Foreground-Background Separation through Concept Distillation from Generative Image Foundation Models
Foreground-Background Separation through Concept Distillation from Generative Image Foundation Models
ICCV 2023, 2024-03-10 기준 2회 인용
Contributions
- Stable Diffisuion 을 기반으로 segmentation mask 생성
- 즉, annotation 되어 있는 mask 를 사용하지 않고 생성된 mask 로 segmentation task 를 학습
- Synthetic images 와 그에 따른 segmentaattion mask 생성 해서 추가 데이터로 활용
Motivation
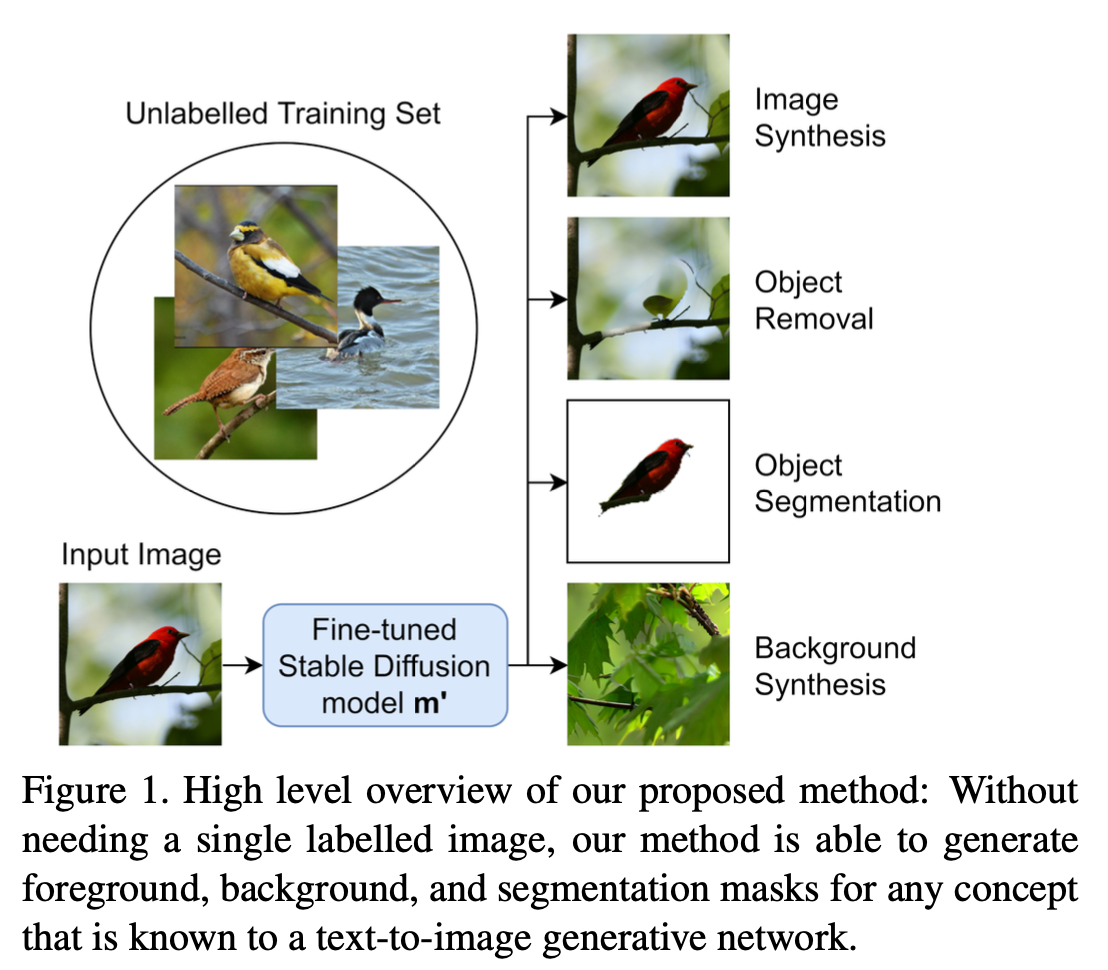
Pre-trained 된 generative latent diffusion foundation model 를 활용해서 segmentation label 을 사용하지 않고 생성해서 segmentation task 를 학습
