Rethinking Transformer-based Set Prediction for Object Detection
Rethinking Transformer-based Set Prediction for Object Detection
ICCV 2021 , 2024-04-04 기준 306회 인용
Task
- Object Detection
Contributions
- DETR 이 왜 학습 속도가 느린지 분석, DETR 학습 속도 관련 분석
- FCOS 와 Faster RCNN에 Transformer Encoder 만 사용하여 set prediction 하는 방법 제안
Motivation
What Causes the Slow Convergence of DETR?
Bipartite Matching
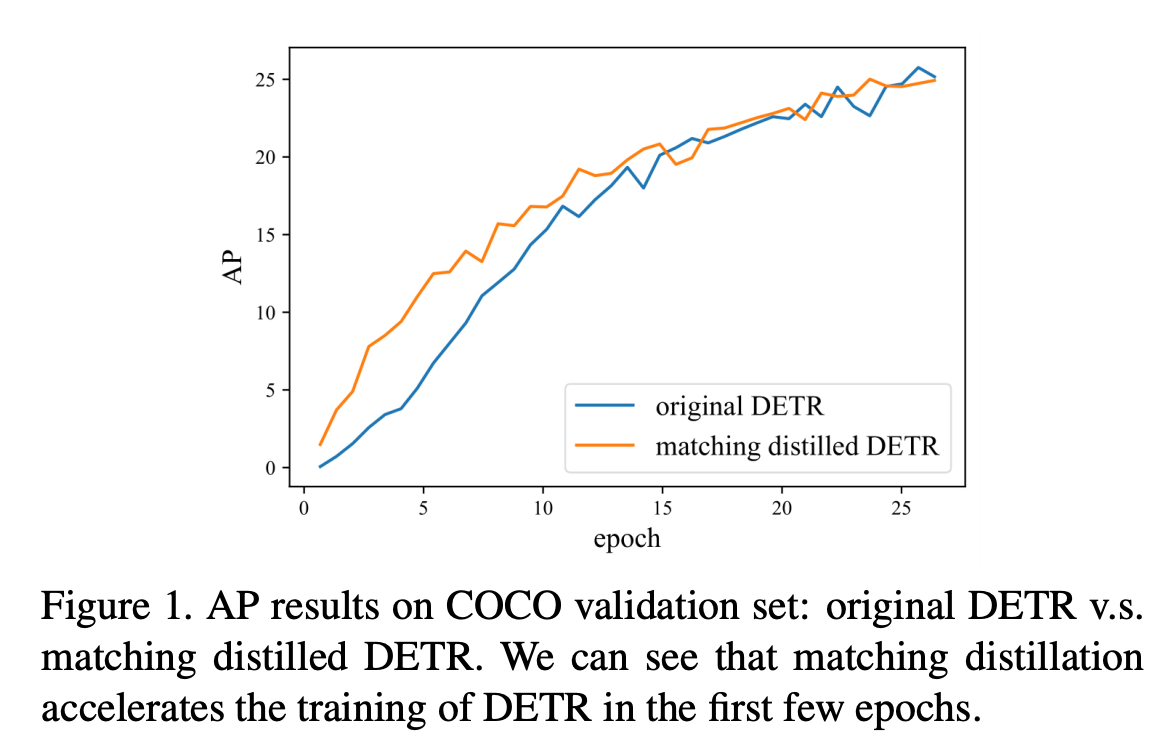
학습 초반 initialization of the bipartite matching 이 랜덤 → 학습 속도를 저하시킬 것이다
분석을 위해서 matching distillation 학습 방법을 제안
사전에 잘 학습된 DETR 을 Teacher 로 사용 label assignment 얻기
Teacher model 로 부터 얻어진 label assignment 로 matching 해서 학습
