Fast Convergence of DETR with Spatially Modulated Co-Attention
Fast Convergence of DETR with Spatially Modulated Co-Attention
ICCV 2021, 2024-04-22 기준 261회 인용
Task
- Object Detection
- DETR
Contribution
- 항상 언급 되듯이 DETR 의 학습 시간은 너무나 길다
- DETR의 500epoch 학습을 108 epoch 으로 줄였다 (21년도 기준으로 많이 줄였다)
- Spatially Modulated Co-attention (SMCA) 를 제안
- plug-and-play module
- Encoder feature 와 object queries 사이 cross-attention 하는 부분에 weight map 을 추가
- Spatially-modulated 되도록 하여 학습 수렴을 더 빠르게
- Scale-selection network 제안
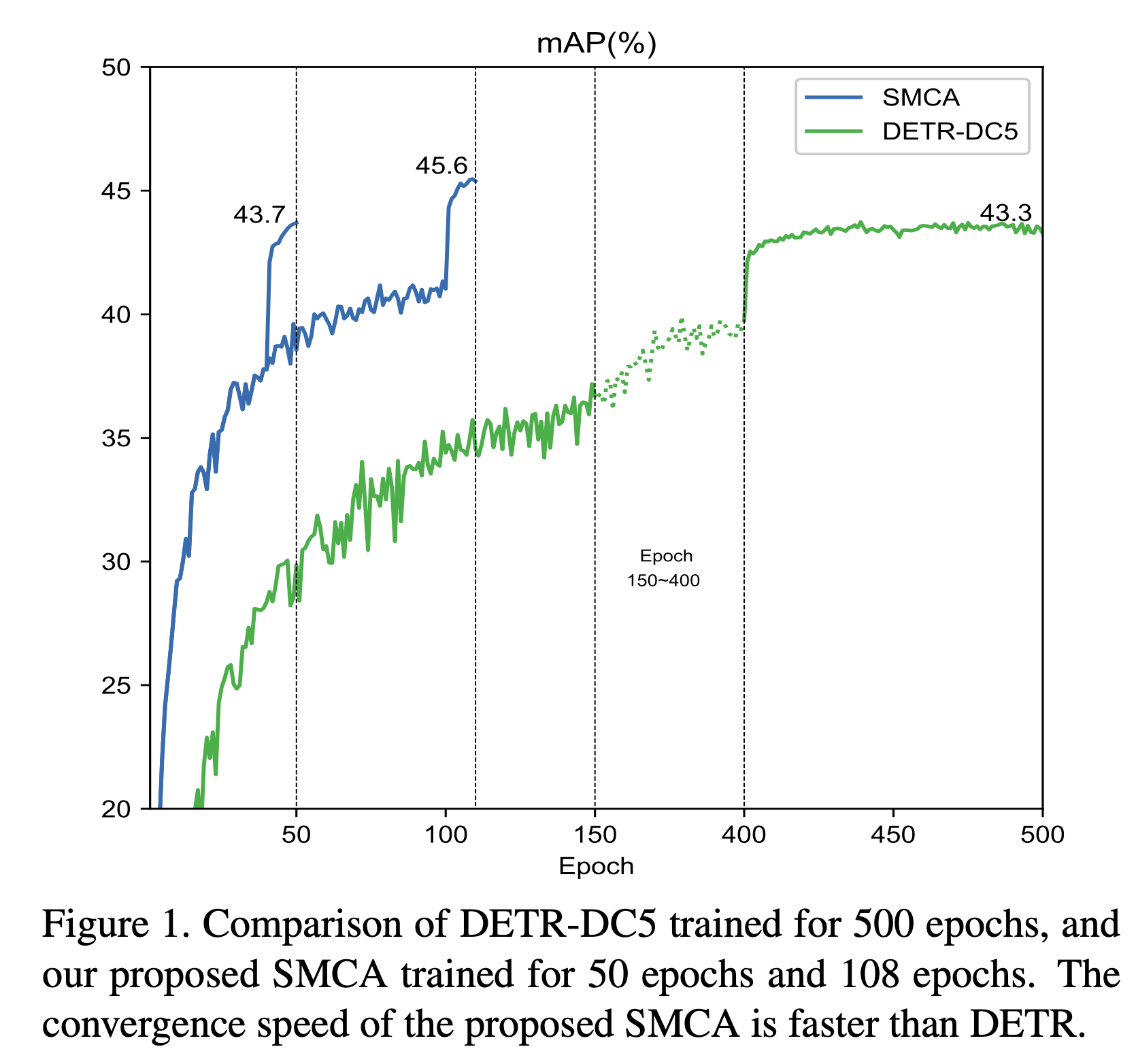
기존 DETR 보다 학습이 훨씬 더 빨리 수렴된다
Proposed Method
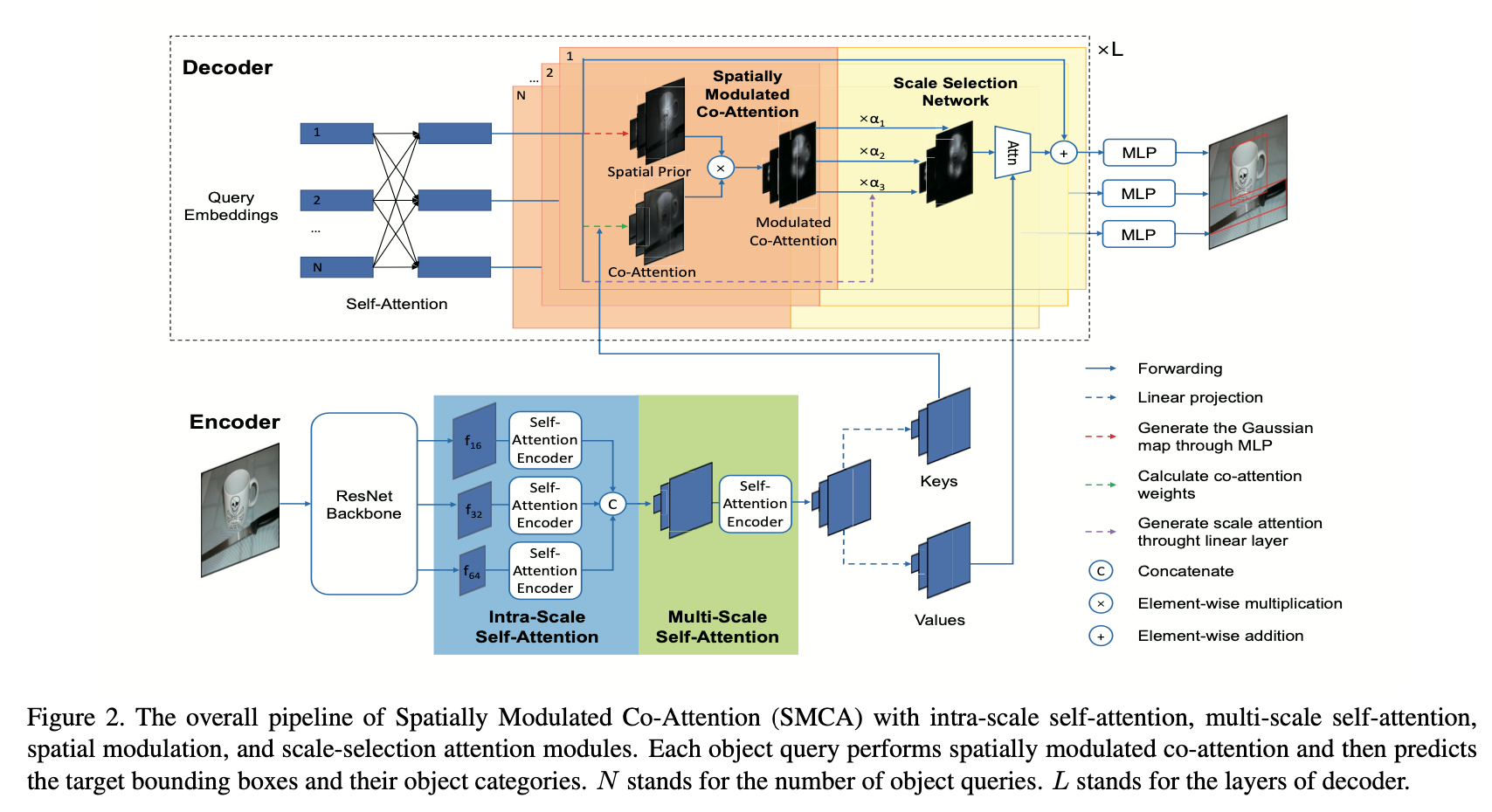
Dynamic spatial weight maps
각 query들에 대한 co-attention map 을 만들어서 cross-attention 시에 location constrained 를 줄 수 있도록 함
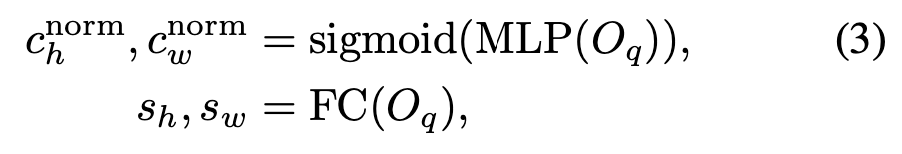
Object query로 부터 center 와 scale을 예측
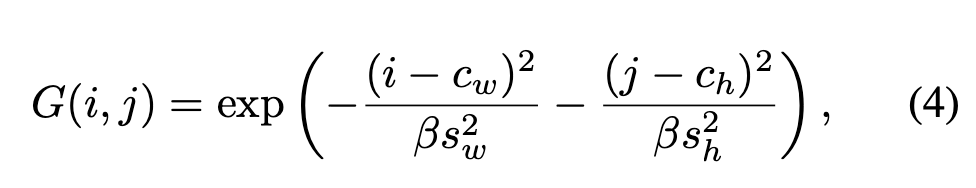
예측된 center 값과 scale 값으로 Gaussian-like weight map 을 생성
generally assigns high importance to locations near the center and low importance to positions far from the center