pre-trianed stabel diffusion 모델을 활용해서 weak segmentation mask 를 생성
그리고 해당 mask 를 diffusion 모델 fine-tuning 하는데 활용해서 mask를 refinement
Prospoed Method
$\text D$ - original datasets images
$\text D_m$ - original datsaets images 에 대해 생성된 mask
$\text D’$ - 생성된 synthetic images
$\text D’_m$ - 생성된 synthetic images 에 대해 생성된 mask
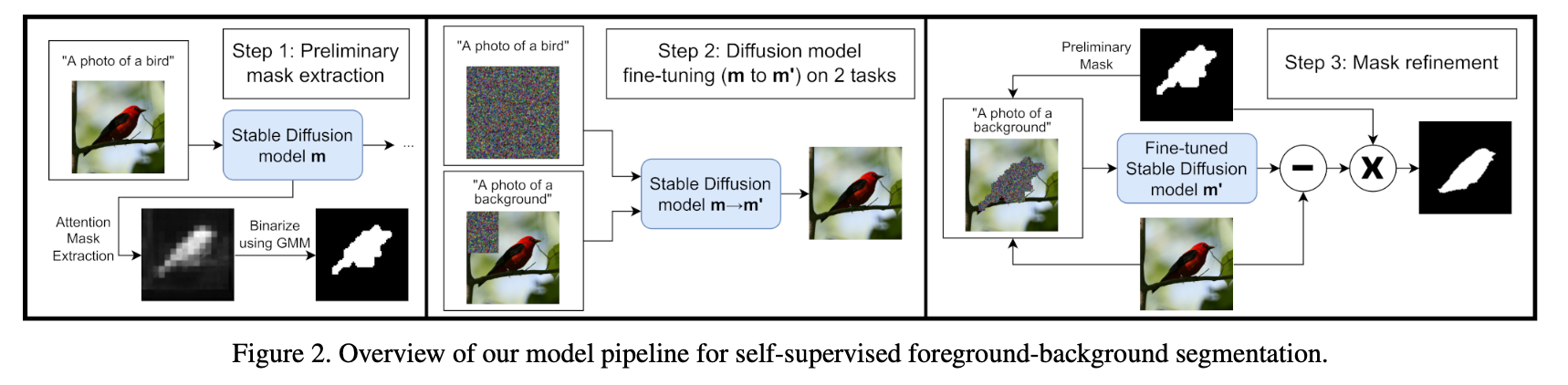
Preliminary Masks
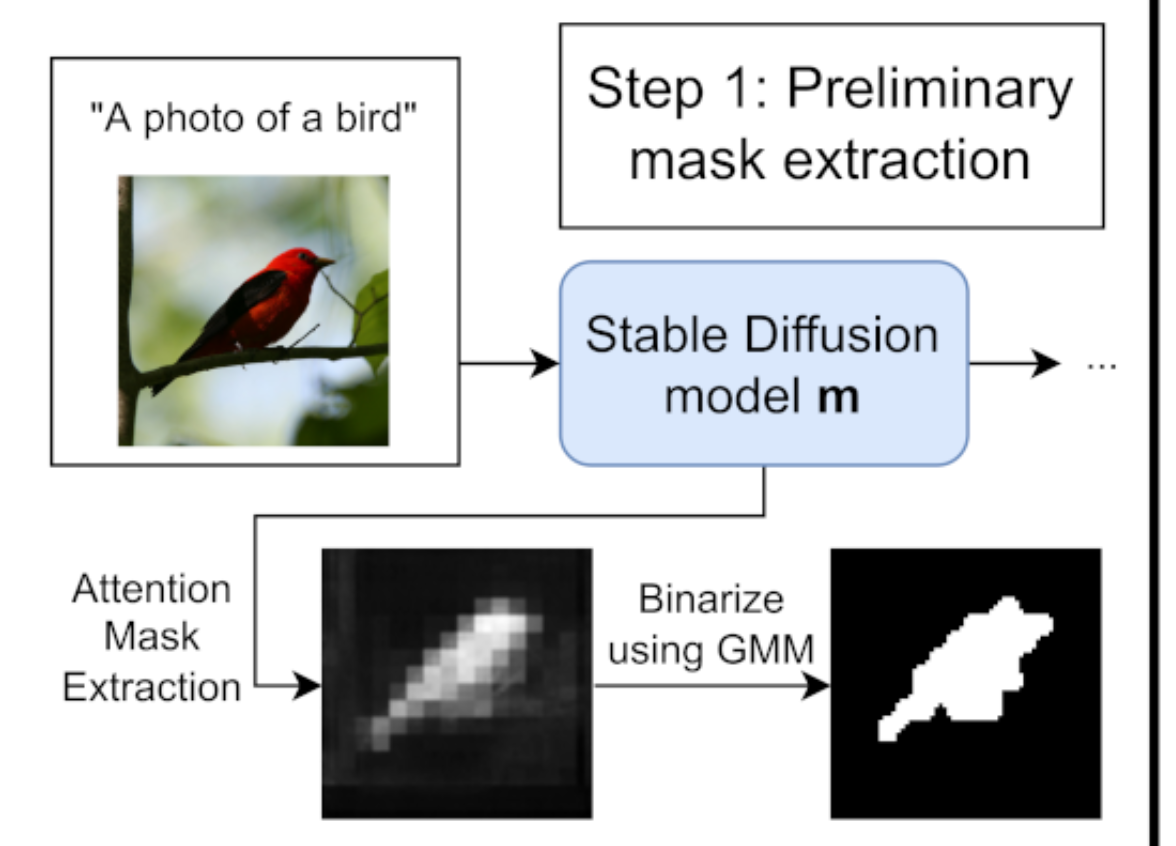
Pre-trained 된 stabe diffusion model 을 활용해서 mask 를 생성
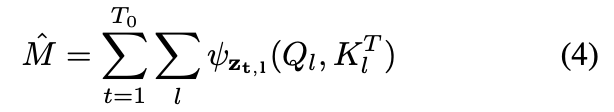
