Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETR
Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETR
CVPR 2023, 2024-04-17 기준 26회 인용
Task
- Object Detection
- DETR
Contribution
- 기존의 방법들은 Encoder 에서 high computation cost를 갖고 있다
- Key-aware deformable attention 제안
- Interleaved update 방법 제안
- GFLOPs 를 60% 가량 줄이고 성능을 99% 만큼 지켜낼 수 있다
Motivation


DINO 를 기반으로 Backbone, Encoder, Decoder 의 GFLOPs를 분석
DINO-4scale 에서 low-level feature에 해당하는 scale의 token 비율이 매우 높다 (large-resolution feature map) - 75.3% 차지
DINO-4scale → DINO-3scale 으로만 해도 Encoder 부분의 GFLOPs가 크게 줄어든다
성능면에서는 S4(low-level feature)를 사용하지 않았을 때 small object 에 대한 성능이 하락
large object 에 대한 성능은 유사
-> can we use fewer feature scales but maintain important local details?
In this interleaved way, we update high-level and low-level features in different frequencies for efficient computation
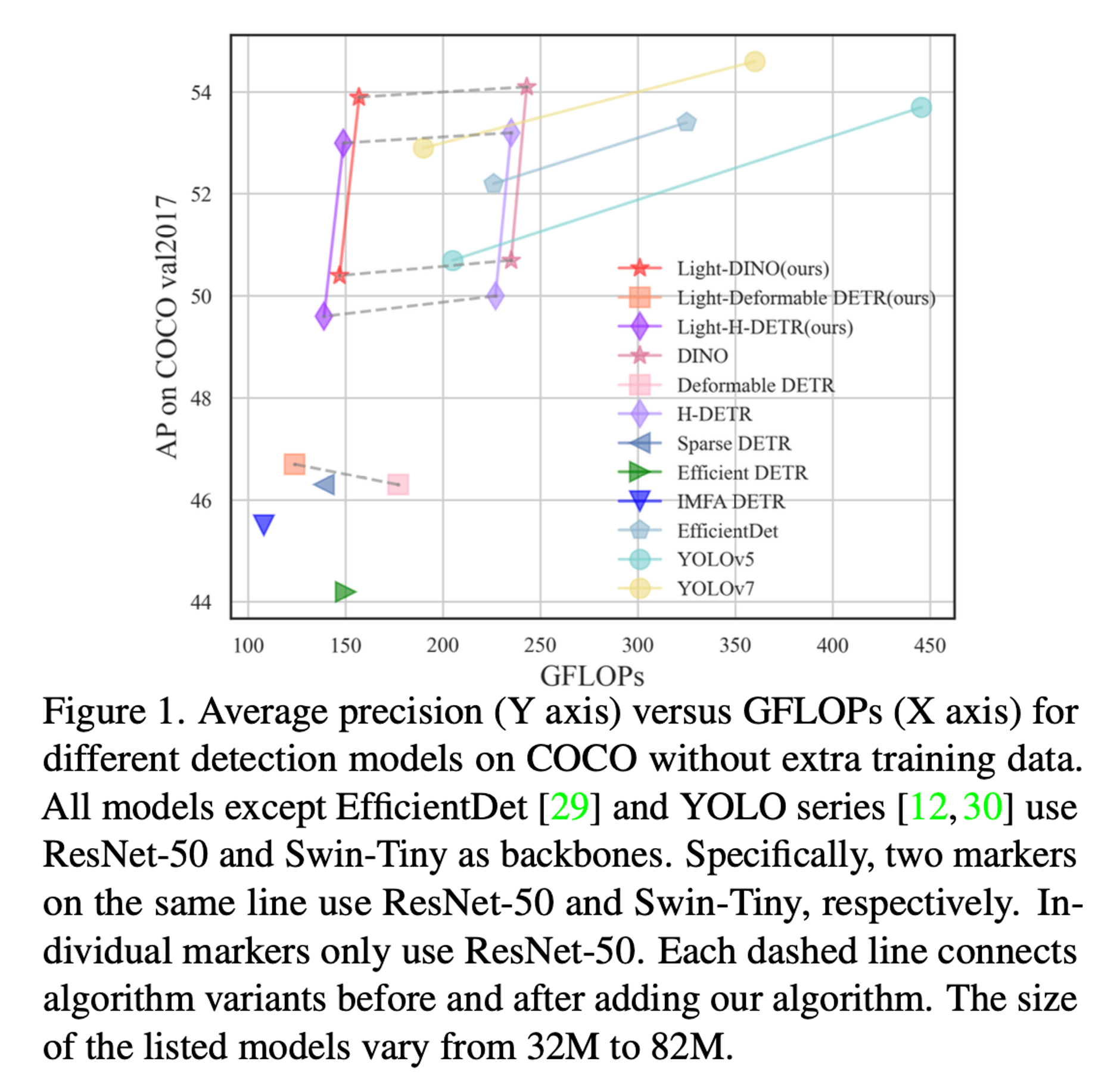
제안하는 방법을 DETER 기반 방법들에 적용하였을 때 성능은 유지하면서 GFLOPs 가 줄어드는 것을 확인할 수 있다
Proposed Method
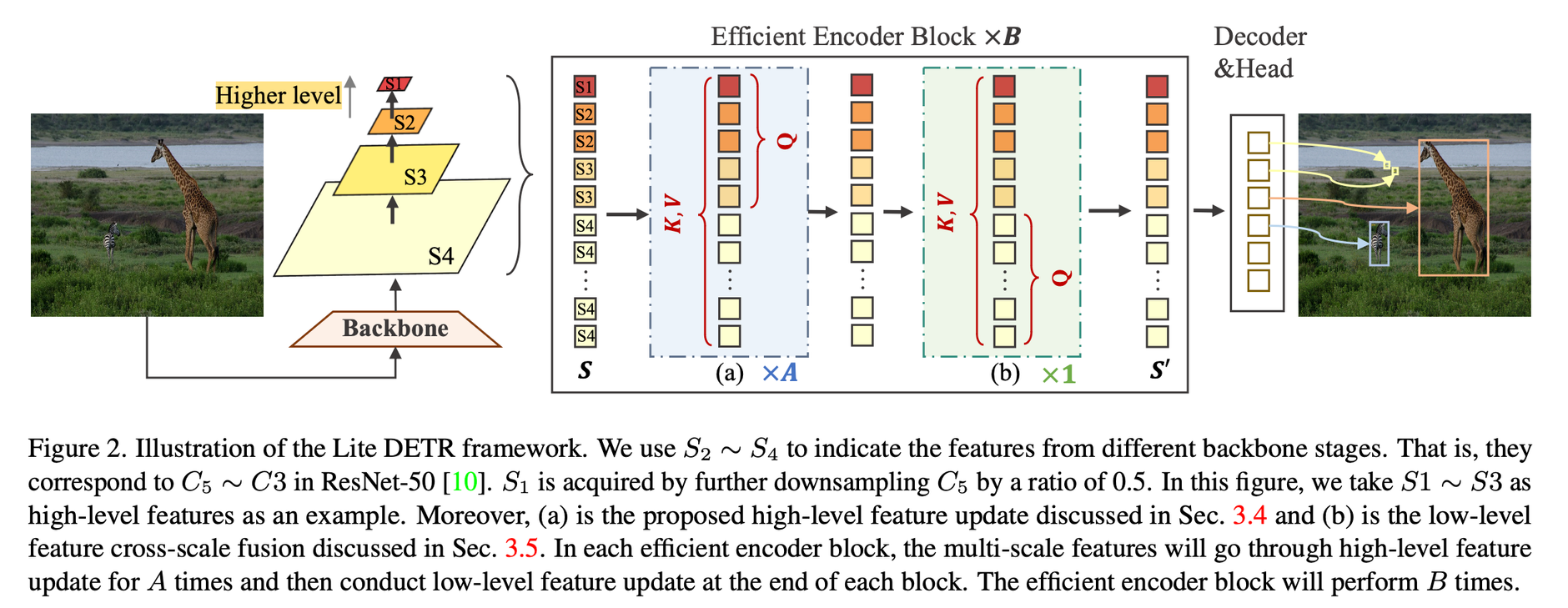
Interleaved Update
ResNet-50 에서의 C5~C3 를 S2~S4 라고 지칭
S1은 S2를 downsampling 한것
S1, S2, S3 → high-level feature (small-resolution feature)
S4 → low-level feature (high-resolution feature)
모든 scale의 featue를 한번에 연산하면 computation cost가 크다 → high-level과 low-level을 나누어서 진행
