Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
CVPR 2023, 2024-01-17 기준 9회 인용
Task
- Object Detection
- DETR
Contribution
- Multi-scale feature 를 활용하는 것이 좋지만 huge computation costs 를 야기시킨다.
- Iterative Multi-scale Feature Aggregation (IMFA) 구조를 제안 -> efficient use of multi-scale
- Sparse multi-scale features sampling 방법을 제안
- Encoded features 가 전 레이어의 detection 결과를 기반으로 iteratively 업데이트 되도록 한다
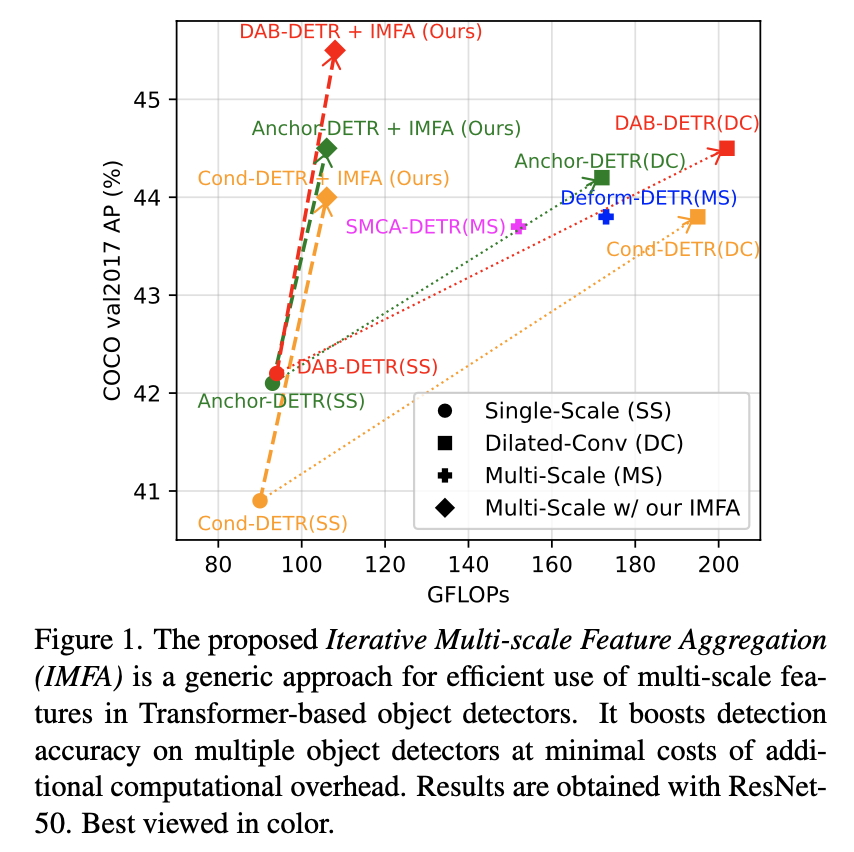
기존의 multi-scale 방식들은 computation cost 가 높다