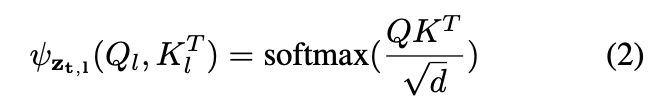
reverse diffusion steps (noise 를 제거하는 과정) 에서의 cross-attention map 을 사용
Example)
$T_0 = 3$
1 step 만큼 noise 추가하고 1->0 으로 갈때 연산되는 cross-attention map 활용
…
3 step 만큼 noise 추가하고 3->2 으로 갈때 연산되는 cross-attention map 활용
$T_0$ 만큼의 cross-attention map
U-Net 구조에서의 모든 cross-attention layer 사용
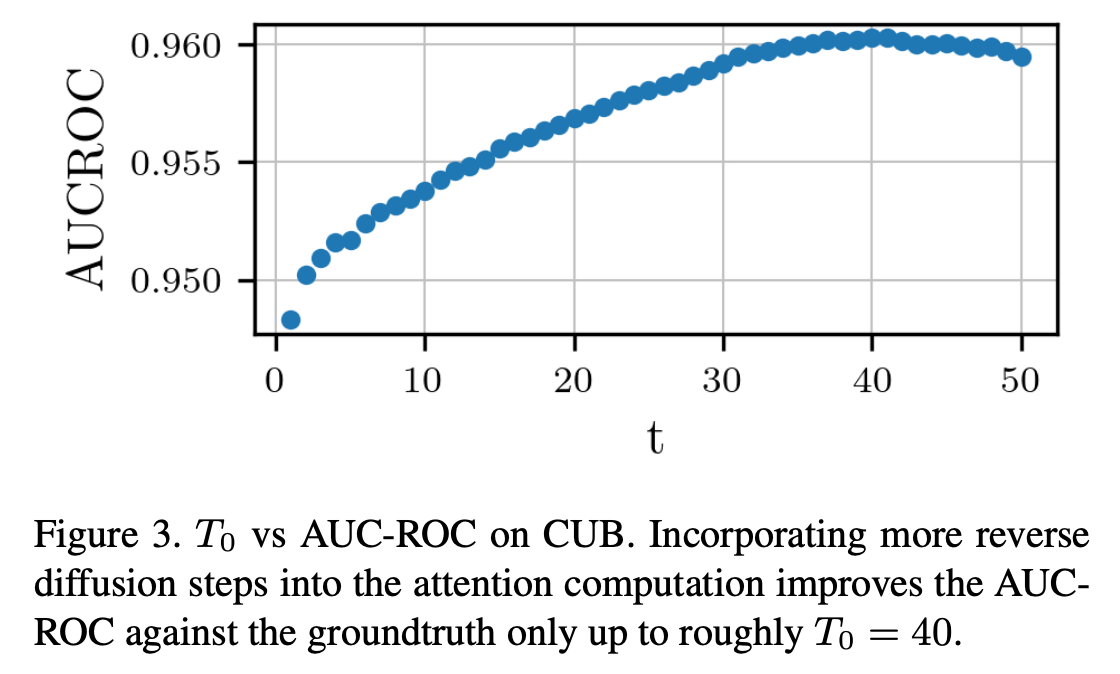
$T_0 = 40$ 일때 가장 좋은 결과
$t$ 값이 너무 크면 pure Gaussian noise 에서 attention map 을 구하는 것이기 때문에 성능 하락
Bimodal Gaussian mixture model 활용해서 Binarize 해서 최종적으로 Preliminary mask extraction
Fine-tuning
LDM space 에서 이루어 지기 때문에 resolution 이 64 x 64