예측된 center 에 가까울수록 importance를 높게, 멀수록 낮게
Spatially-modulated co-attention
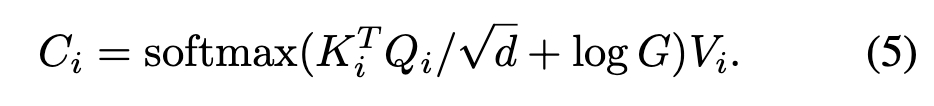
저자들은 먼저 single scale, single head에 적용
cross-attention 쪽에 Gaussian-like weight map 을 더해주고 value 와 연산
이로인해서 예측된 center 주변으로 attention이 되도록
$[c_w, c_h]$
$[\Delta c_{w, i}, \Delta c_{h, i}]$
각 head들은 share 하는 center point 에 대한 offset을 예측
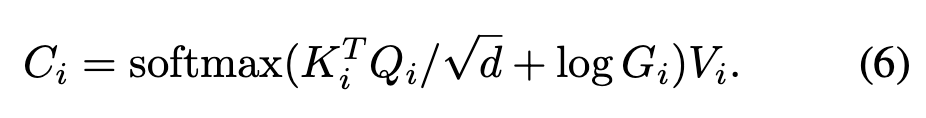
각 head들에 대한 Gaussian-like weight map을 더해줌
SMCA with multi-scale visual features
single scale에 대해서만 적용했을때 training epoch 수는 줄였지만 성능 향상은 크지 않았음