논문에서 제안하는 방법을 적용했을 경우 computation cost 도 줄이고 성능도 향상된다
Proposed Method
Iterative Update of Encoded Features
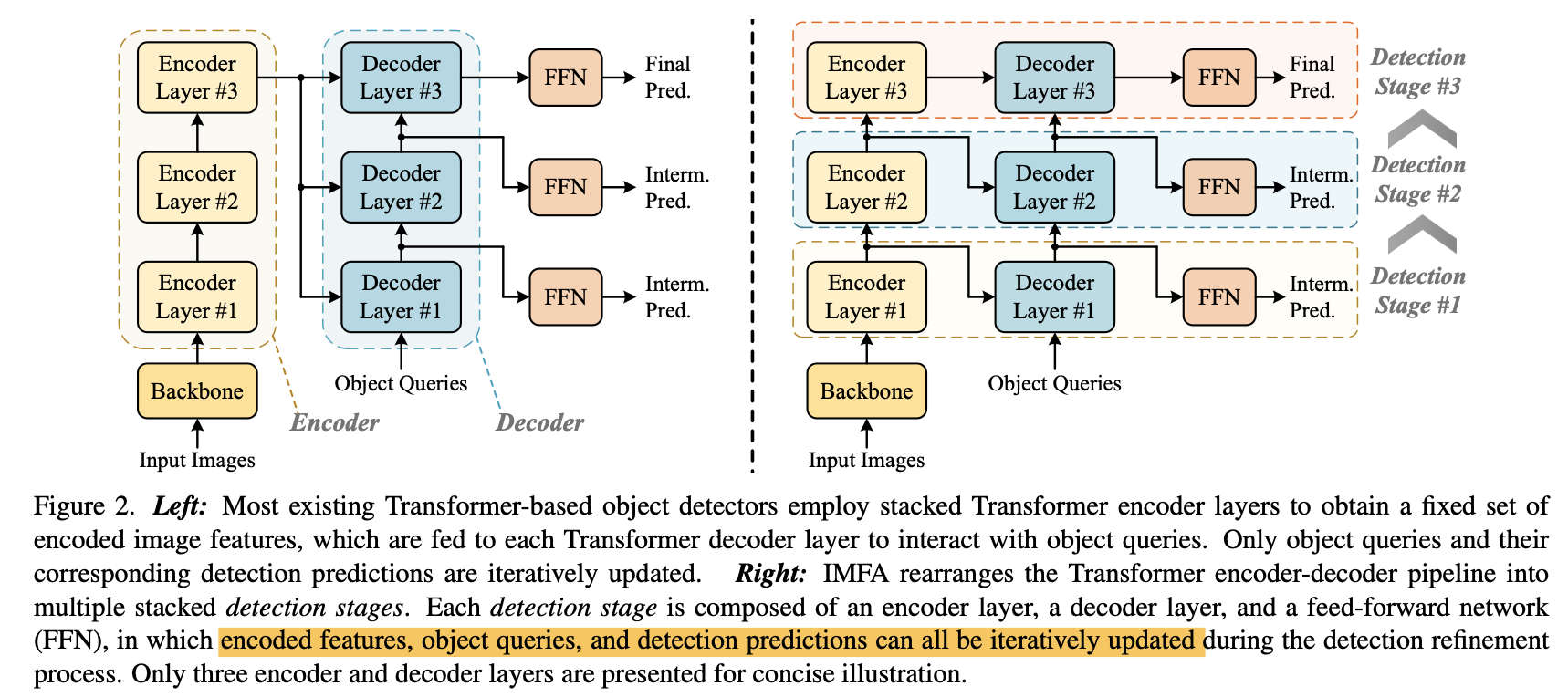
Left: 기존의 DETR 방법들 - Encoder 로 부터 얻어진 features 를 모든 decoder layer 에서 그대로 사용
Right: 본 논문에서 제안하는 Iterative Multi-scale Feature Aggregation IMFA rearrange 방법
전 decoder layer 에서 prediction 된 결과를 기반으로 encoder feature 도 update
This new pipeline allows to leverage intermediate predictions as guidance
multi-scale feature 를 활용해서 encoder feautre 를 업데이트 하지 않을 경우 성능 향상을 얻어내지 못함
