DETR Does Not Need Multi-Scale or Locality Design
DETR Does Not Need Multi-Scale or Locality Design
ICCV 2023, 2024-04-15 기준 6회 인용
Task
- Object Detection
- DETR
Contribution
- 최근 많은 DETR 기반 방법들에서 사용하고 있는 multi-scale 방법과 Locality constraint 방법들이 필요없다
- single scale feature 만 사용하는 Improved “Plane“ DETR 방법을 제안
- Masked image modeling (MIM) -based backbone network 사용
- Box-to-pixel relative position bias (BoxRPB) 제안
Proposed Method
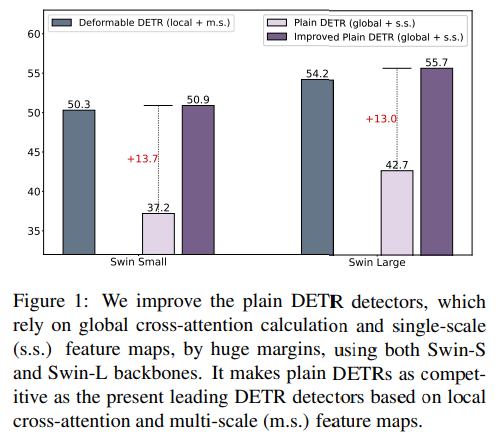
기존 DETR 에 비해 큰 향상을 보여줌
multi-scale 과 locality design 을 사용하는 deformable detr 에 비해서도 향상됨
Enhanced Plain DETR baseline
기존의 여러 DETR 기반 연구들에서 제안된 기법들을 적용

MTE - Merging Transformer encoder into the backbone
FL - Focal Loss
IR - Iterative refinement
TS - Two-stage
LFT - Look forward twice → DINO
MQS - Mixed query selection → DINO
HM - Hybrid matching
Box-to-Pixel Relative Position Bias
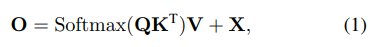
기존 DETR 의 cross-attention 연산 과정
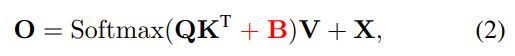
Relative Position Bias (RPB) 를 추가
일반 RPB 와 다른점은 box 정보를 활용
