MS-DETR: Efficient DETR Training with Mixed Supervision
MS-DETR: Efficient DETR Training with Mixed Supervision
arXiv 2024.01, 2024-03-05 기준 0회 인용
Jingdong Wang (바이두) 저자 - GroupPose, Conditional-DETR, Group-DETR
Task
- Object Detection
- DETR
Contributions
- one-to-one Supervision 과 one-to-many 를 혼합해서 사용하는 구조 제안
- Decoder layer 에서 self-attention layer 와 cross-attention layer 순서를 바꾸는 것을 제안
- 여러 DETR 방법론들에 제안하는 구조를 적용했을 때 성능 향상

Top-20 의 Queries 결과들을 보았을 때 제안하는 방법을 사용했을 때 더 좋은 결과를 보여준다
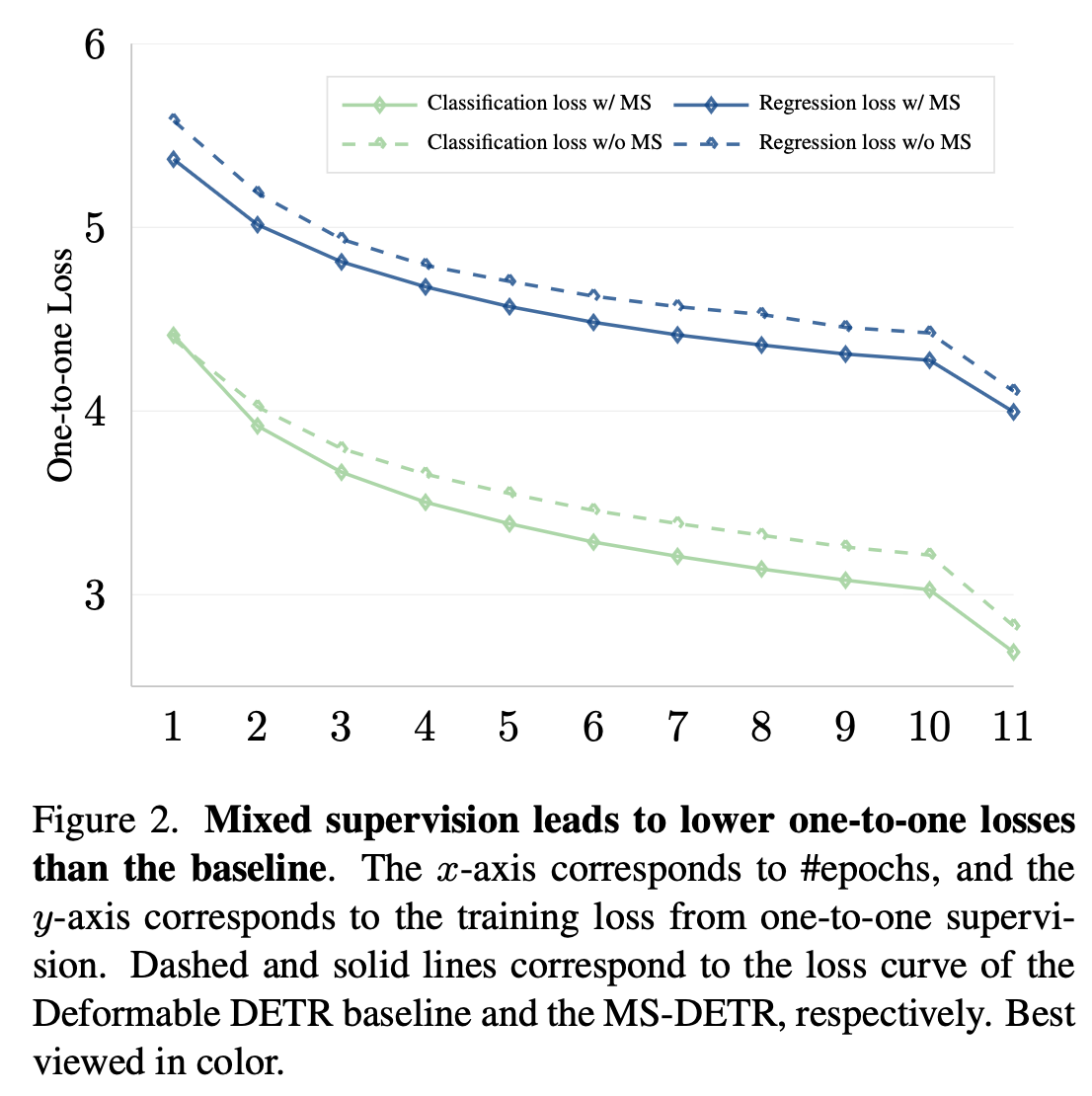
제안하는 방법을 적용했을 때 one-to-one Loss 가 더 낮게 학습된다
Motivation
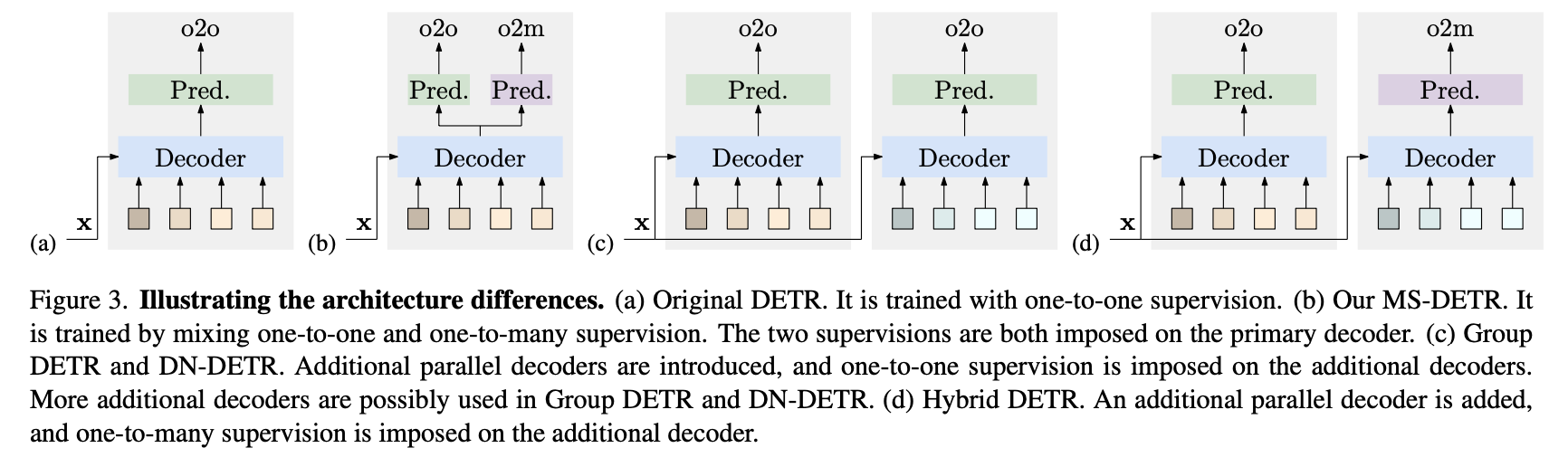
(a) - Original DETR
(b) - MS-DETR
(c) - Group DETR, DN-DETR
(d) - Hybird DETR
(c), (d) 같은 경우에는 추가적인 Queries 혹은 decoder branch 가 필요하다
one-to-many supervision 영향을 Queries 에 직접적으로 주고 싶다
Proposed Method
One-to-one supervision

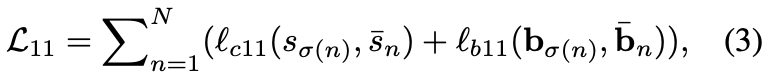
일반적인 DETR 에서의 one-to-one supervision 학습
One-to-many supervision
