ProMix: Combating Label Noise via Maximizing Clean Sample Utility
ProMix: Combating Label Noise via Maximizing Clean Sample Utility
IJCAI 2023, 2024-03-25 기준 22회 인용
Task
- Learning with Noisy Labels
- Semi-Supervised Learning
Contributions
- Progressive Sample Selection - Clean data 를 고르는 방법을 제안
- Debiased Semi-Supervised Training - nosiy data 를 활용해서 성능을 향상시키는 방법을 제안
- SOTA 성능 달성
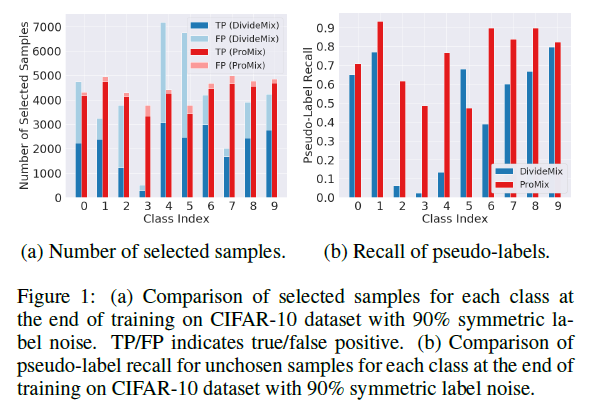
기존의 방법은 selected sampes 에 대한 TP, FP 가 낮다
제안하는 방법 ProMix 는 향상된 값을 보여준다
unchosen samples 의 pseudo-labels 에 대한 recall 을 보았을 때도 기존의 방법보다 향상되었다
Proposed Method
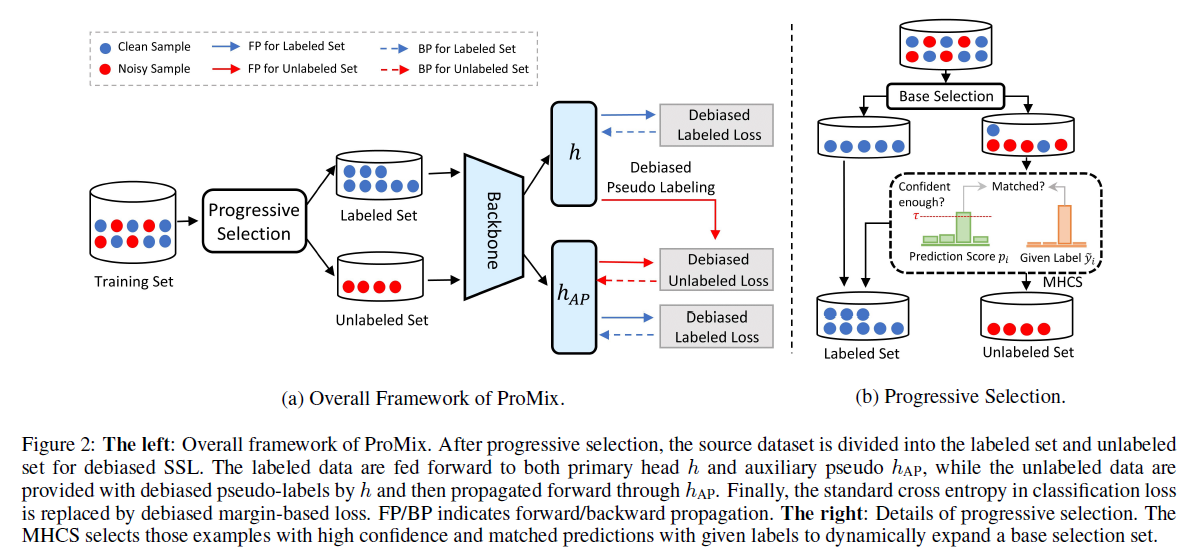
제안하는 ProMix 의 Overview
Progressive Sample Selection
Class-wise Small-loss Selection (CSS)
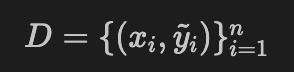
전체 데이터셋 $D$ 에 대해서 class $C$ 로 split
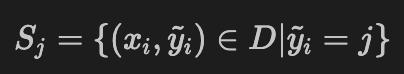
각 set 별로 CE loss 를 계산하고 값이 가장 작은 $k$ 개를 선택
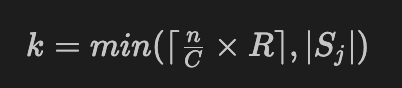
전체 samples 수와 class 개수에 따른 값과 filter rate $R$ 로 $k$ 조절

각 class 마다 $k$ 개씩 selection 을 한것을 모두 합친 것
Matched High Confidence Selection (MHCS)