Naive BoxRPB implementation
left-top, right-bottom 과의 relative position 사용
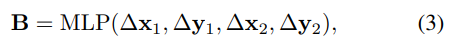
K x H x W x 4 → K x H x W x 256 → K x H x W x M
M = number of attention head
Decomposed BoxRPB implementation
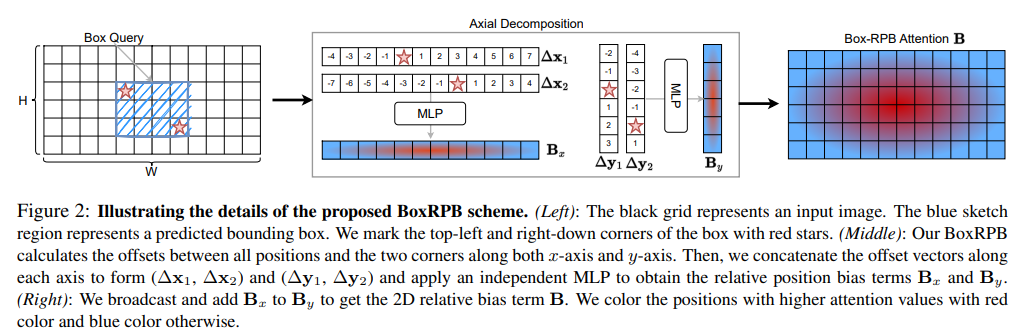
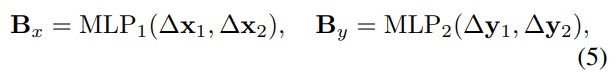
연산 효율을 위해서 x, y 를 따로 진행
K x W x 2 → K x W x 256 → K x W x M
K x H x 2 → K x H x 256 → K x H x M
Masked image modeling (MIM) pre-training
Masked image modeling 방법중 SimMIM pre-trained weights를 사용
Swin-Transformer 사용
Bounding box regression with re-parameterization
기존의 DETR 학습방식은 large objects가 loss에 주는 영향이 큼
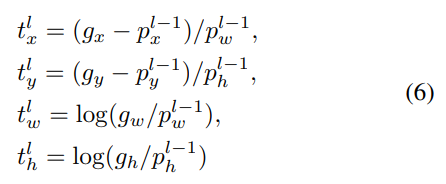
$l-1$ decoder layer의 예측된 bounding box 정보를 활용해서 re-parameterization
Experimental Results
다른 방법들과 비교하기보단 Ablation study 로 각각의 방법의 효과를 입증하는 방향
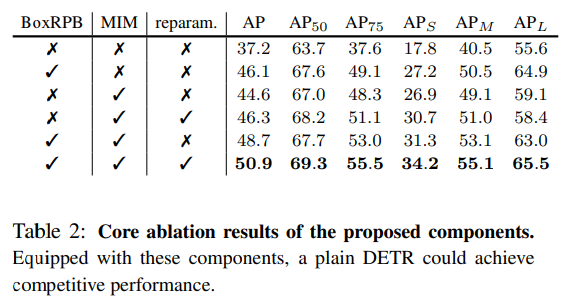
BoxRPB, MIM, parameterization 에 대한 ablation study
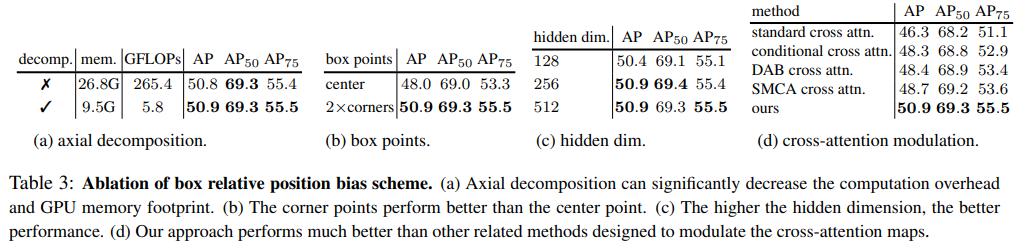
box relative position bias 에 대한 ablation study

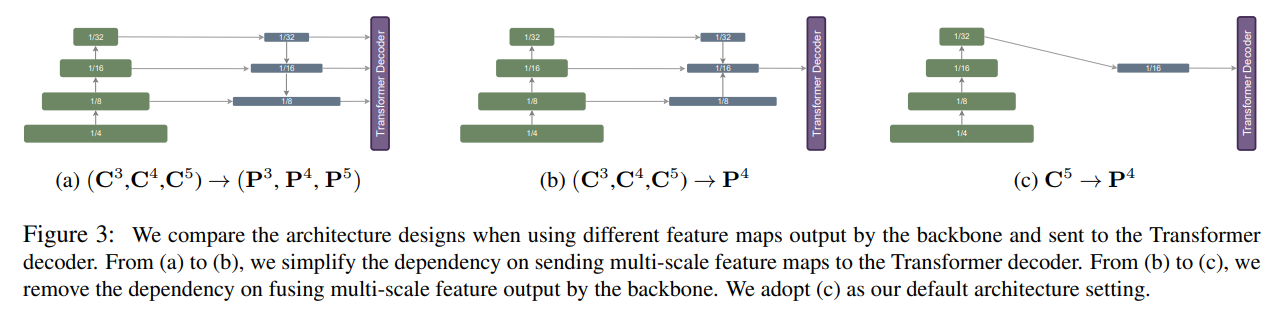
MIM pre-training 에 대한 ablation study