Effective Data Augmentation With Diffusion Models
Effective Data Augmentation With Diffusion Models
ICLR 2024, 2024-03-20 기준 76회 인용
Task
- Data Augmentation
- Generation
- Diffusion
Contributions
- 기존 data augmentation 은 high-level semantic attributes 를 고려하지 않는다
- lack of diversity 를 해결하기 위해서 pre-trained text-to-imgae diffusion model 을 활용
- Data Augmentation using Diffusion model (DA-Fusion) 구조를 제안
Proposed Method

Stable Diffusion model 을 활용해서 다양한 augmentation 을 하는 것이 목표

기존의 Augmentation 방법 (Real Guidance) 에 비해 제안하는 DA-Fusion 이 Augmentation 을 위해서 잘 생성
Preventing Leakage Of Internet Data
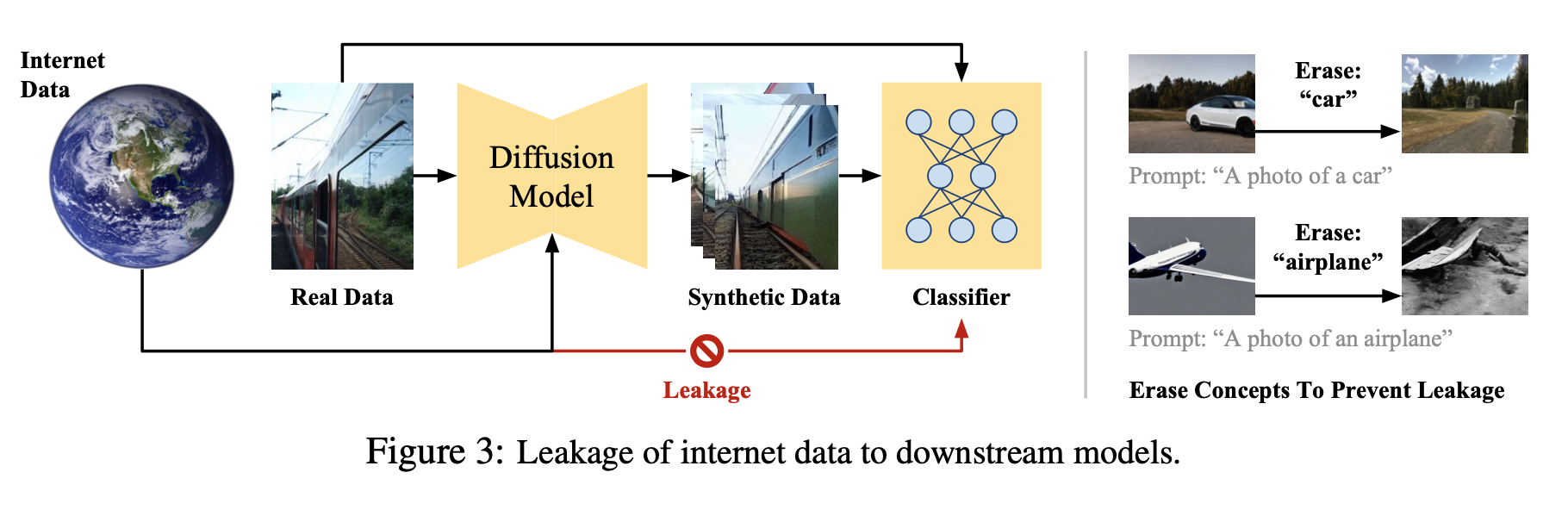
Stable Diffusion model 은 수많은 데이터들로 학습되었기 때문에 평가 데이터셋의 데이터가 유츌되었을 수 있다
-> augmentation 방법으로 성능이 향상된건지, 데이터 유출로 인해서 성능이 향상된건지 알 수 없다
Performance gains observed may not reflect the quality of the data augmentation methodology itself
preventing leakage 를 위해서 model-centric 과 data-centric prevention 구조를 설계
Model-Centric Leakage Prevention
Stable Diffusion model 의 weights 에서 benchmark datasets 의 concepts 을 제거