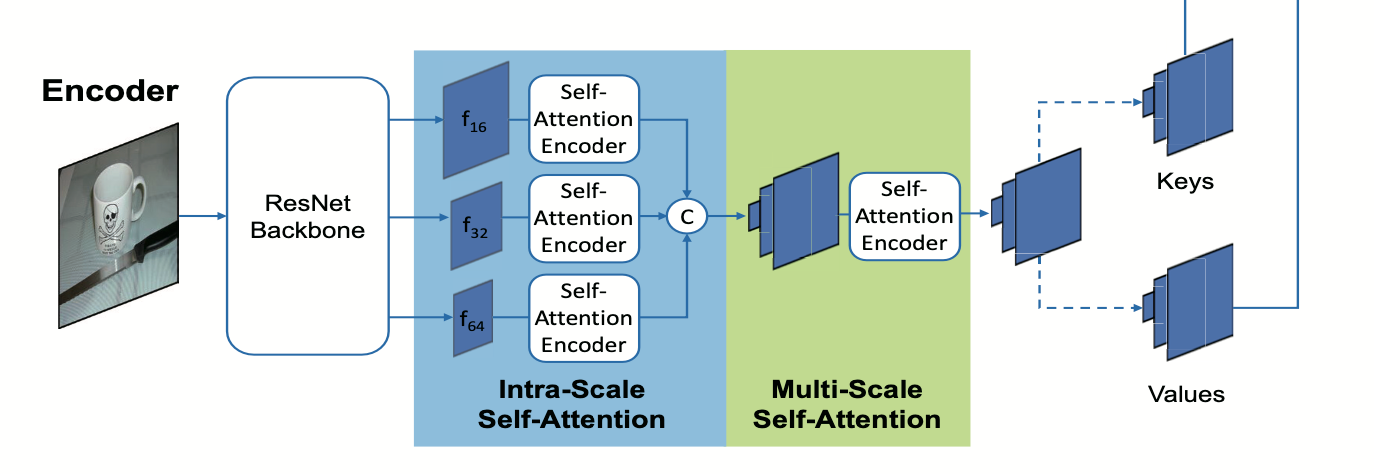
총 5개의 encoder blocks
2 intra-scale self-attention – 1 multi-scale self-attention – 2 intra-scale self-attention
downsampling rate 16, 32, 64 인 3가지 feature 사용
the number of feature pixels of all scales is quite large and the multi-scale self-attention operation is therefore computationally costly
모든 스케일의 pixel에 대해서 self-attention 을 진행하면 computation cost 가 높다
각 scale 별로 self-attention 을 하고 concat 해주는 intra-scale self-attention
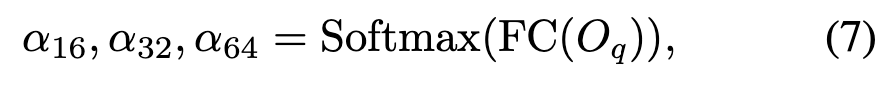
