Multi-modal Queried Object Detection in the Wild
Multi-modal Queried Object Detection in the Wild
NeurIPS 2023, 2024-03-18 기준 6회 인용
Task
- Object Detection
- Multi-modal
Contributions
- Vision-language (VL) detection foundation models 에서 multi-modal queries 를 사용하는 구조 제안
- Multi-modal Queried object Detection (MQ-Det) 제안
- Gated Class-scalable Perceiver (GCP) 모듈을 제안
- Paving a new path to the object detection in the wild
Proposed Method
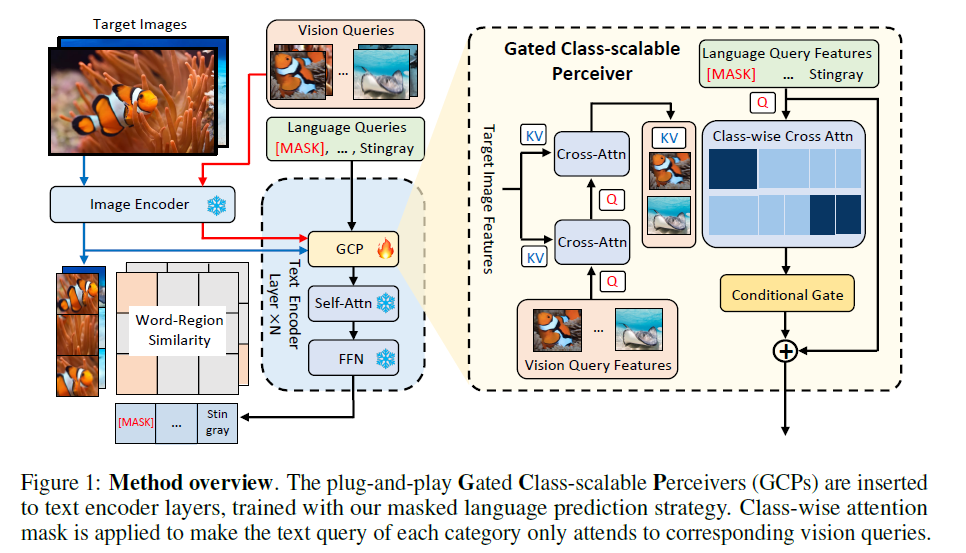
제안하는 방법의 overview
Language-queried detection model (GLIP)

GLIP 을 baseline 으로 하고 있다
Architecture design
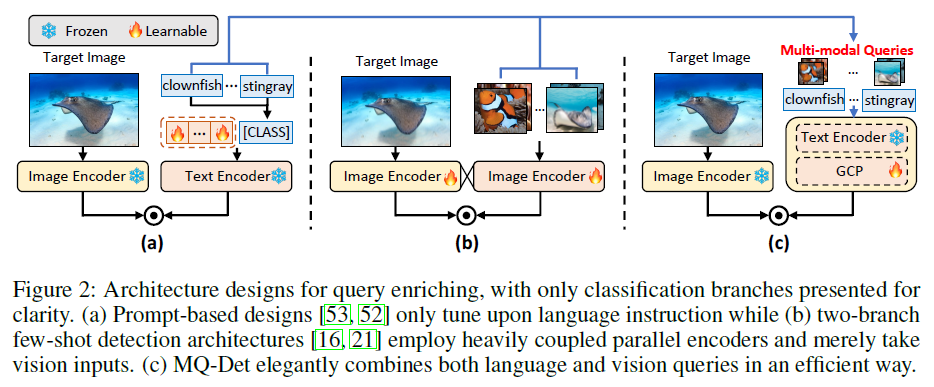
(a) - Prompt-based desings (e.g., CoOp)
(b) - two-branch few-shot detection architectures (e.g., FCT)
(c) - 본 논문에서는 (a), (b) 에 대하는 것을 모두 가져가겠다
Gated Class-scalable Perceiver (GCP)
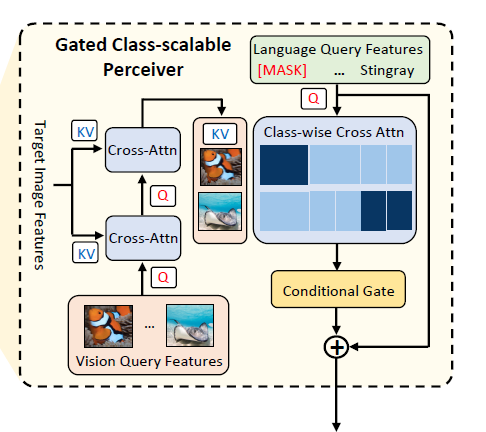
visual queries 정보와 text queries 의 정보간 관계를 파악