- 저자들은 일반 DETR 보다 학습초기에 빠르게 학습된다고 주장
- 당연히 사전에 학습된 DETR 정보가 들어가서 그런건 아닌지..? → 문제를 더 쉽게 세팅한 것이기 때문
- 하지만 15epoch 이후 비슷한 경향성을 보이기 때문에 주요한 요인은 아니라고 설명
Attention modules
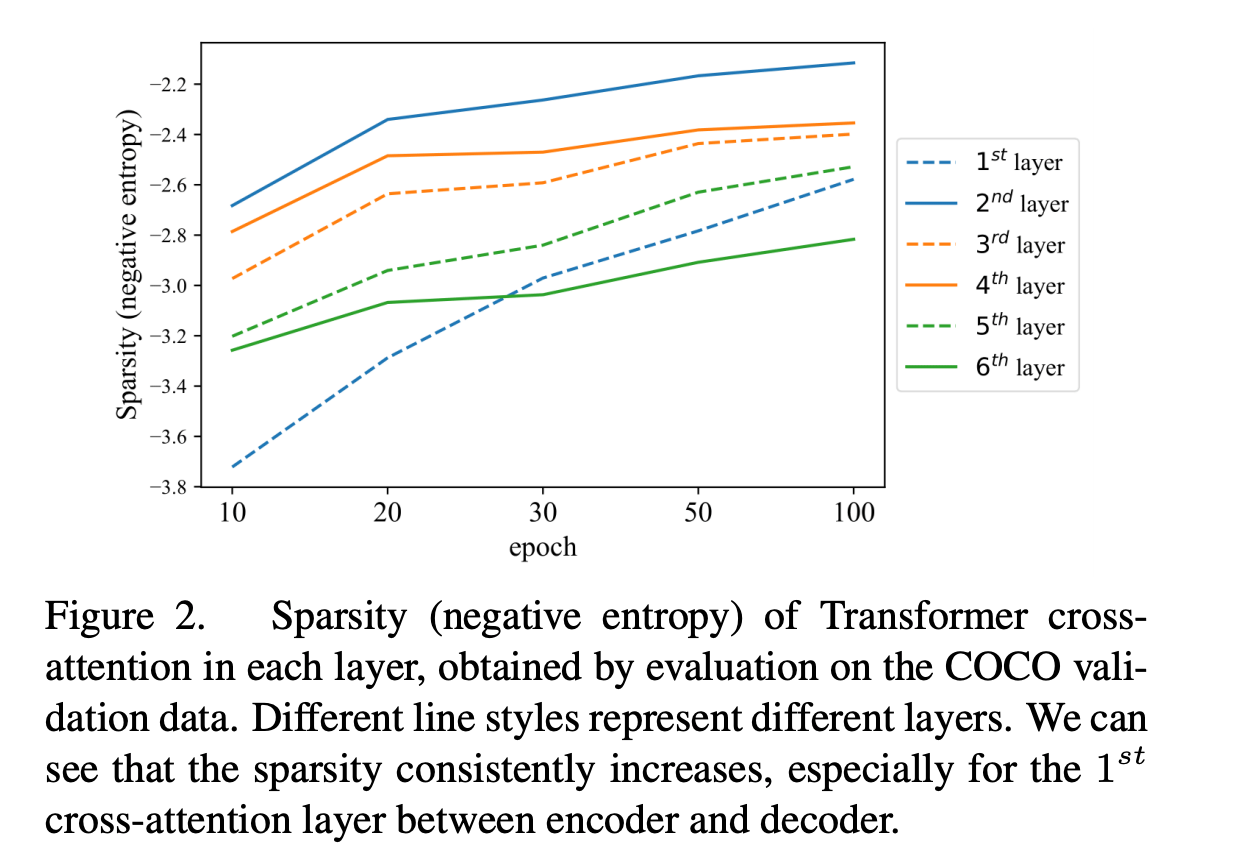
$\frac{1}{m} \sum_{j=1}^{m} P(a_{i,j}) \log P(a_{i,j})$
Encoder 와 Decoder Cross Attention 하는 layer 분석
각 layer 마다 attention score를 활용