make capital out of the potentially clean samples missed by CSS
CSS 에서 놓친 clean samples 를 고르기 위해
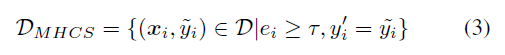
confidence score 값이 threshold 보다 높고 label 이 일치하는 경우
clean data set
$D_{l} = D_{CSS} \bigcup D_{MHCS}$
Debiased Semi-Supervised Training
utilizes the remaining noisy samples to boost performance
남은 noisy data 를 활용하기 위한 방법
Mitigating Confirmation Bias
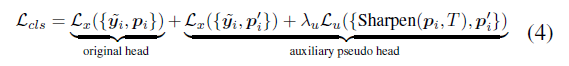
confirmation bias 를 완화시키는 것이 목적
기존의 original head 와 별도의 auxiliary head Auxiliary Pseudo Head (APH) 를 설계
기존 head 는 clean data 에 대한 CE 만
APH 에는 noisy data 로 unsupervised learning
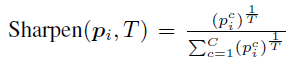
backbone benefits from the unlabeled data for enhanced representation
unlabeled data 를 보게됨으로써 backbone 의 representation 이 강화
confirmation bias 도 완화
Training 과정에만 사용됨으로써 inference time 에는 영향 X
Mitigating Distribution Bias
pseudo-labels can naturally bias towards some easy classes
easy classes 에 bias 되는 경향이 있다
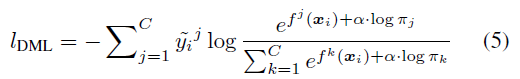
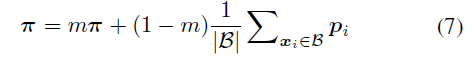