categories $C$ 마다 $k$ exemplars 를 통해서 visual queries 를 생성
visual queries 를 Image Encoder 통과시킨 feature 를 query 로 사용
Image 전체가 Iamge Encoder 를 통과시킨 feature 를 key, value
그 다음에 text feature 를 query, 위에서 연산된 visual feature 를 key, value
Cross-Attention -> text token에 따른 multi views 효과
Conditional Gate
three-layer perceptron (MLP) 으로 learnable scalar 생성
$\hat v_i$ 로 부터 구해서 $\hat v_i$ 에 곱해주고 원래 text feature 에 더해준다
Modulated pre-training
Vision query extraction

각 category 별로 $K$ 개의 vision queries 를 bank $D$ 에 저장
each forward process 마다 $k$ 개 random select
$K = 5000, k =5$
Training upon frozen pre-trained language-queried detectors
Full model 을 학습할 경우 catastrophic forgetting 문제가 발생
full-model training on a limited number of categories faces the risk of catastrophic forgetting
Vision conditioned masked language prediction
gated architecture will rapidly converge around the initial optimum point
visual queries 의 영향이 크지 않고 결국 initial optimum point 로 돌아갈 것이다
-> 나머지들이 fix 되어 있기 때문에
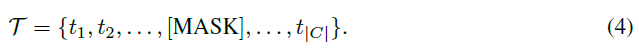
text queries 중에서 random 으로 [MASK] 처리
mask 처리된 곳이 visual queries 의 영향을 크게 맞으면서 학습될 것이다
Experimental Results
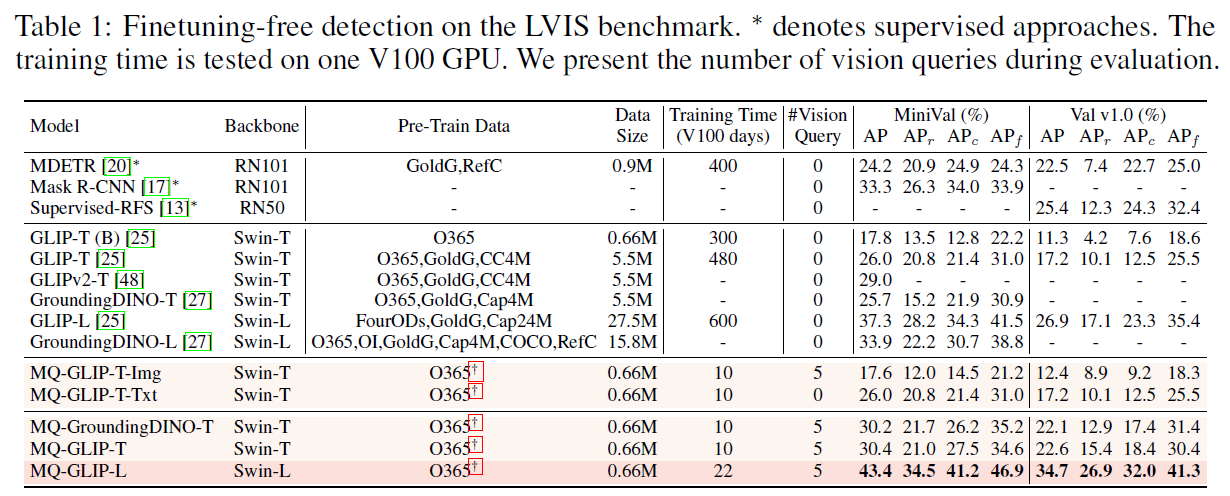
MQ-GLIP-T-Img 는 query 로 visual query 만 역할하도록 설계
Text queries 를 모두 [MASK] 로 처리