source position i to target position j 에 대한 attention score의 평균
Sparsity (negative entropy) 가 모든 layer에서 학습이 진행되도 향상 → 이 결과는 cross attention이 느린 학습속도를 야기시킨다고 설명
Remove Transformer Decoder
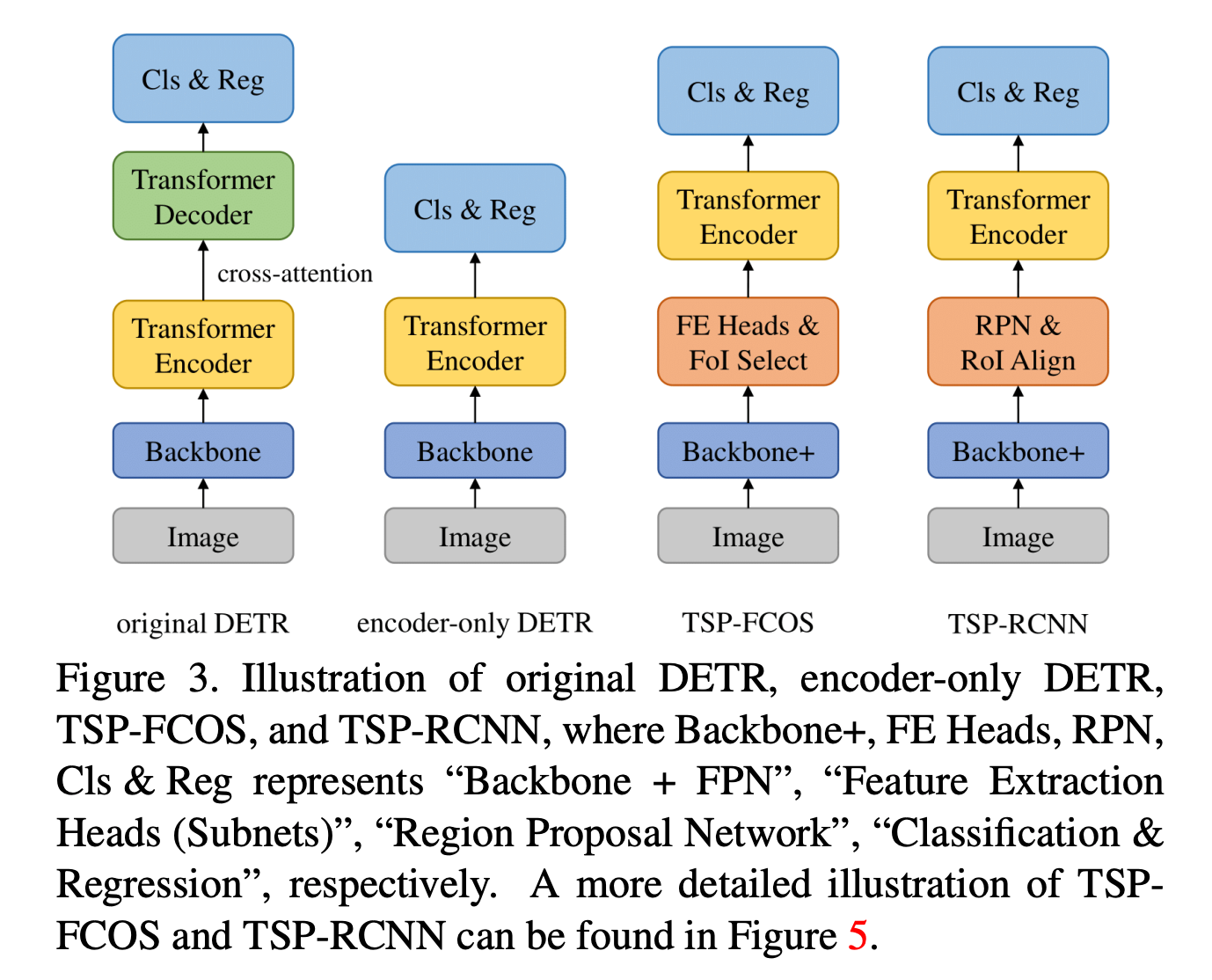
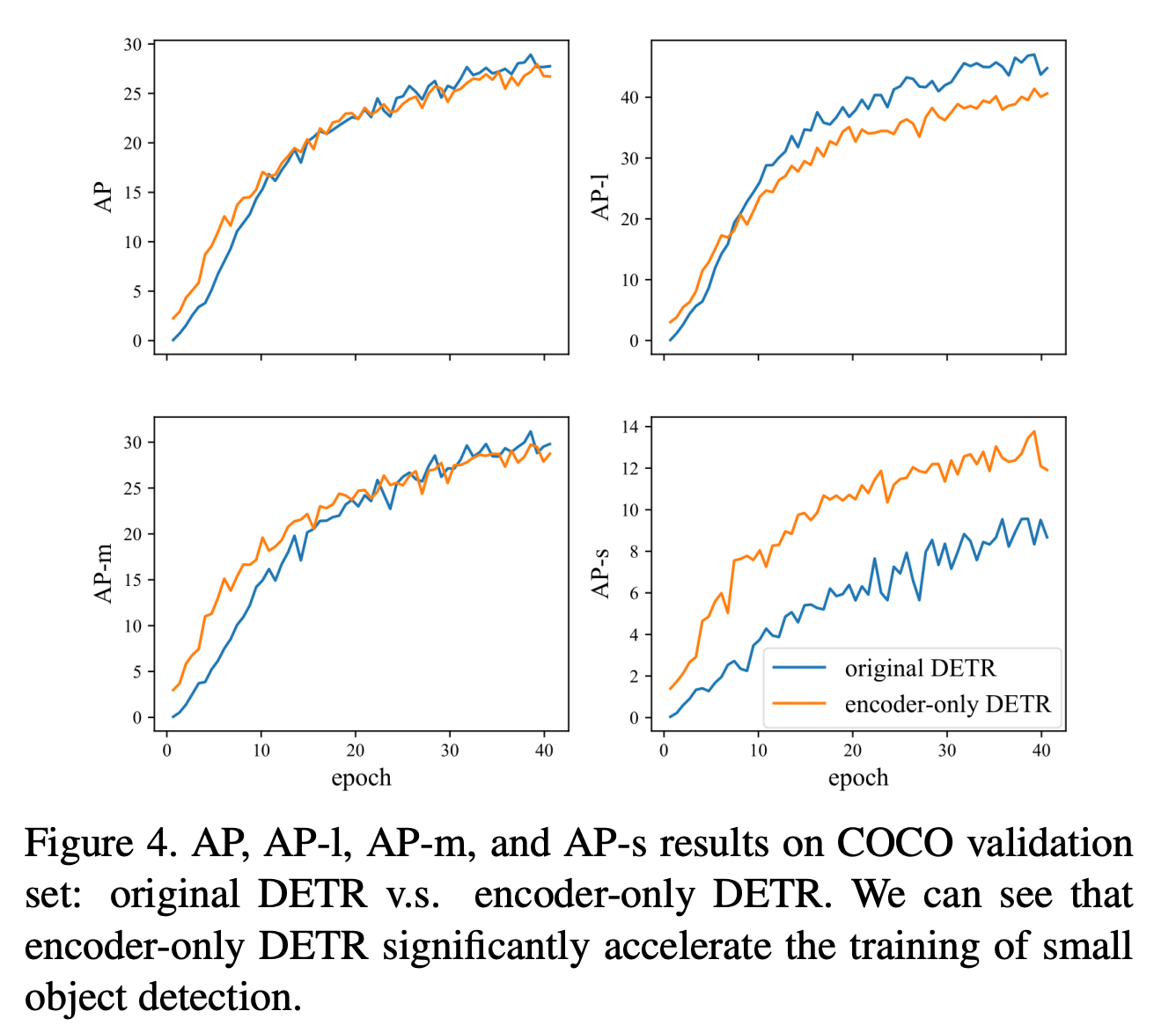
Encoder 만 사용해도 성능이 비슷하다고 설명