-> object’s sharp edges 에 대해서 한계를 갖고 있음
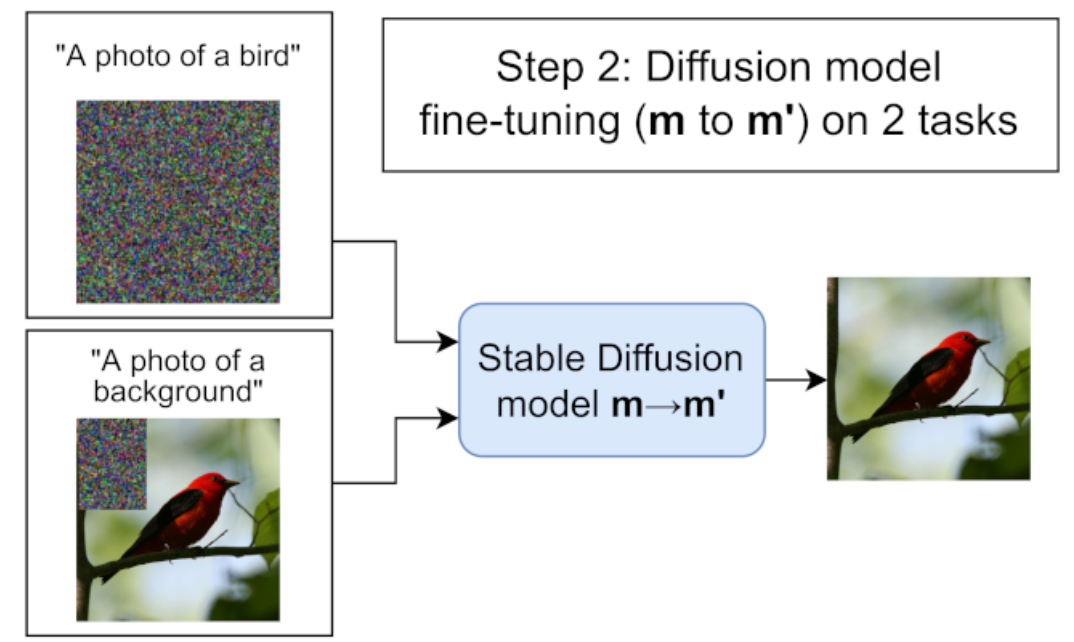
Random rectangles 를 선택하고 해당 부분을 inpainting 으로 fine-tuning
Preliminary mask 를 사용해서 background 만 선택될 수 있도록
“A photo of a background” 를 text-prompt 로 사용

선택된 rectangles 안에 Preliminary mask (foreground) 가 있을 경우 제외
전체 이미지 생성하는 것에 대해서도 학습
“A photo of a {object}” 사용
Mask Refinement
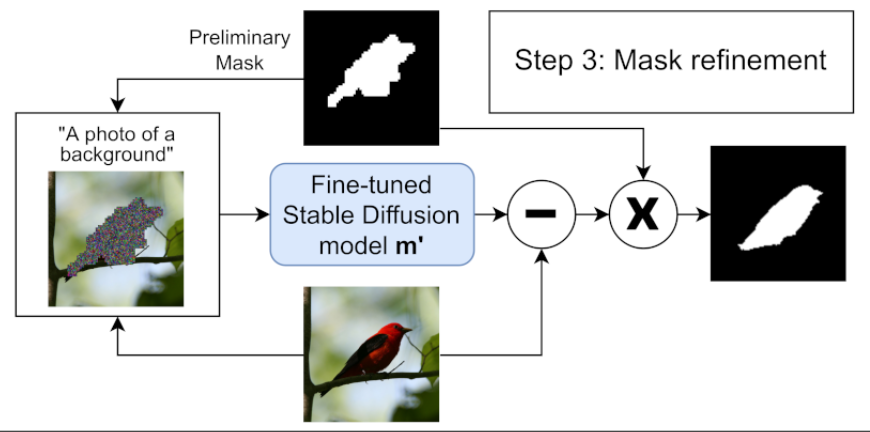
Preliminary mask 에 해당 하는 부분을 random nosie $\text z$ 로 replace
Fine-tuned Stable Diffusion model 로 이미지를 background 이미지를 생성