Iterative High-level Feature Cross-Scale Fusion
low-level feature 보다 토큰 수 가 적은 high-level feature에 대해서는 A번을 진행
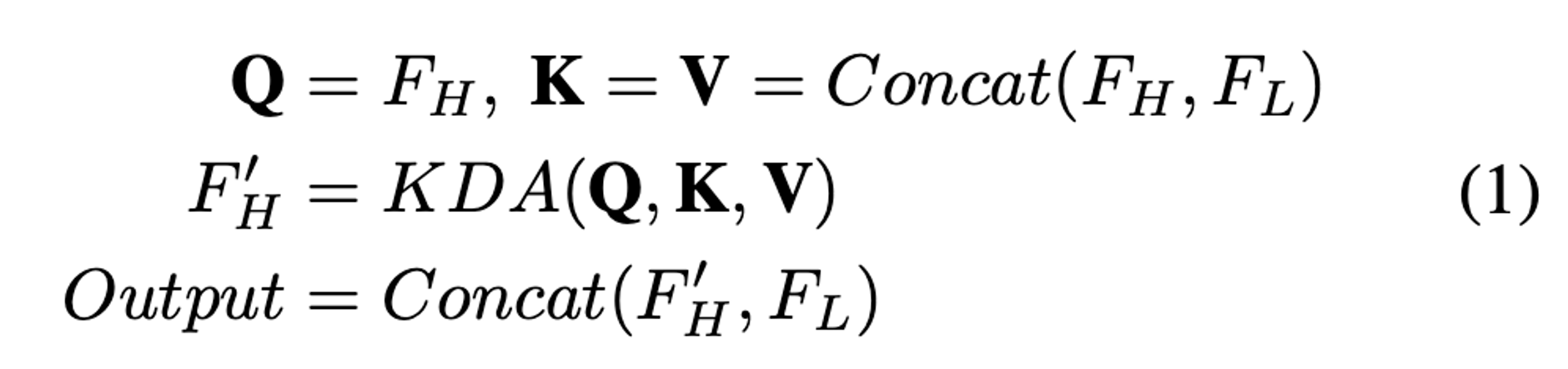
high-level 에 해당하는 Feature 토큰만 query로 사용 (S1, S2, S3)
key, value는 전체 토큰
Key-aware Deformable Attention (KDA) 연산 - 추후 설명 예정, Deformable Attention 이라고 생각해도 무방
low-level feature에 대한 토큰을 concatenate
Efficient Low-level Feature Cross-Scale Fusion