Large object 에 대한 성능은 하락 → FPN (Feature Pyramid Network) 로 해결하겠다고 함
Proposed Method
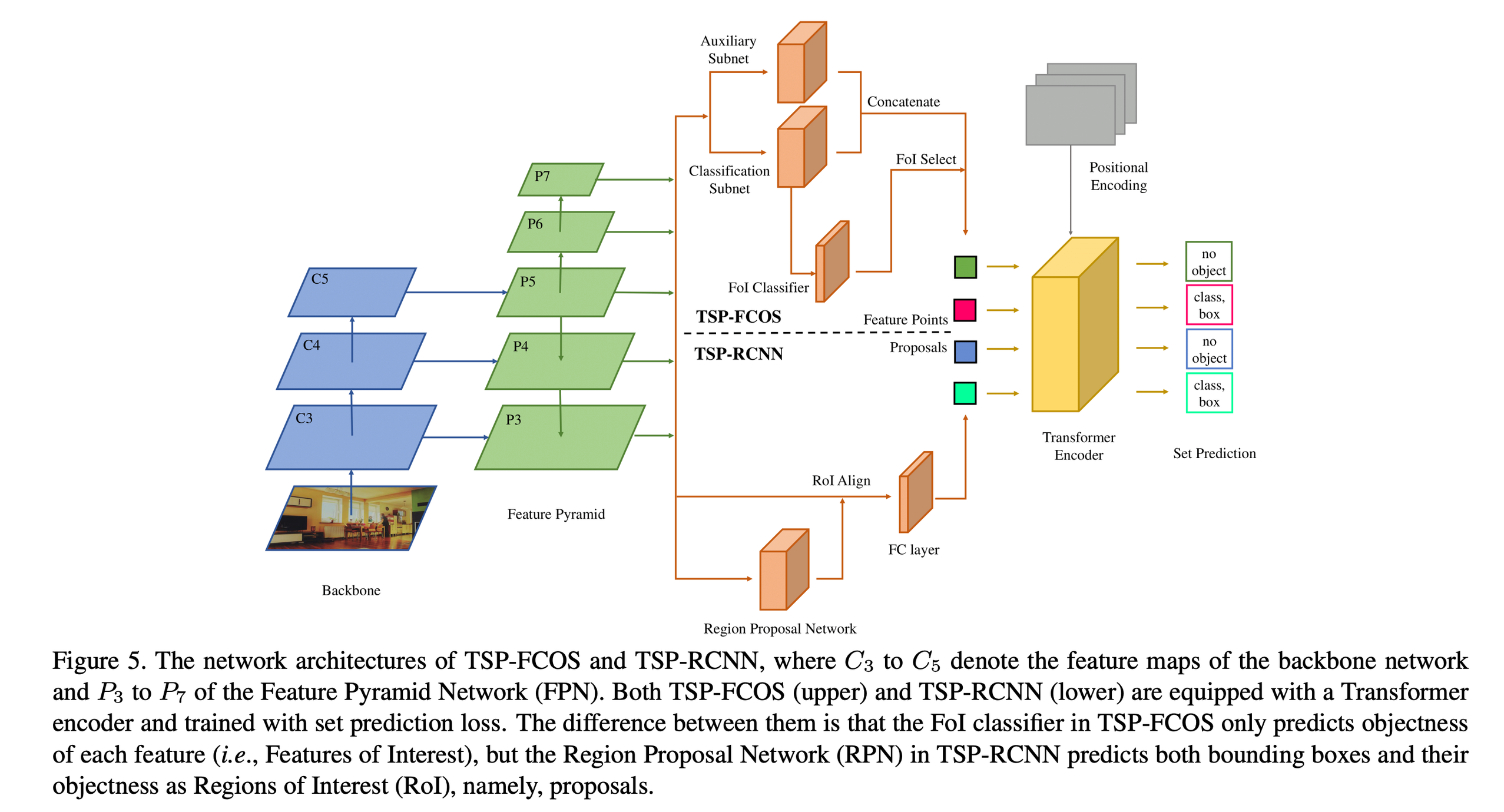
TSP - Transformer-based Set Prediction
TSP-FCOS
FoI(Feature of Interest) Classifier
- FCOS ground truth assignment rule
- object 안에만 있는 애들만 쓰겠다는 취지
- 여러 Feature point에 대해서 Encoder 입력으로 사용시 연산비용 향상되기 때문