Sparse Feature Sampling and Aggregation
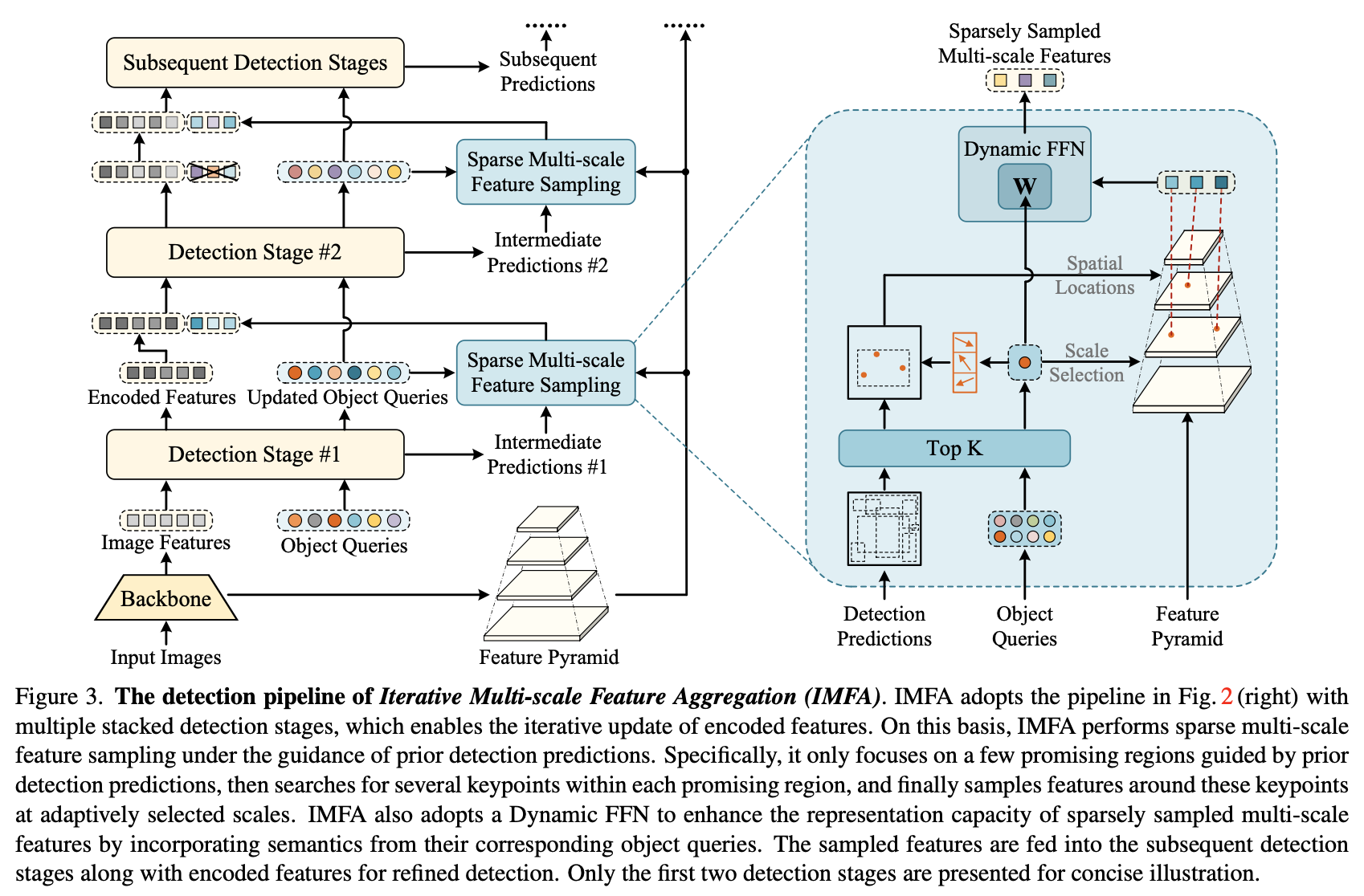
여기서 multi-scale feature를 활용
모든 scale의 tockens 들을 활용하기에는 너무나 많으니 sparse sampling 하겠다는 취지
전 decoder layer의 결과를 기반으로 top $K$ 개를 선택
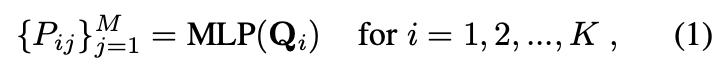
$K$ 개의 쿼리로 부터 $M$ 개의 keypoint locations 을 predict
bilinear interpolation 을 통해서 모든 scale 으로 부터 feature 를 sampling
${\textbf{F}^s_{ij}}^S_{s=1}$, $S$ 는 feature scales 수
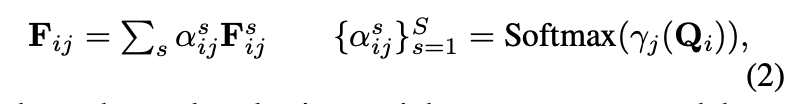