high-level feature 보다 토큰 수가 많은 low-level feature에 대해서는 1번만 진행
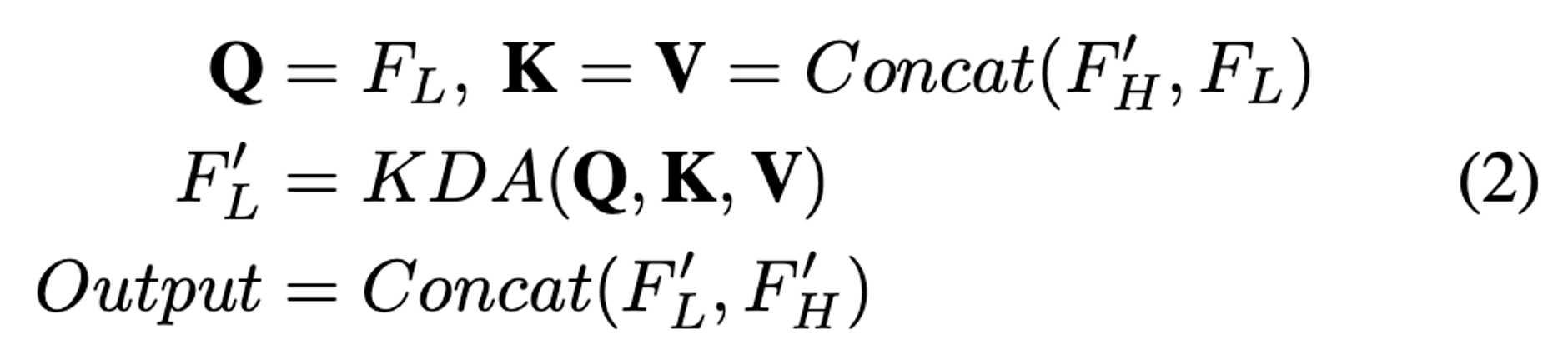
high-level feature cross-scale fusion 연산과 비슷한 방식
low-level 에 해당하는 Feature 토큰만 query로 사용 (S4)
key, value는 앞서 연산된 high-level feature에 대한 값과 low-level feature의 토큰
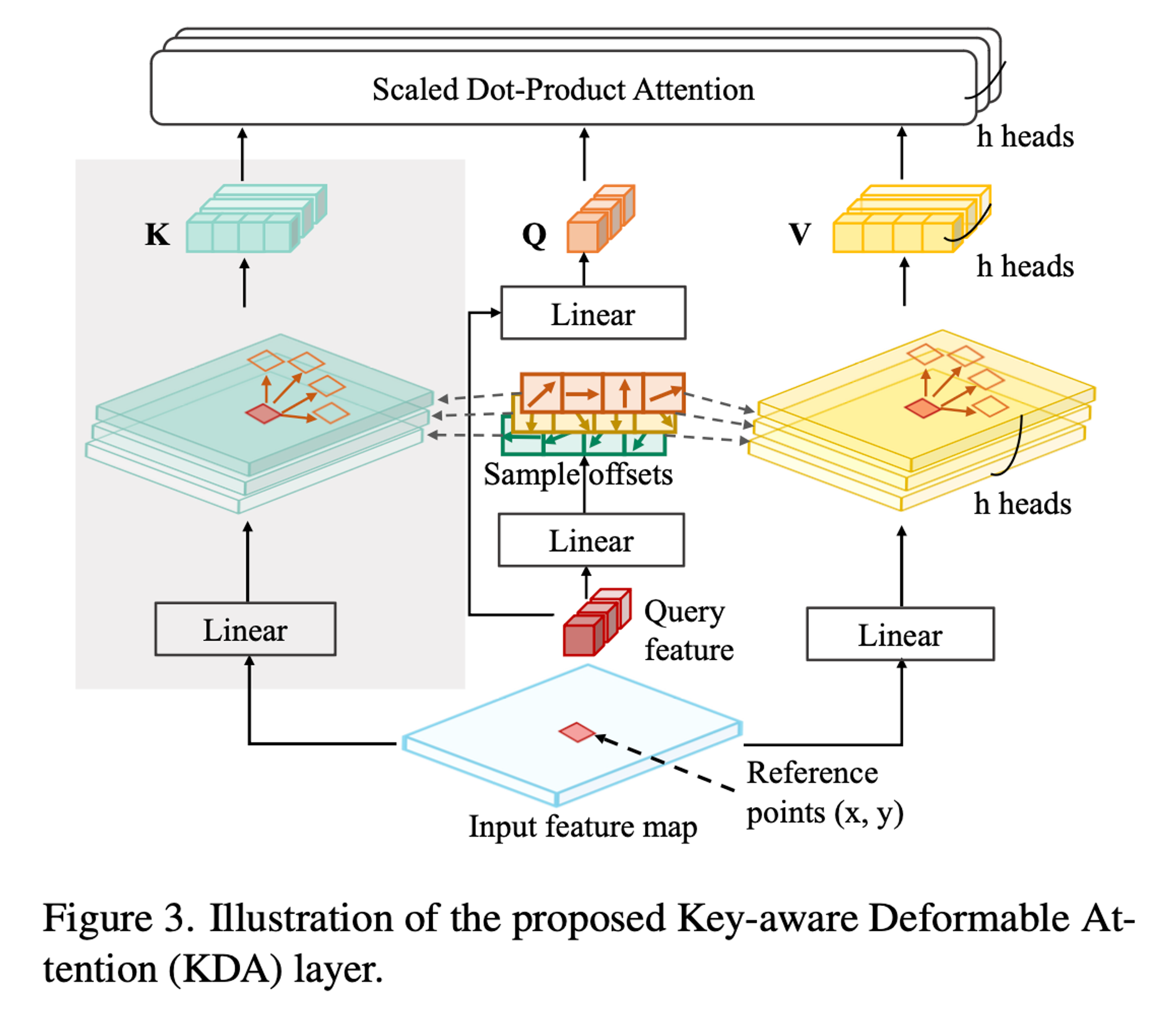
Key-aware Deformable Attention
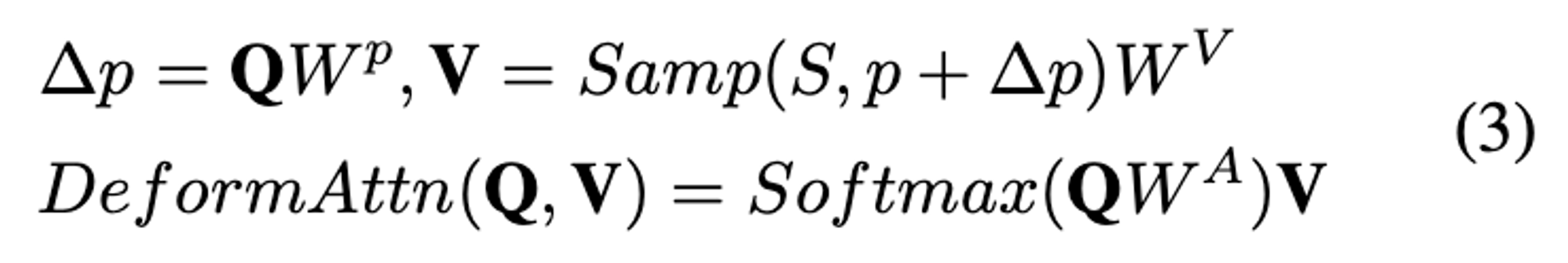
기존의 Deformable Attention 연산 과정