encourage a larger margin between the sample-rich classes and the sample-deficient classes
샘플이 풍부한 클래스와 부족한 클래스에 대해서 margin 을 두도록 설계
distribution 은 moving average 로 구성됨

pseudo-label calibrate 를 위해서 class distribution 으로 easy class 에 대한 부분을 suppress
Practical Implementation
Label Guessing by Agreement (LGA)
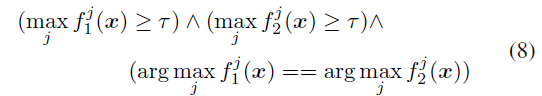
두 가지 모델을 두고 threshold 값을 넘으면서 두 모델 다 같은 label 을 예측했을 때 clean data 로 활용
Training Objective

consistency regularization 과 mixup augmentation loss 추가
Experimental Results
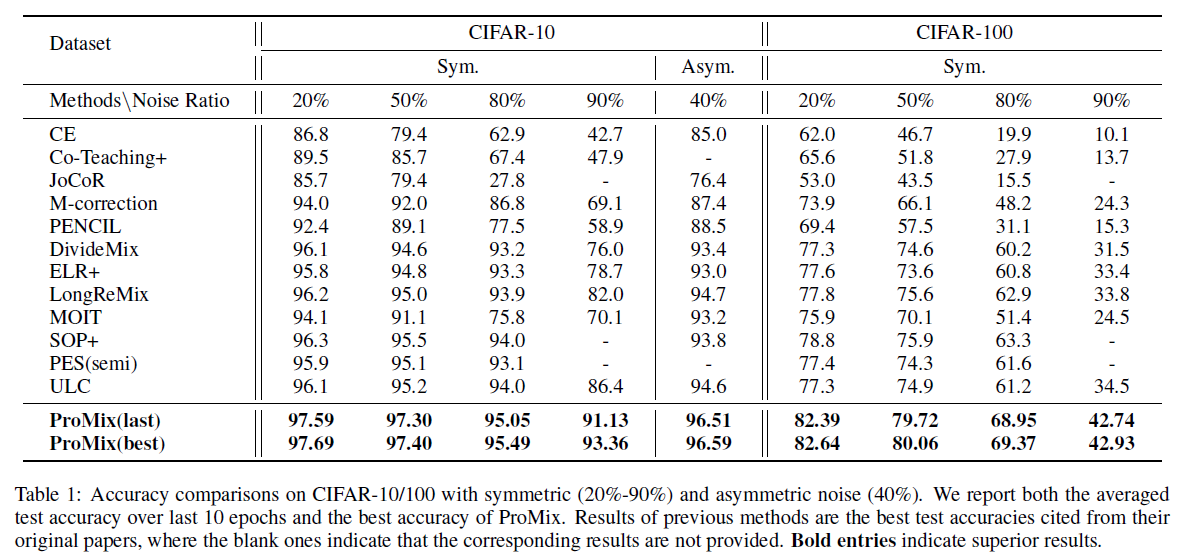
CIFAR-10/100 에서의 실험 결과
모든 setting 에서 ProMix 가 SOTA 성능을 보여준다

Clothing 1M datasets 에 대한 실험 결과
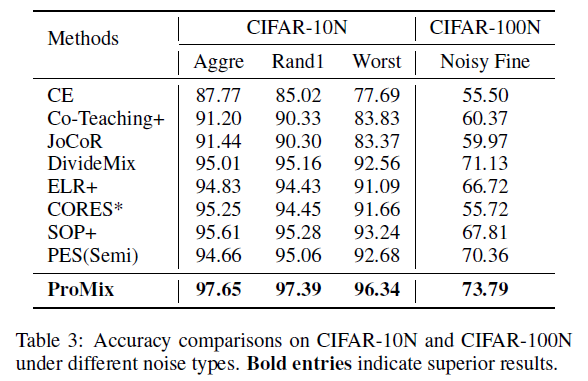
여러 세팅에 대한 실험 결과
Aggregate, Rand1, and Worst label annotations
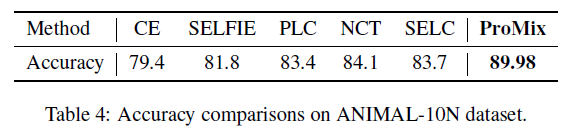
ANIMAL-10N 데이터셋에 대한 실험 결과
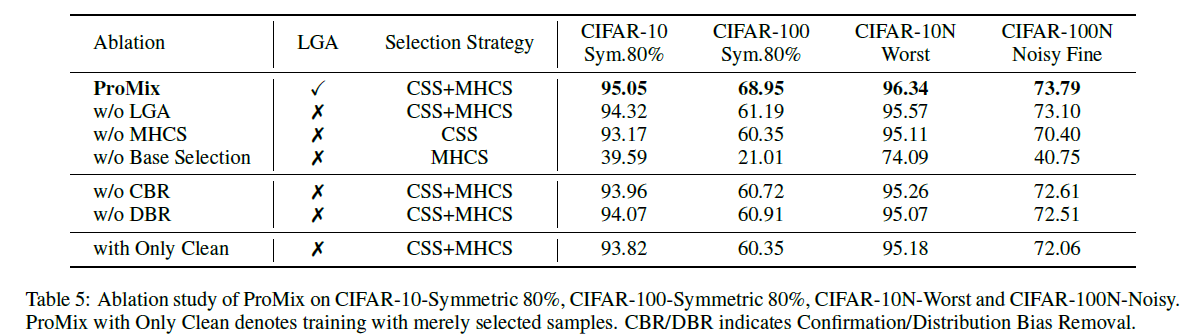
Ablation Study
CBR - Confirmation Bias Removal
DBR - Distribution Bias Removal
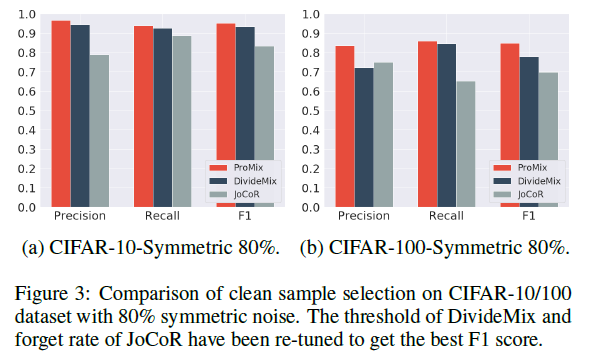
clean sample selection 에 대한 실험 결과
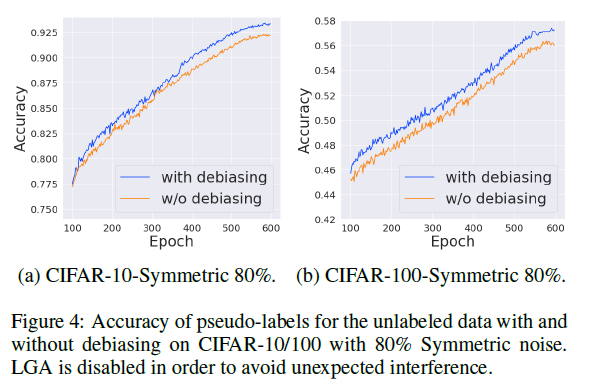
Debiasing 에 대한 ablation study