FP-DETR: Detection Transformer Advanced by Fully Pre-training
FP-DETR: Detection Transformer Advanced by Fully Pre-training
ICLR 2022, 2024-04-22 기준 31회 인용
Task
- Object Detection
- DETR
Contributions
- Large scale pre-training 은 down stream task 에 효과적인 visual representation learning 을 가능하게 해준다
- 하지만 Transformer 기반 Object Detection 방법들은 transformer layer를 모두 scratch 부터 학습한다 (보통 12개의 transformer layer)
- Fully Pre-Trains an encoder-only transformer (FP-DETR) 구조를 제안
- textual prompts in NLP 에서 영감을 받아 query positional embedding 을 visual prompts 처럼 여긴다 → 새로운 구조를 제안하는 것은 아니다
Proposed Method

Pre-Training
ImageNet 으로 Classfication 학습할때에는 context aggregation 을 위한 class token 하나만 필요하다 → decoder 를 사용할 경우 overfitting 이 쉽게 된다 classification task 로 pre-training 을 하기 위해서 decoder 를 제거
Lightweight Multi-scale Tokenizer

multi-scale 에 대한 patch embedding
그리고 classification 을 위한 class token 추가 → 최종적으로 classification prediction 할 때 사용
Encoder Layer 12 개 사용
- 처음 6개 layer 에서는 image multi-scale patch 만사용
- 나머지 6개 layer 에서는 image multi-scale patch 와 class token concat


Fine-tuning
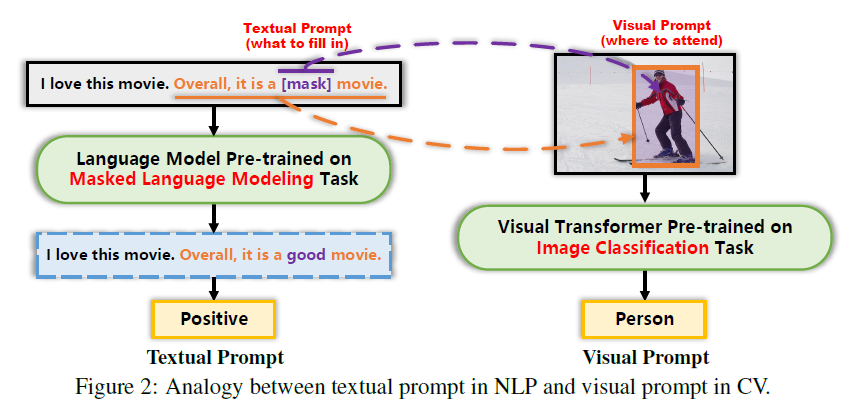
Our intuition is that if the classifier pre-trained on ImageNet knows where to look at
NLP 에서 textual prompt 와 유사하게 classification task 로 pre-trained 된 transformer layer 가 어디를 봐야할지 알고 있다는 가정
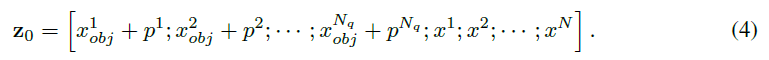
pre-training 과정에서의 cls token 위치에 query content embedding 으로 교체
query content embedding 에 있는 positional embedding 이 모델이 이미지의 어느 region 을 집중 해야할지에 대한 단서를 제공한다고 설명
Improving Fine-tuning with Task Adaptor

inter-object relationship 을 파악하기 위한 부분
거창한 TaskAdaptor 라는 이름을 붙였지만 self-attention layer 이다
앞선 pre-training 과정과 유사하게 Encoder Layer 12 개 사용
- 처음 6개 layer 에서는 image multi-scale patch 만사용
- 나머지 6개 layer 에서는 image multi-scale patch 와 query content embedding concat
→ Overfitting 을 막기위해서 제거한 Decoder 를 보안하기 위한 트릭이라고 생각
Experimental Results
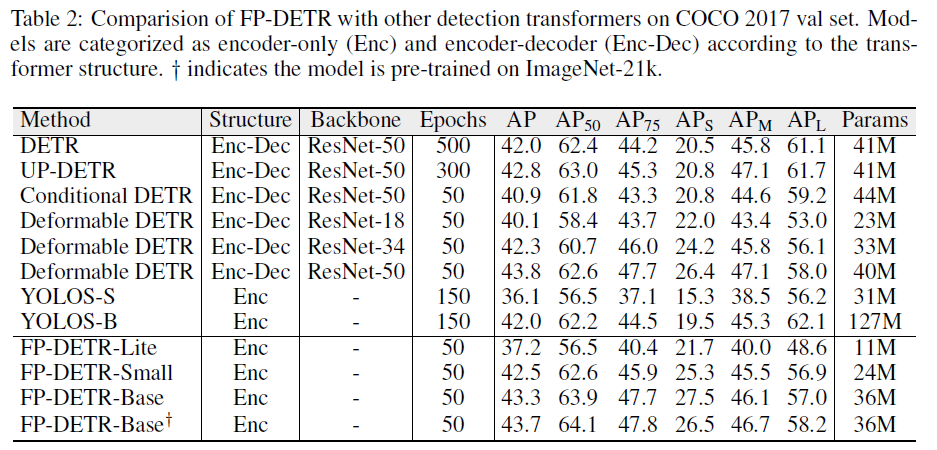
COCO 데이터셋에 대한 실험 결과