Nevertheless, the interleaved update in our encoder makes it difficult for the queries to decide both the attention weights and sampling locations in other asynchronous feature maps
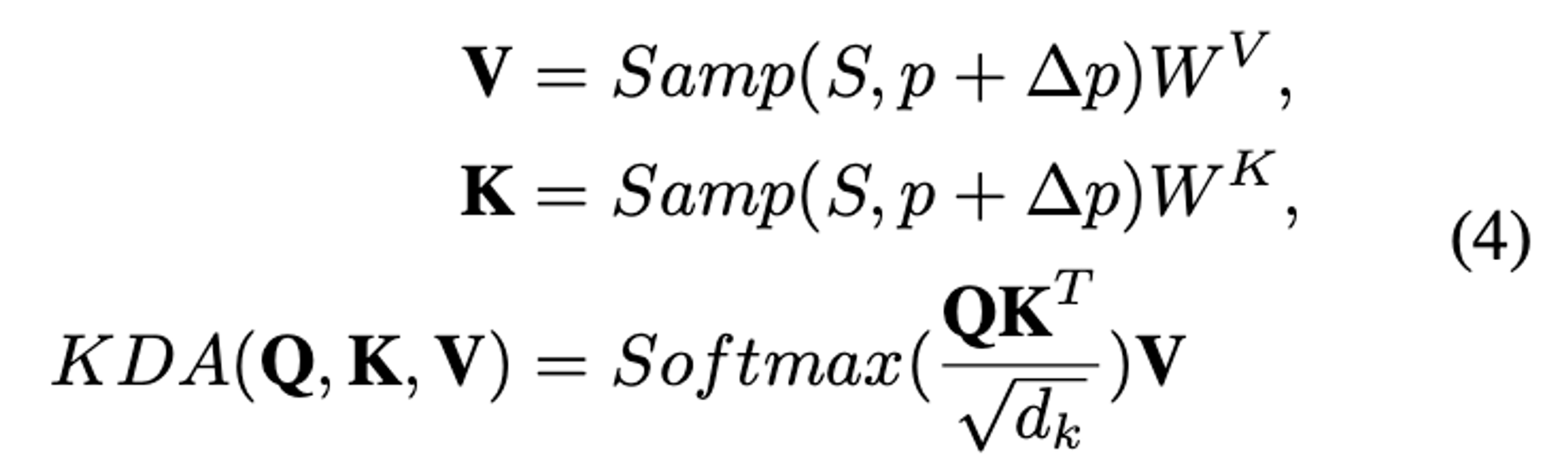
Deformable attention 에서 value에 하는 연산을 key에도 동일하게 연산
KDA can predict more reliable attention weights when updating features from different scales
Experimental Results
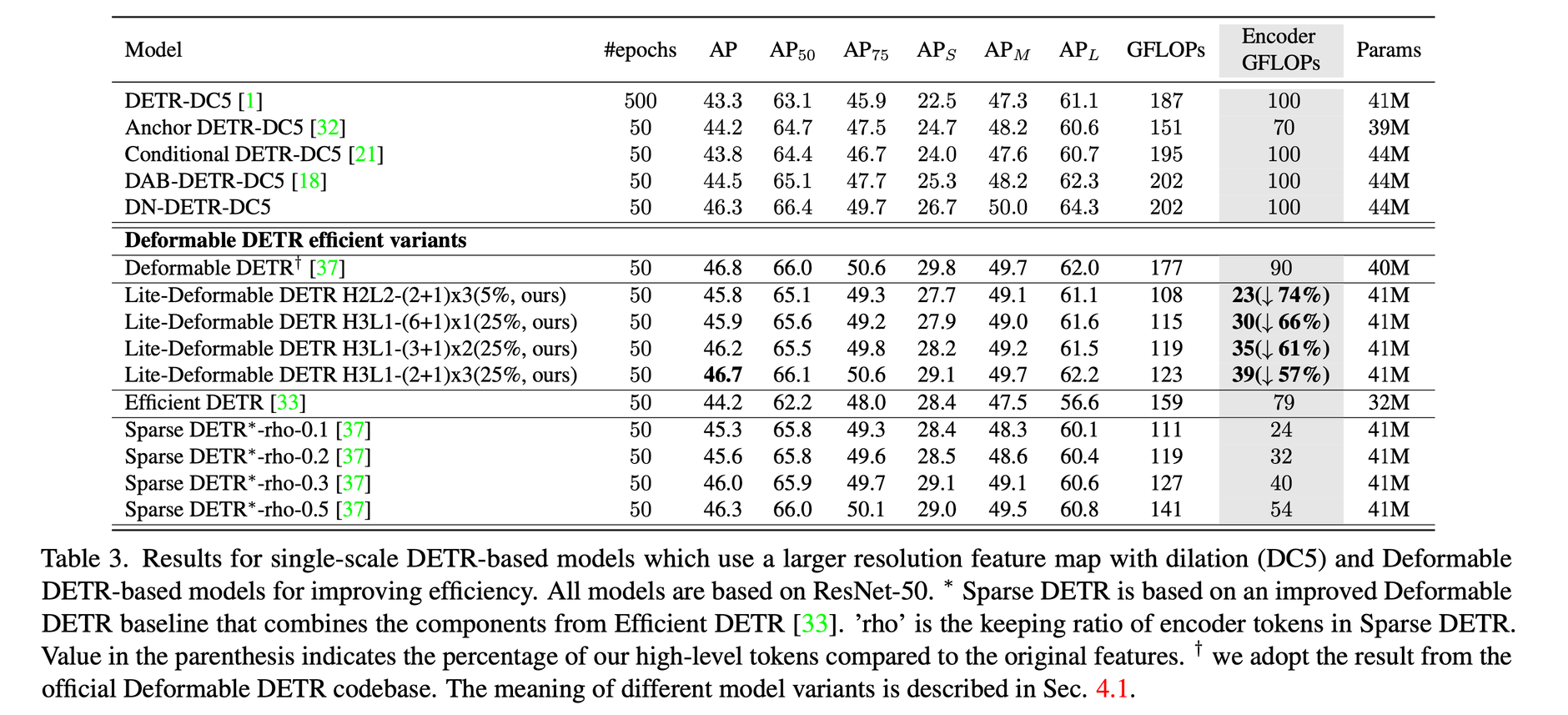