Object query 로부터 각 scale에 대한 scale-selection attention weights를 연산
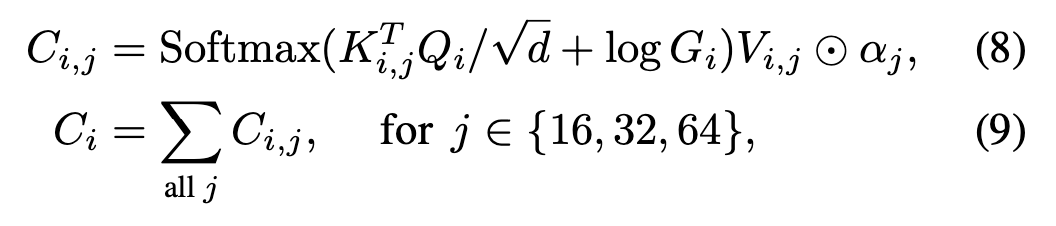
어떤 scale의 feature를 더 볼 것인지 조절
Experimental Results
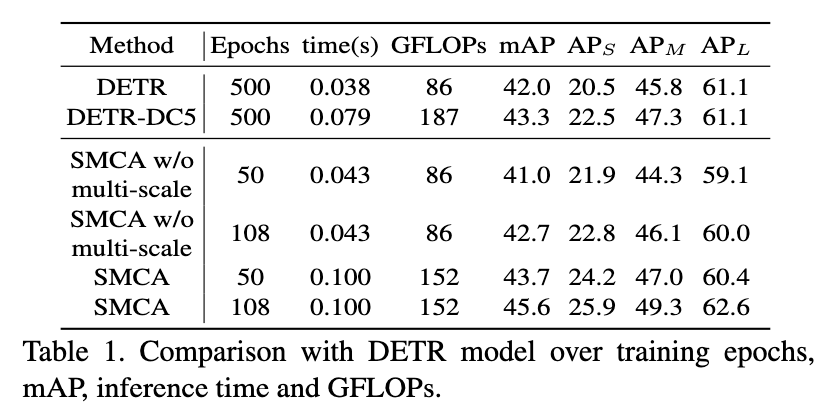
multi-scale 에 대한 ablation study
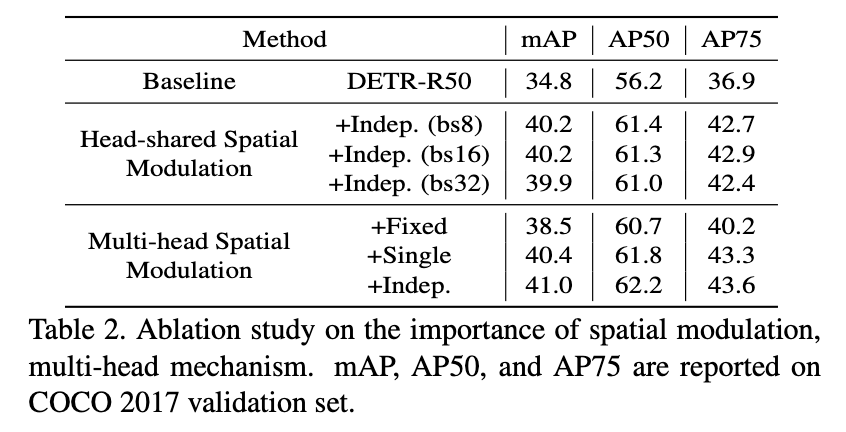
spatial modulation 할때 single head vs. multi-head
+Fixed - scale 을 1로 고정
+Single - h, w 에 대한 scale을 공통으로 하나만 predict
+Indep - h, w 에 대한 scale을 각각 predict

intra-scale, multi-scale self-attention 에 대한 ablation study
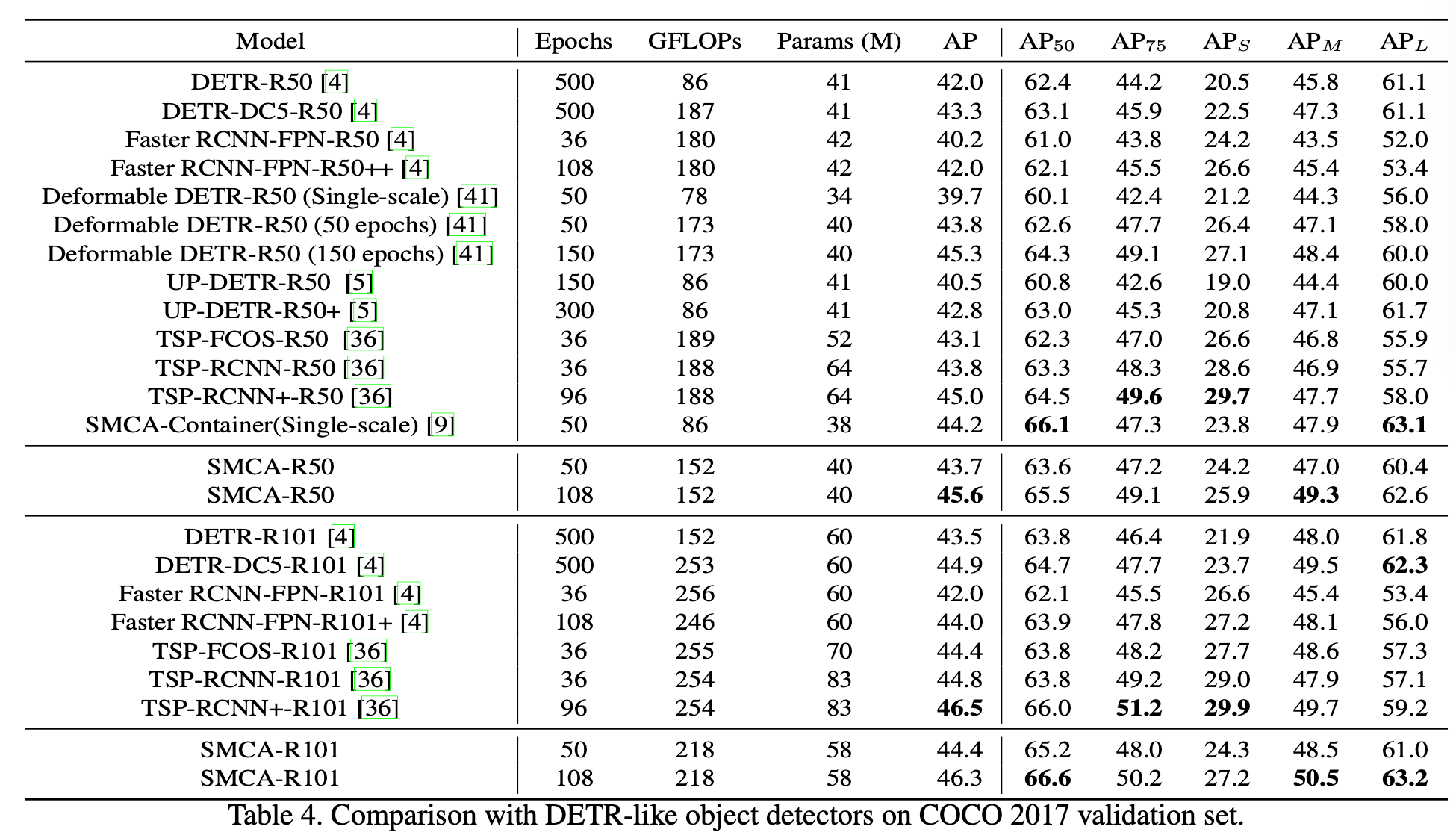
COCO 데이터셋에 대해서 기존 방법들과의 비교