to emphasize the distinct significance of different feature scales for each keypoint
keypoint 마다의 feature 들이 scale-specific attention 되도록 한다
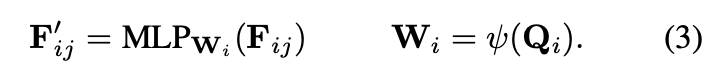
to further strengthen the representation capacity of the sampled multi-scale features
Dynamic Feed Forward Netwrk (Dynamic FFN) 를 설계
Object queries 를 Linear projection 시켜 weights 으로 활용
Iterative Aggregation of Multi-Scale Features
To avoid continuous growth of feature tokens and maintain efficiency
feature tockens 가 계속 늘어나는 것을 방지하기 위해서 이전 stage 에서 생성된 feature 는 버리고 진행한다
Experimental Results
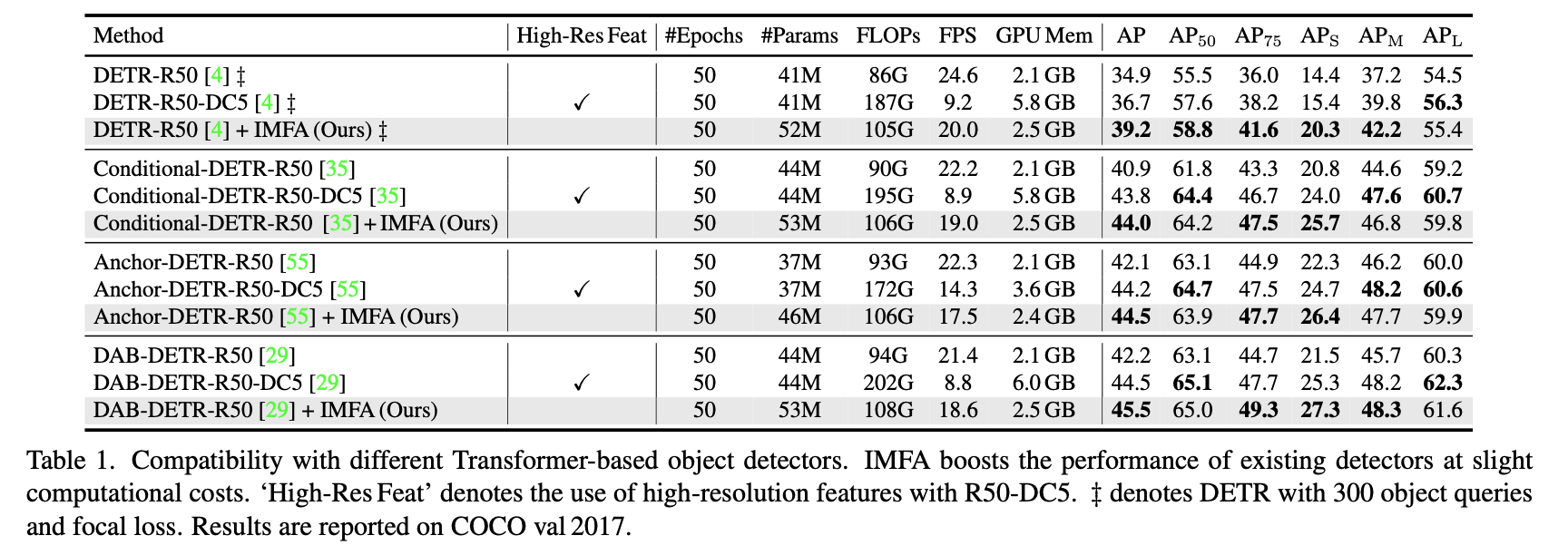
각 DETR 방법들에 제안하는 방법을 적용했을 경우 모두 성능이 향상된다
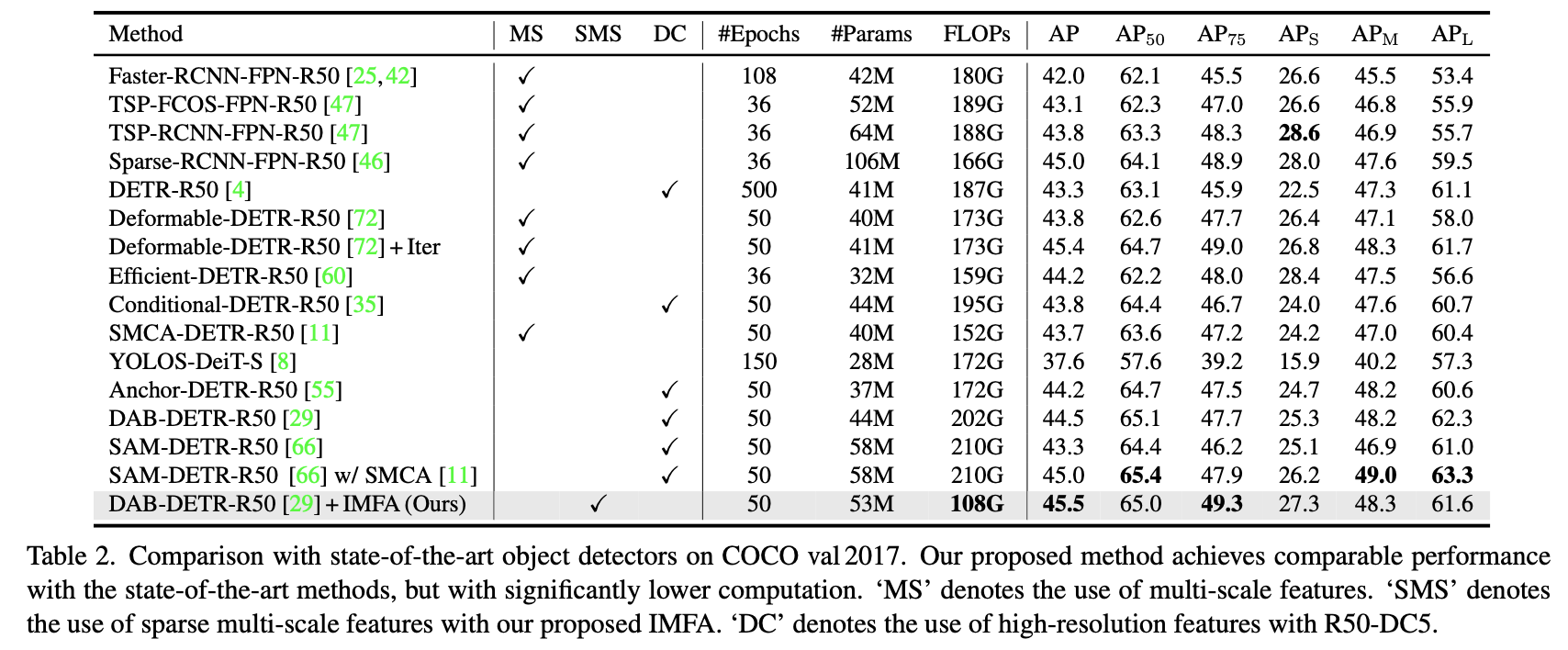
multi-scale feature 활용하는 다른 방법들과 비교했을 때 computation cost 는 줄이고 성능은 향상되었다
Table 1 에서는 FPS 를 비교하지만 여기서는 비교하지 않는다..
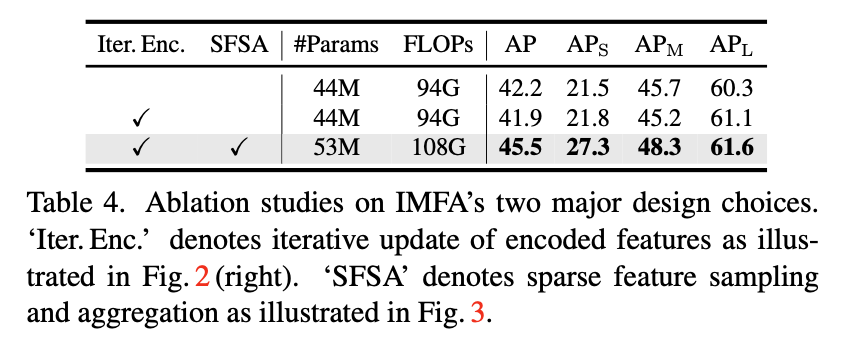
Iterative update encoded feature 만 적용했을 때는 성능 향상이 없다
multi-scale feature 에 대한 sparse feature sampling and aggregation 까지 적용되었을 때 성능 향상