H3L1 - (6 + 1) x 1
high-level feature 를 3개, low-level feature를 1개
high-level feature attention 을 6번 반복 → A
x 1 - encoder block 수 → B
Deformable DETR에 제안하는 방법을 붙였을때 성능 하락을 최소화하면서 GFLOPs를 크게 줄였다
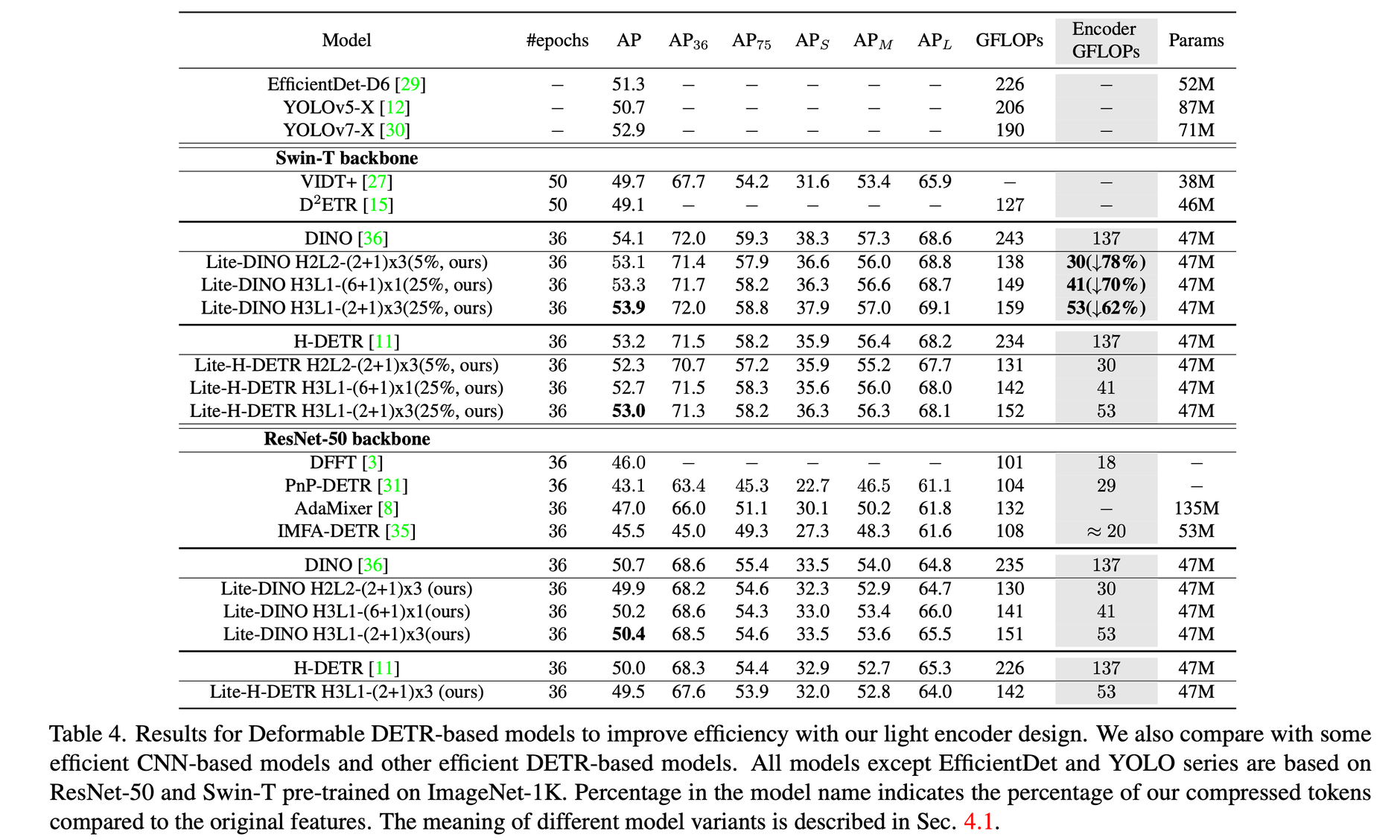
다른 DETR 방법들에 적용했을 때의 결과
마찬가지로 성능하락을 최소화하면서 GFLOPs를 크게 줄였다
Lite-DINO는 YOLO 방법들과 비슷한 GFLOPs 를 보여주면서 성능을 뛰어넘었다

(a) - S1 feature map 에서의 object center 를 query로 설정하고 그에 따른 모든 scale에 대한 top 100sampling location (triangle shape 은 S4에 대한것)