(원본 이미지 - 생성된 background 이미지) -> sharp edges of the object 부분을 향상
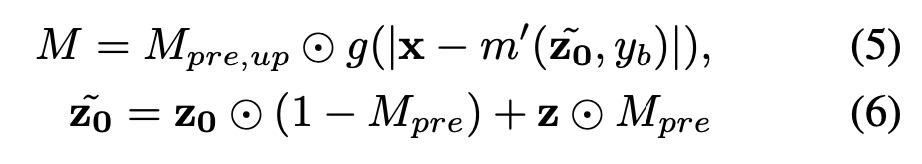
기존의 Preliminary mask 에 (원본 이미지 - 생성된 background 이미지) 를 사용해서 Refinement
Generate Synthetic Datasets
$\text D’$ - 생성된 synthetic images
$\text D’_m$ - 생성된 synthetic images 에 대해 생성된 mask
$\text D’$ 은 Fine-tuned Stable Diffusion 모델을 통해서 생성
$\text D’_m$ 은 Mask refinement 과정을 진행해서 생성
Experimental Results
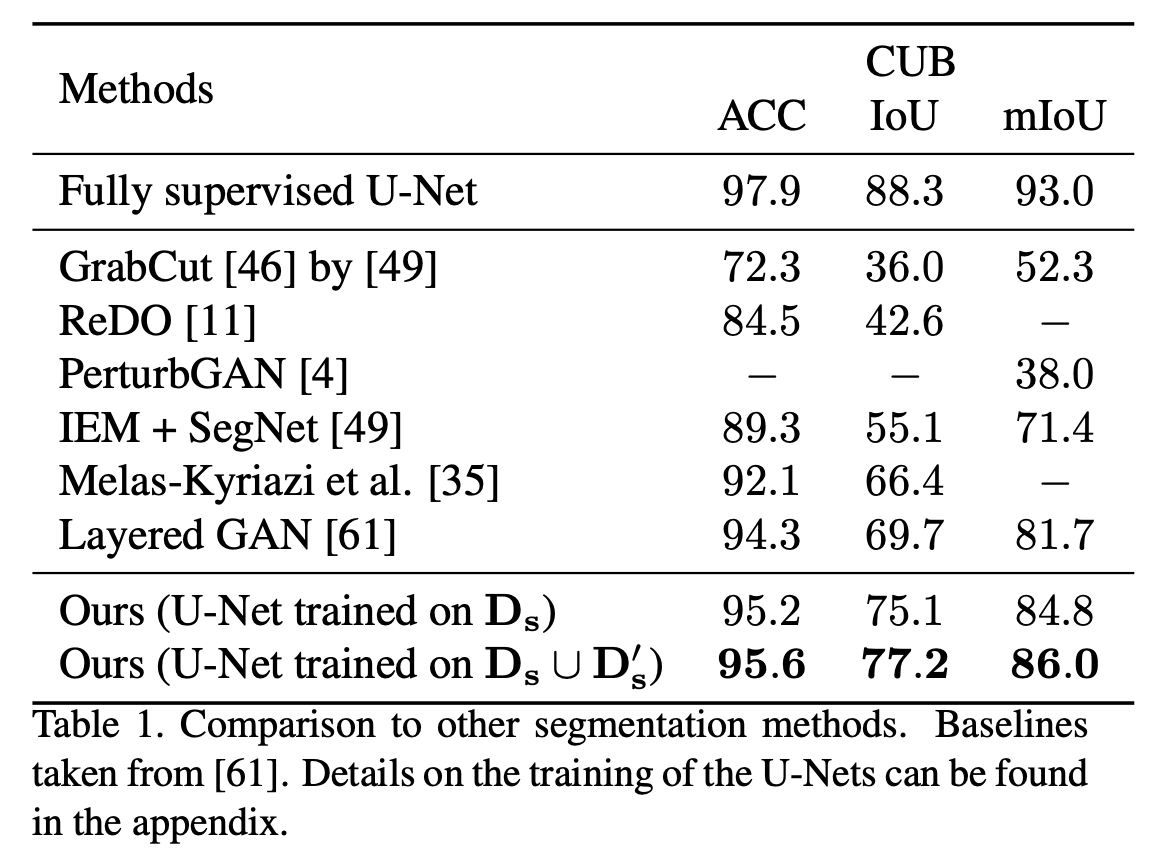
$\text D_s$ - 기존의 datasets 에서 segmentation label 을 사용하지 않고 생성된 mask 를 사용
$\text D’_s$ - Synthetic datasets 추가
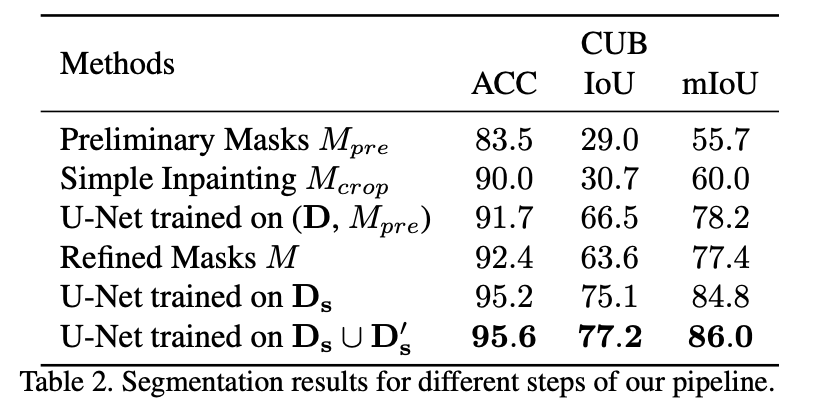