“Erasing Concepts from Diffusion Models (ICCV 2023)” 에서 제안하는 방법을 사용
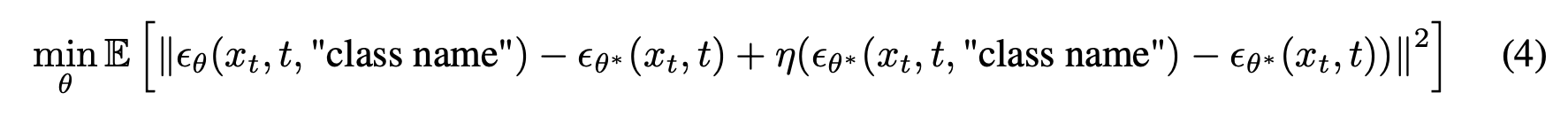
benchmark datasets 에 있는 class name 을 기반으로 concepts 을 제거
Data-Centric Leakage Prevention
model-centric defense 는 cost 가 많이 소요 (single class 처리하는데 V100 GPU 에서 약 2시간 소요)
model inputs 으로 들어가는 text 에서 benchmark datasets 의 class name을 제거
Augmentations For Unseen Concepts
Data-Centric defense 로 class name 없이 어떻게 생성할 것인지

Adapting The Generative Model
“An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion (ICLR 2023)” 에서 제안된 Texutal Inversion 을 활용
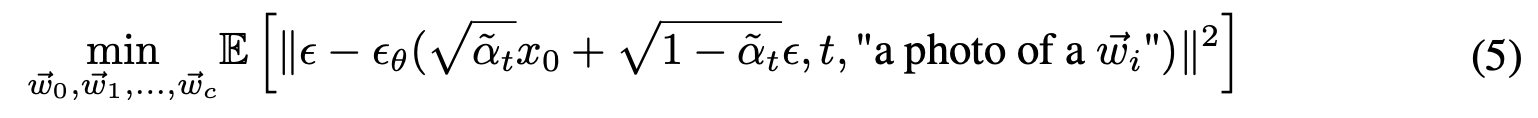
Text encdoer, diffusion models 은 고정하고 class word 부분을 학습 가능한 embeddings 으로 하여 해당 부분이 학습되도록 diffusion model 학습 과정을 진행
결론적으로, text encoder 는 생성하고자 하는 학습 데이터셋의 concepts 을 표현하는 word 를 학습하지 않았더라도 해당 과정을 통해서 생성하고자하는 word의 embedding 값을 학습할 수 있다
Textual Inversion 은 다른 것으로 바꿀 수 있으며, 성능을 더 향상 시킬 수도 있을 것이다라고 설명
Textual Inversion can easily be swapped out with one of these, and the quality of the augmentations from DA-Fusion can be improved
Generating Synthetic Images
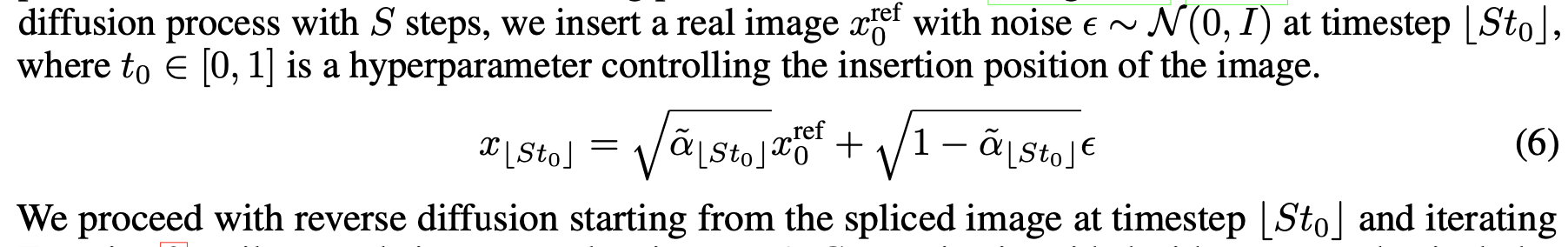
random noise 로 부터 바로 생성하지 않고 real image 로 guide 를 주어서 생성
timesetp $St_0$ 에서의 nosie 가 추가된 real image 로 부터 reverse diffusion 을 시작
본 논문에서는 $t_0 = 0.5$
Balancing Real & Synthetic Data

$N$ 개의 이미지에 대해서 각각 $M$ 개의 augmented images 를 생성
batch 를 구성할 때 probability $\alpha$ 를 기반으로 real image 와 synthetic image 를 구성
본 논문에서는 $\alpha = 0.5$
Improving Diversity With Randomized Intensity
Diversity 를 더 향상시키기 위해서 이미지를 생성할 때 reverse diffusion 을 시작하는 timestep 을 다양하게 가져간다