(b) & (c) - S3 & S4 에서의 top 200 sampling locations
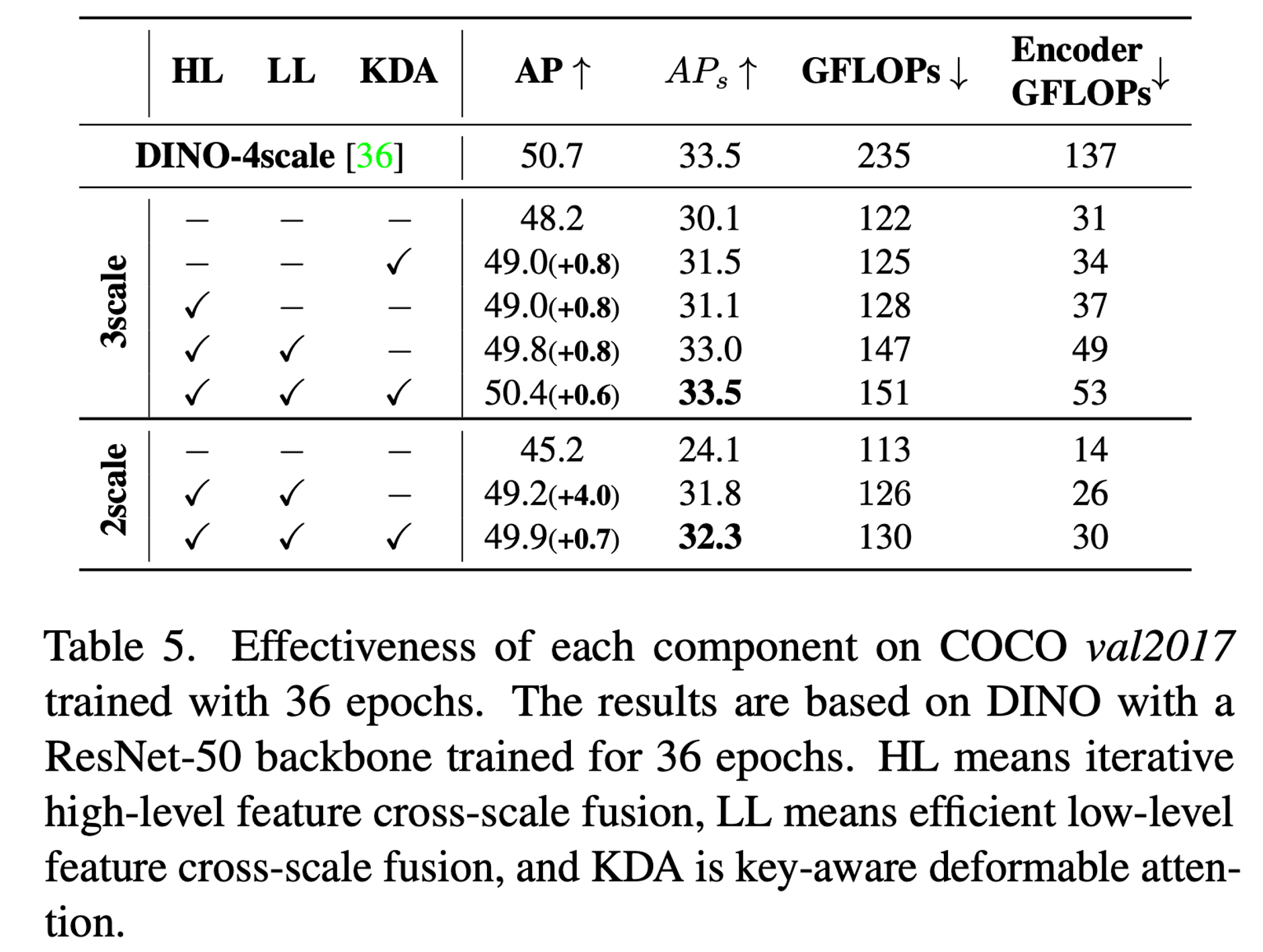
여기서 Baseline 은 DINO-3scale, DINO-2scale
HH - high-level feature cross-scale fusion
LL - low-level feature cross-scale fusion
3 scale 에서는 3개 scale을 high-level로, 2scale 에서는 2개의 scale을 high-level (DINO-4scale 에서)
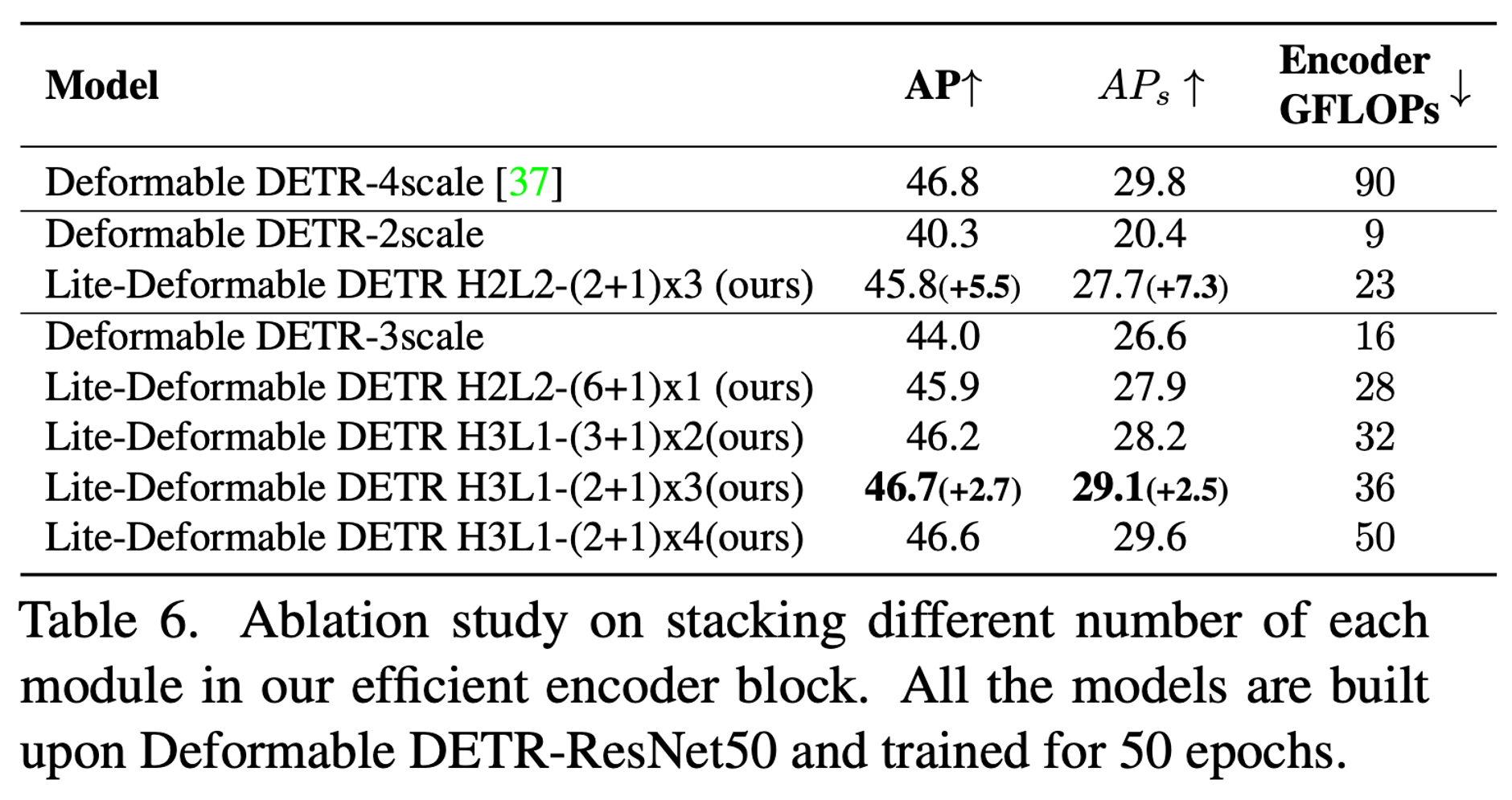
각 모듈별 개수에 따른 ablation study