ - l2 distance
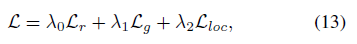
최종 학습 Loss function
Experimental Results
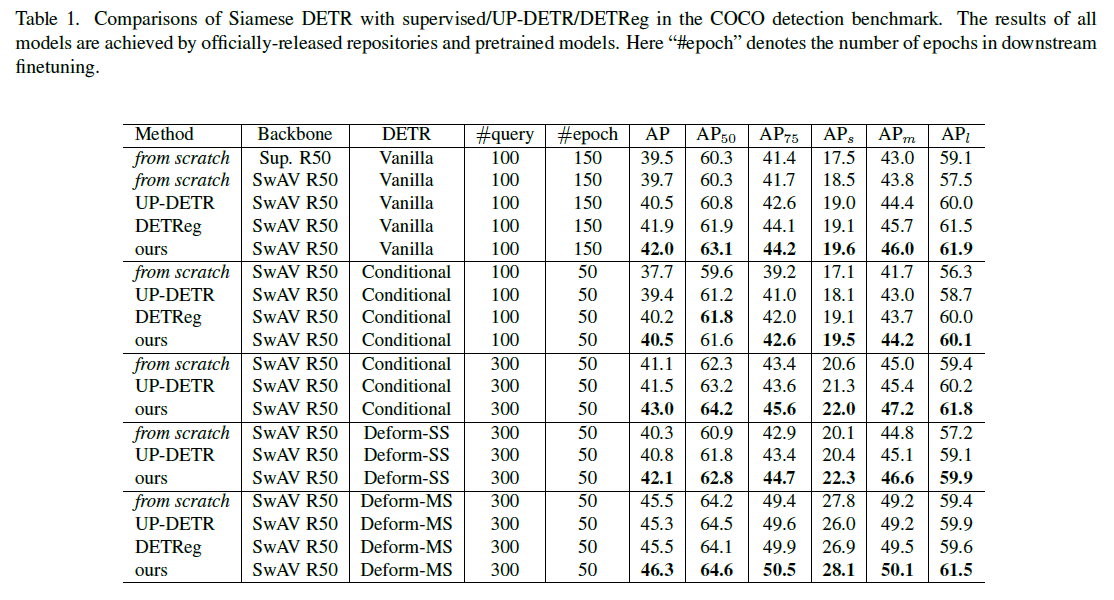
COCO dataset 에 대한 실험 결과
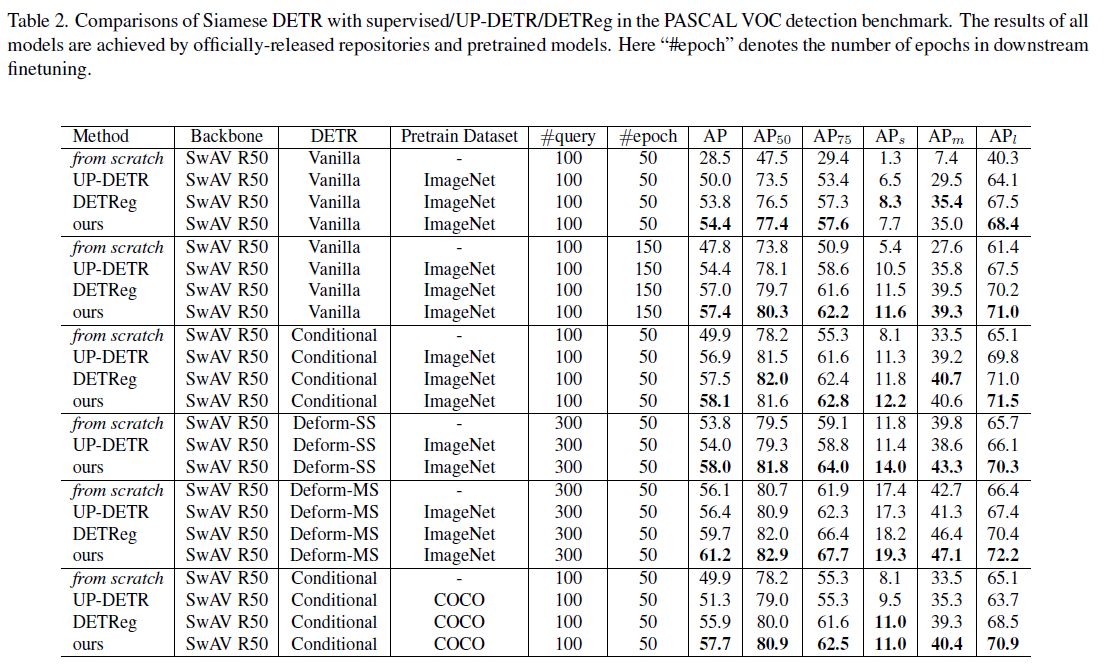
PASCAL VOC dataset 에 대한 실험 결과