- FoI Classifier 를 통해서 해당 feature point 가 ground truth box 안에 있는지 없는지 예측
- Top 700개 선택
Set prediction training
해당 Feature point 가 bounding box 안에 있을 경우에만 assign
TSP-RCNN
classification score top 700개를 FPN 결과중에서 선택
Set prediction training - IoU 가 0.5 넘는 애들만 사용
Experimental Results
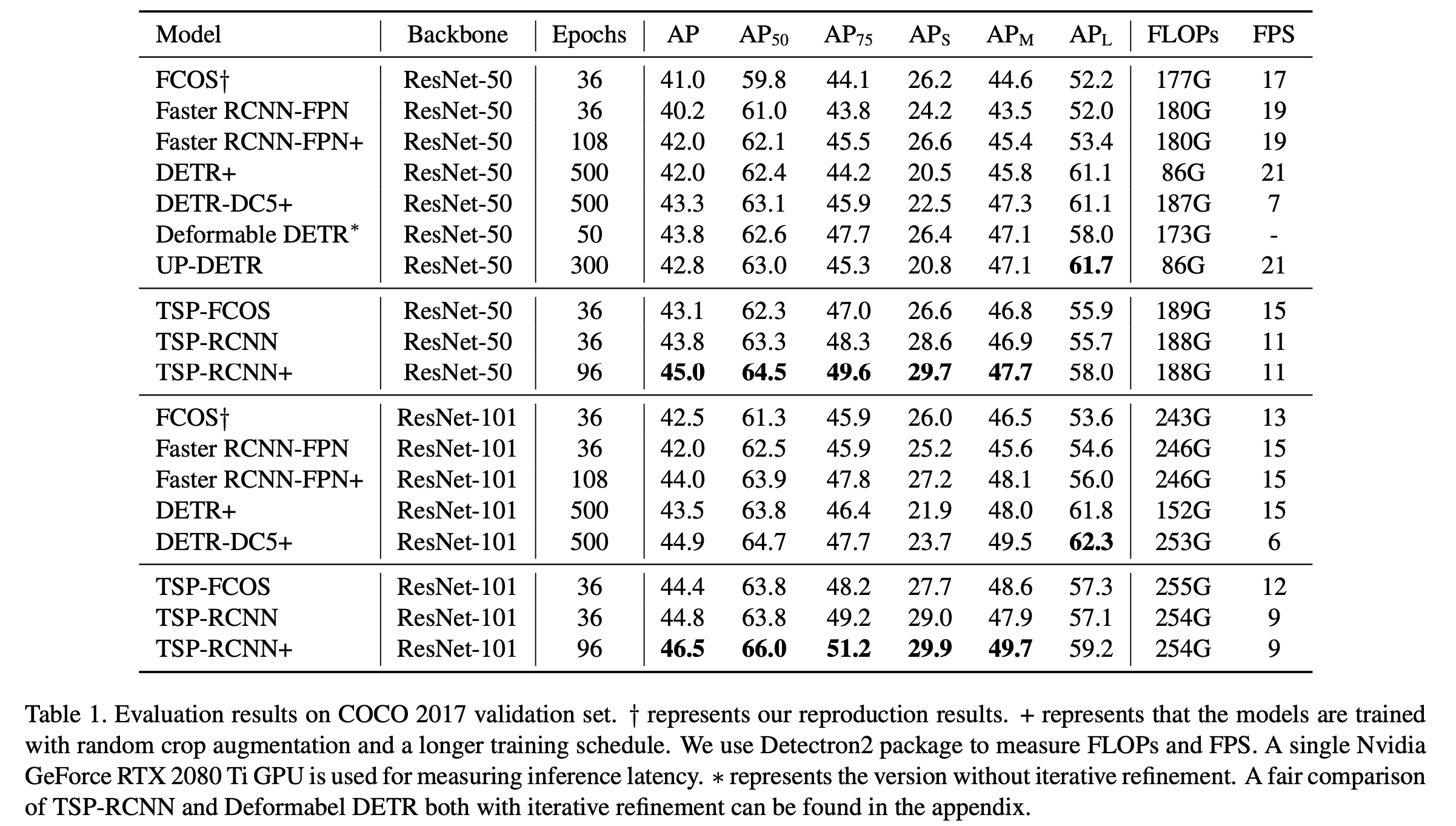
기존 방법들보다 좋은 결과를 보여준다