Preliminary Masks $M_{pre}$ - zero-shot 으로 처음에 생성된 mask를 그대로 평가
U-Net trained on ($\text D$, $M_{pre}$) - $M_{pre}$ 를 segmentation mask 로 학습
Refined Maasks $M$ - Refined 된 mask를 평가
Simple Inpainting $M_{crop}$
extracting the largest background region according to the preliminary masks and then flipping it into the region of the foreground object.

segmentation mask 생성 결과

mean attention map 결과
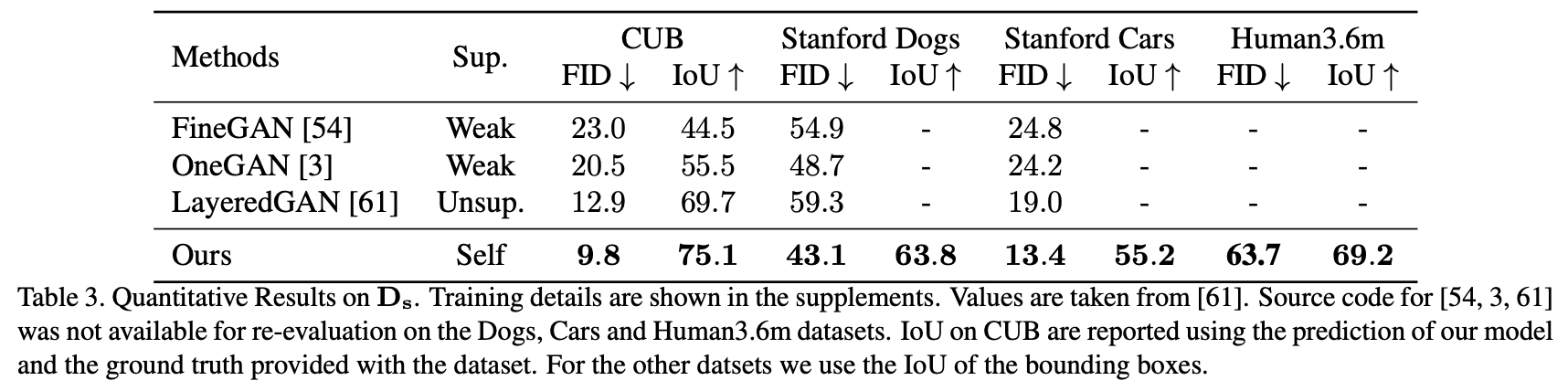
생성된 segmentation mask quality 대한 Quantitative results

condition 을 $y_b$ (background) 로 주고 background image 를 생성했을 때의 결과