FS-DETR: Few-Shot DEtection TRansformer with Prompting and without Re-Training
FS-DETR: Few-Shot DEtection TRansformer with Prompting and without Re-Training
ICCV 2023, 2024-04-17 기준 11회 인용
Task
- Object Detection
- Few-Shot Learning
Contributions
- fine-tuning free, re-training free Few-Shot DEtection TRansformer (FS-DETR) 을 제안
- Template encoding 과 Pseudo-class embedding 구조를 제안
Proposed Method
Practical perspective
(1) without requiring any fine-tuning at test time
(2) be able to process an arbitrary number of novel objects concurrently while supporting an arbitrary number of examples from each class
(3) achieve accuracy comparable to a closed system
$C = C_{novel} \cup C_{base}$
$C_{novel} \cap C_{base} = \emptyset$
학습에는 base class 데이터만 사용
Test 는 학습에 사용되지 않은 데이터인 novel class 데이터로 진행
(novel 과 base 간에는 같은 object category 일지라도 다른 이미지일 경우 다른 class)
$O \in \mathbb{R}^{N \times d}$
기존 DETR 은 object queries $O$ 를 사용 → prompts (closed-set detection)
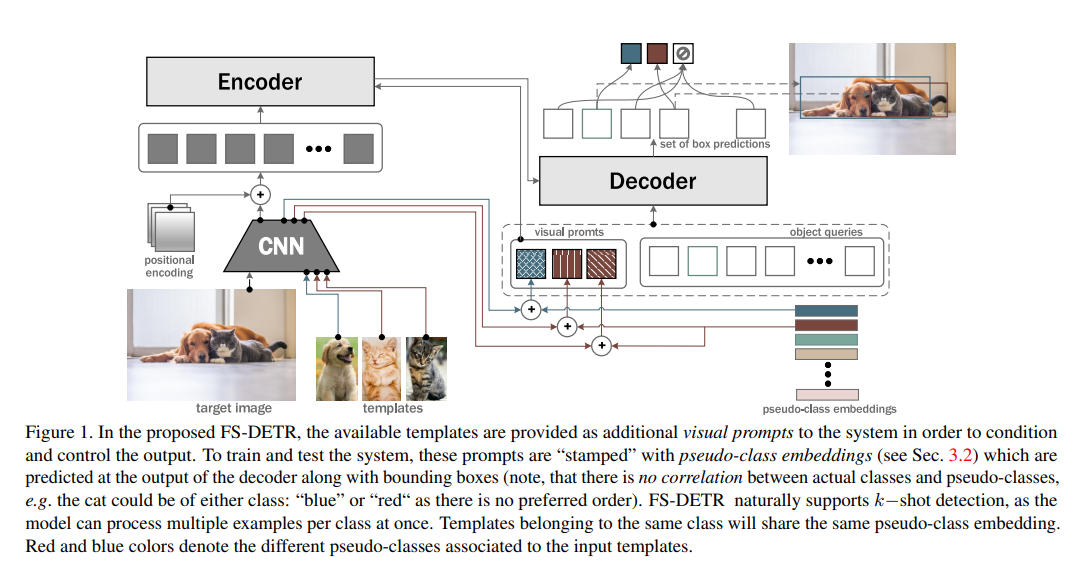
Method
provide novel classes’ templates as additional visual prompts in order to condition and control the detector’s output
Template encoding
$T_{i, j} \in \mathbb{R}^{H_p \times W_p \times 3}$
$i$ - 1~m, $j$ - 1~k
m - class 개수, k - class 당 example 수
m x k 개 만큼 template 을 뽑는다
같은 category 에 있는 다른 이미지의 object 를 crop
X = CNN(T)
backbone 인 CNN을 태운다 → average pooling → mk x d
Templates as visual prompts
$\text{C}^s \in \mathbb{R}^{mk \times d}$
pseudo-class embeddings
initialised normal distribution and learned during training

template image 의 feature 에 pseudo-class embeddings 을 더해준다
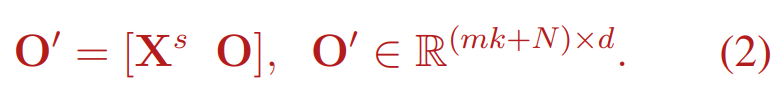
templates 를 visual prompt 로 여기고 기존의 object queries와 concatenate
FS-DETR encoder
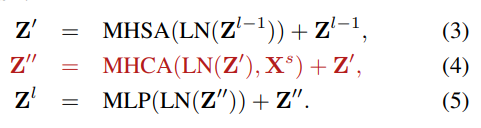
encoder 부분에 MHCA(Multi-Head-Cross-Attention) 을 추가
image featured와 template와 cross-attention
FS-DETR decoder

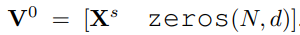
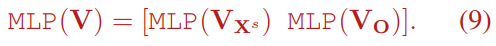
$(mk + N) \times d$ 에서 $mk \times d$ 따로 $N \times d$ 따로 MLP 하고 concat
FS-DETR training and loss functions
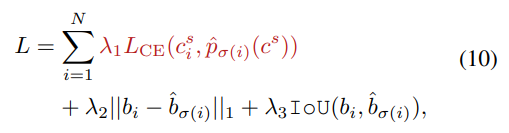
set prediction 할때에는 $V_O$ 만 사용
즉, $N \times d$ 에 해당하는 부분만 마지막 head를 통해서 set prediction
visual prompt 는 object query와 함께 self-attention 되고 cross-attention 되는데 사용 되서 template image의 정보를 파악할 수 있게 해준다 라고 이해
Experimental Results
k-shot setting
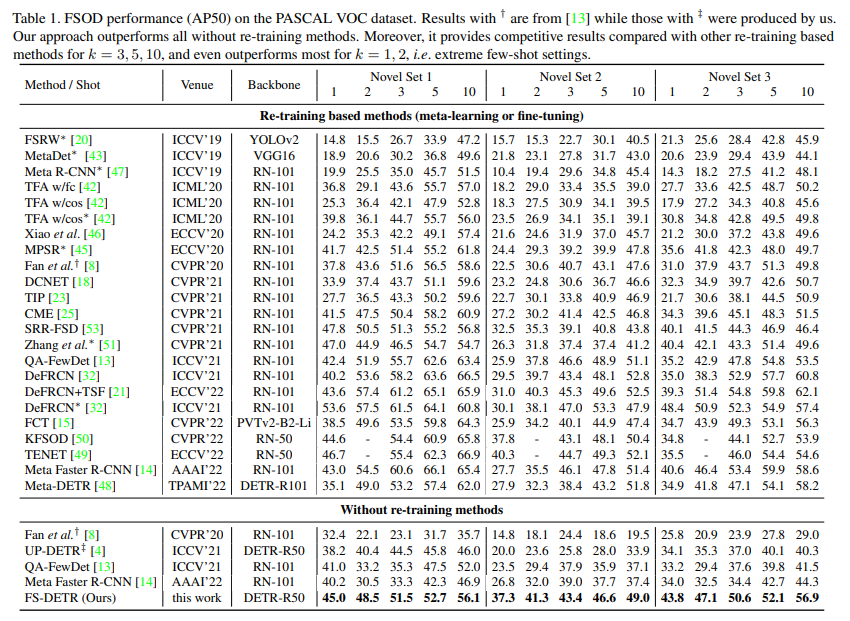
PASCAL VOC dataset에 대한 실험 결과

COCO dataset 에 대한 실험 결과