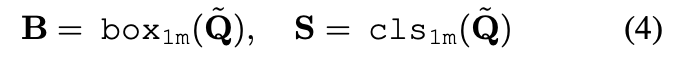
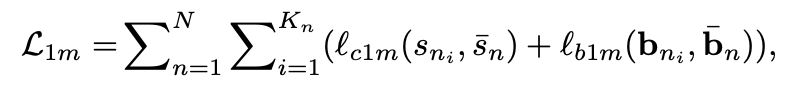
여러 쿼리들을 GT와 Matching 하여 Loss 계산
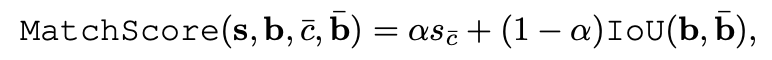
MatchScore 라는 것을 통해서 GT와 쿼리와 매칭
classification score 와 GT 와의 IoU 활용
top K 를 선정하고 matching score 가 threshold 값을 넘을때만 매칭
Implementations
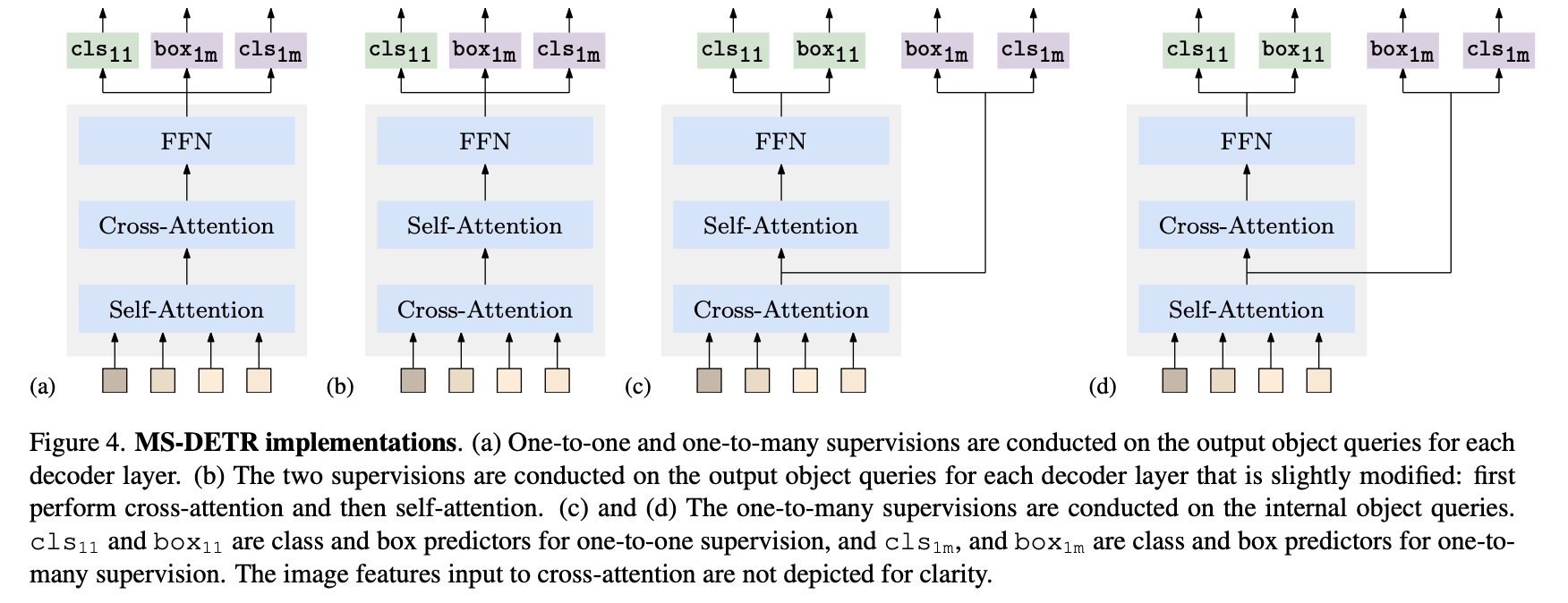
(a) - one-to-one (classification), one-to-many (classification, box)

(b) - self-attenion layer 와 cross-attention layer 위치 변경
cross-attention is to generate multiple candidates according to image features
cross-attention layer는 image feature 와의 관계를 파악하면서 multiple candidates 를 생성
self-attention is to collect the information of other candidates for duplicate removal
self-atteniont layer 는 candidates 와 관계를 파악하면서 중복되는 것을 제거
-> (b) 구조로는 유의미한 성능 향상 x
(c) - cross-attention layer 의 결과에 one-to-many supervision 추가
(d) - self-attention layer 의 결과에 one-to-many supervision 추가
(c) 에서 성능 향상, (d) 에서는 성능 하락
cross-attention layer 가 mutilple candidates 를 만드는 역할이고 self-attention layer 가 mutiple candidates removal 역할이기 때문에 (b) 구조가 더 적합
Experimental Results
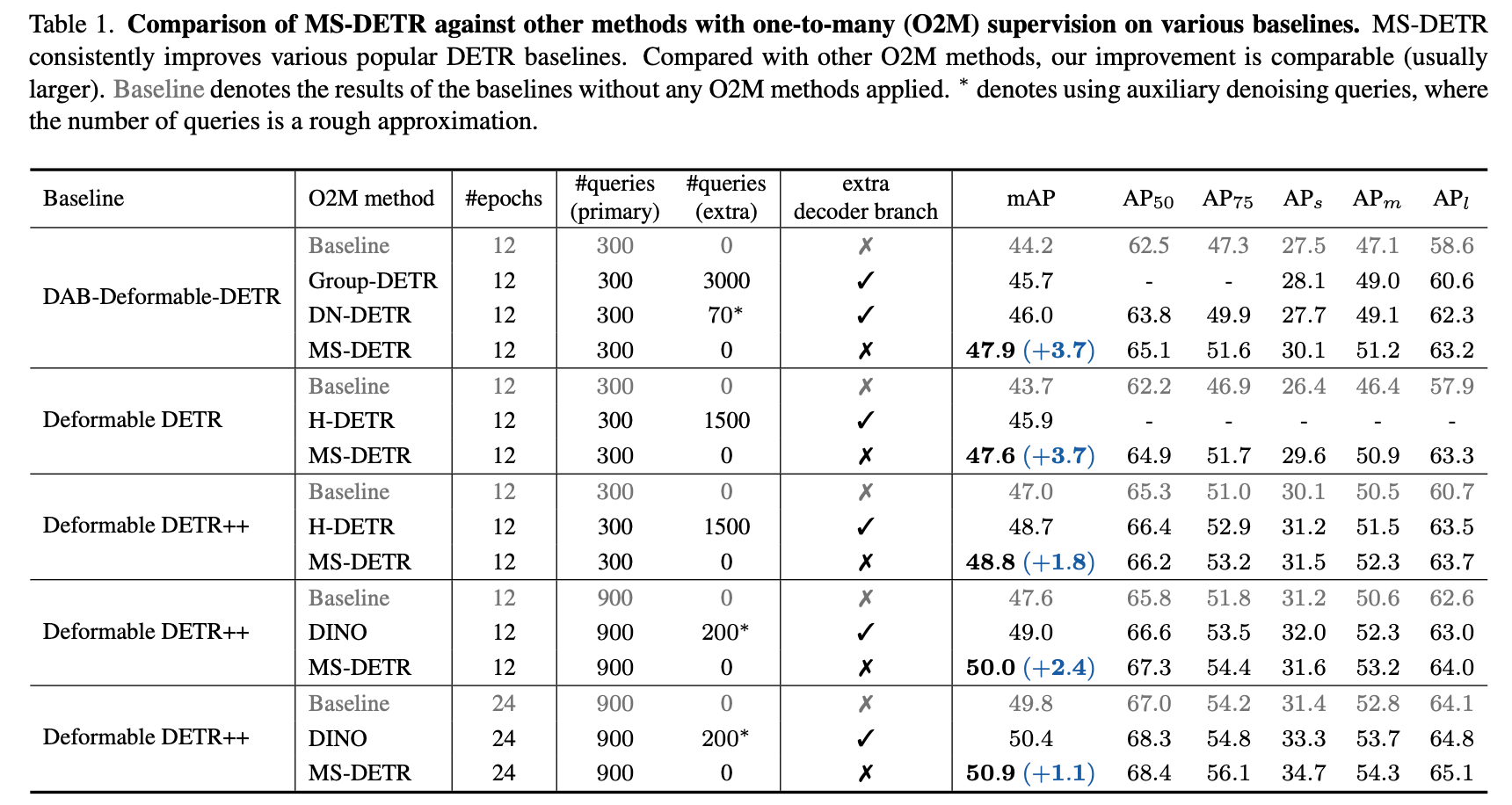
Deformable DETR ++
additional tricks: mixed query selection, look forward twice, and zero dropout rate
제안하는 방법을 Deformable DETR 에 적용했을 때 기존의 여러 DETR 방법들보다 성능 향상
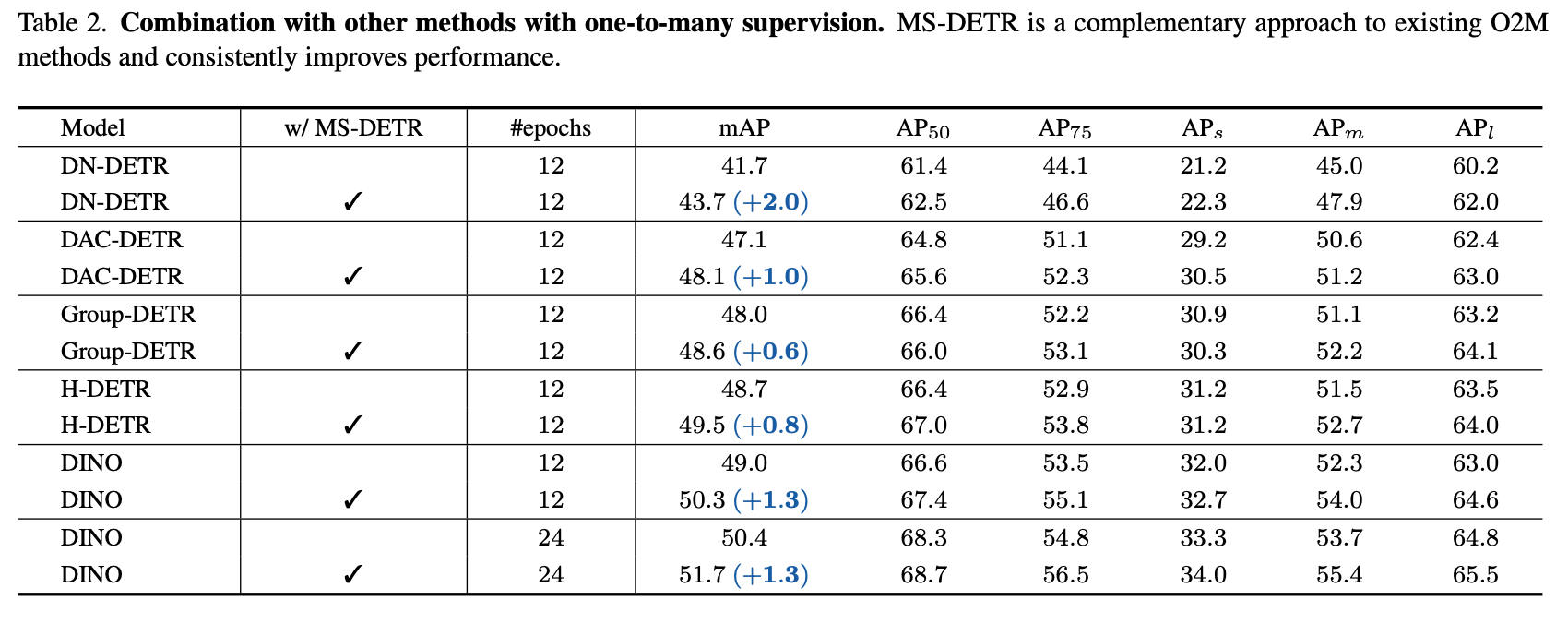
여러 DETR 에 적용했을 때 성능 향상

predictor 는 one-to-one 과 one-to-many 에 대해서 weights를 공유했을 때 제일 좋음

제안하는 방법이 더 좋은 candidates 들을 생성함