$k = 4$ 로 세팅하여 다양한 $t_0$ 를 random sampling 하고 여러 reverse diffusion 시작점에서 다양한 이미지들을 생성
Experimental Results
Data Preparation
Leafy Spurge
weed recognition task (잡초)

해당 데이터셋은 Stable Diffusion model 학습 data 에 포함되어 있지 않다고 설명
To our knowledge, top-down aerial imagery of leafy spurge was not present in the Stable Diffusion training data
PascalVOC & COCO
object detection task 에 해당하는 데이터셋을 classification task 데이터셋으로 활용
segmentation mask 를 기준으로 가장 큰 object 에 해당하는 class 를 해당 이미지의 class로 부여
Results
Classifier - ResNet 50
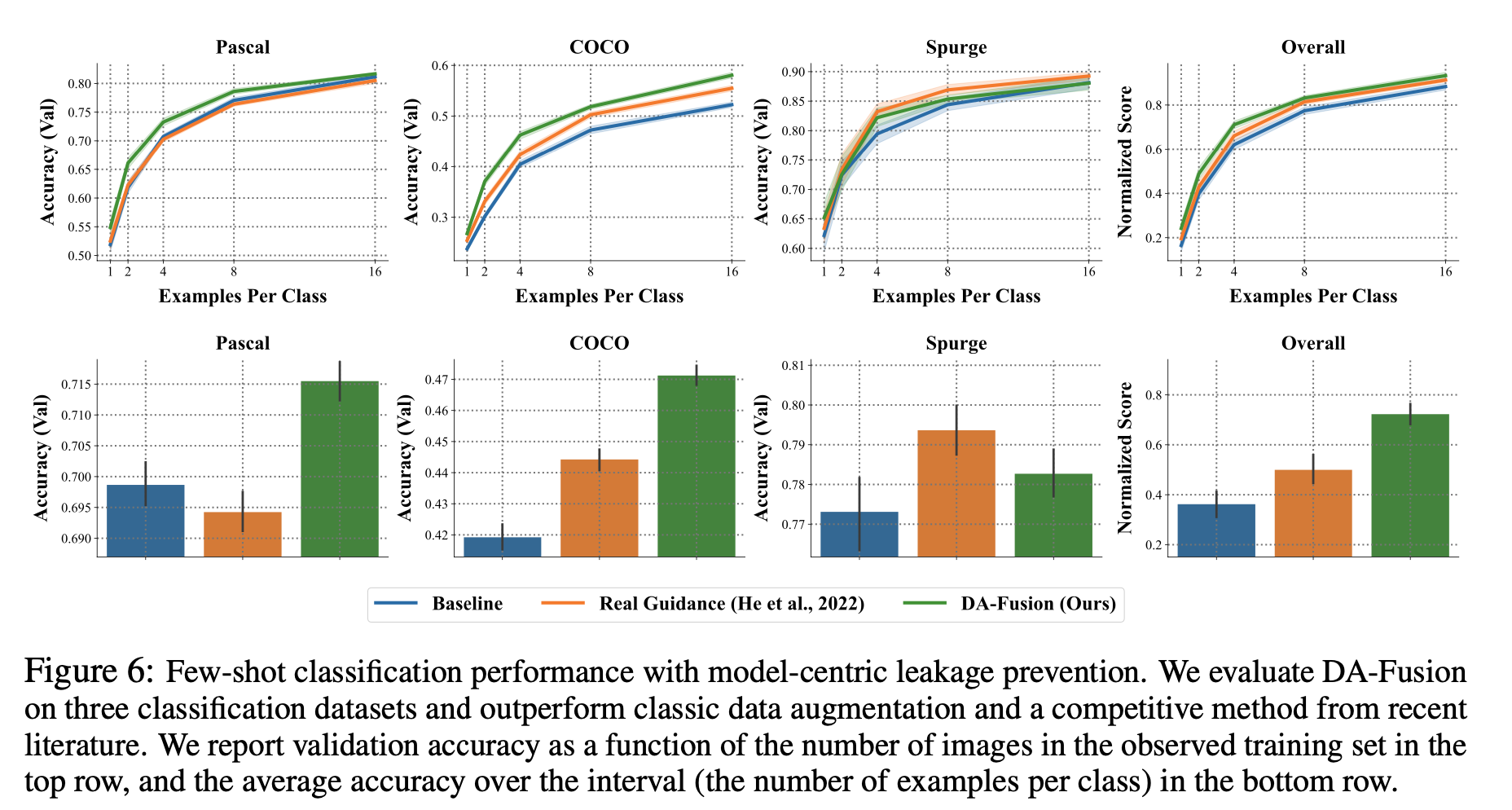
model-centric leakage prevention 에 대한 실험 결과
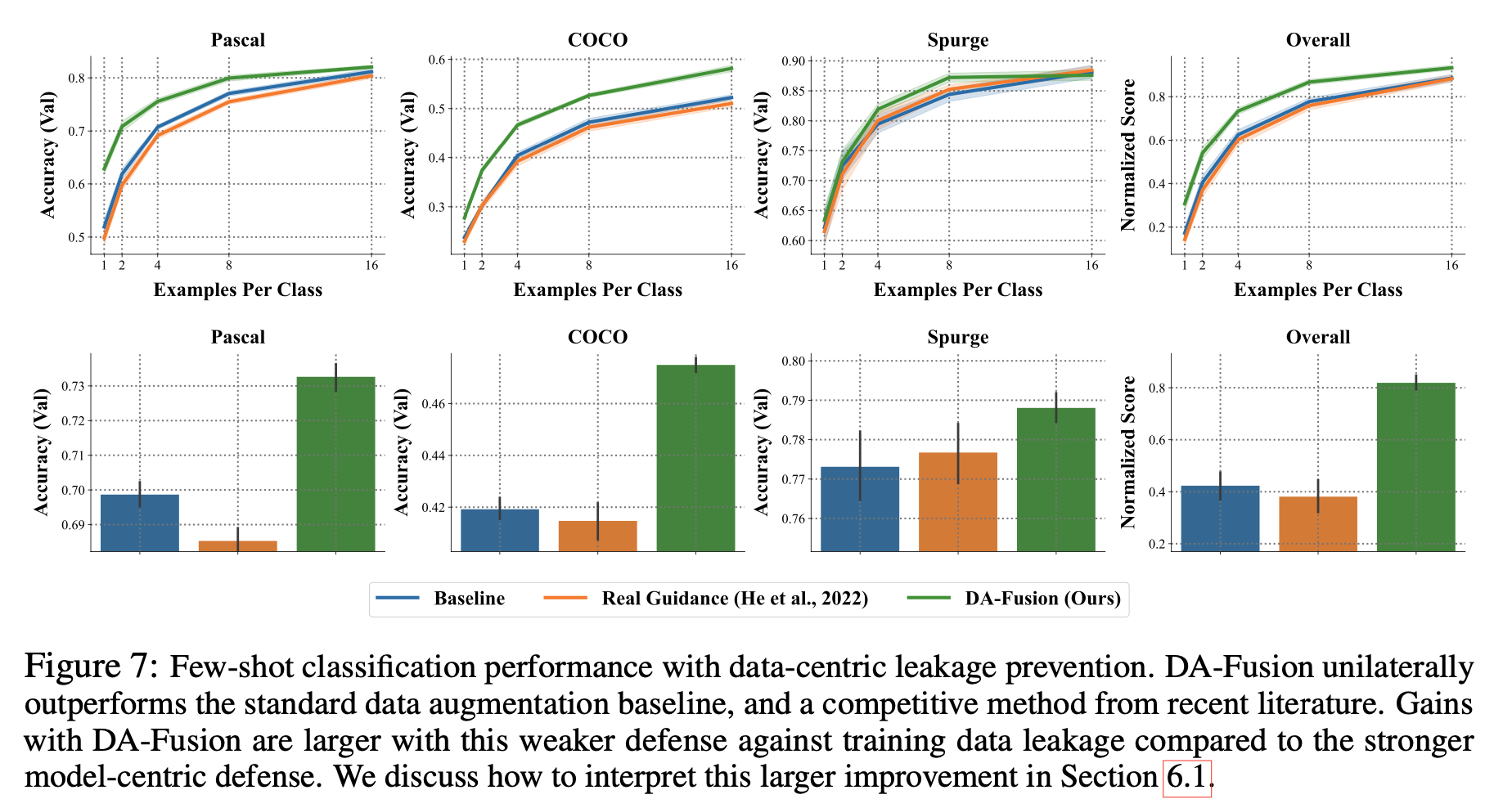
data-centric leakage prevention 에 대한 실험 결과
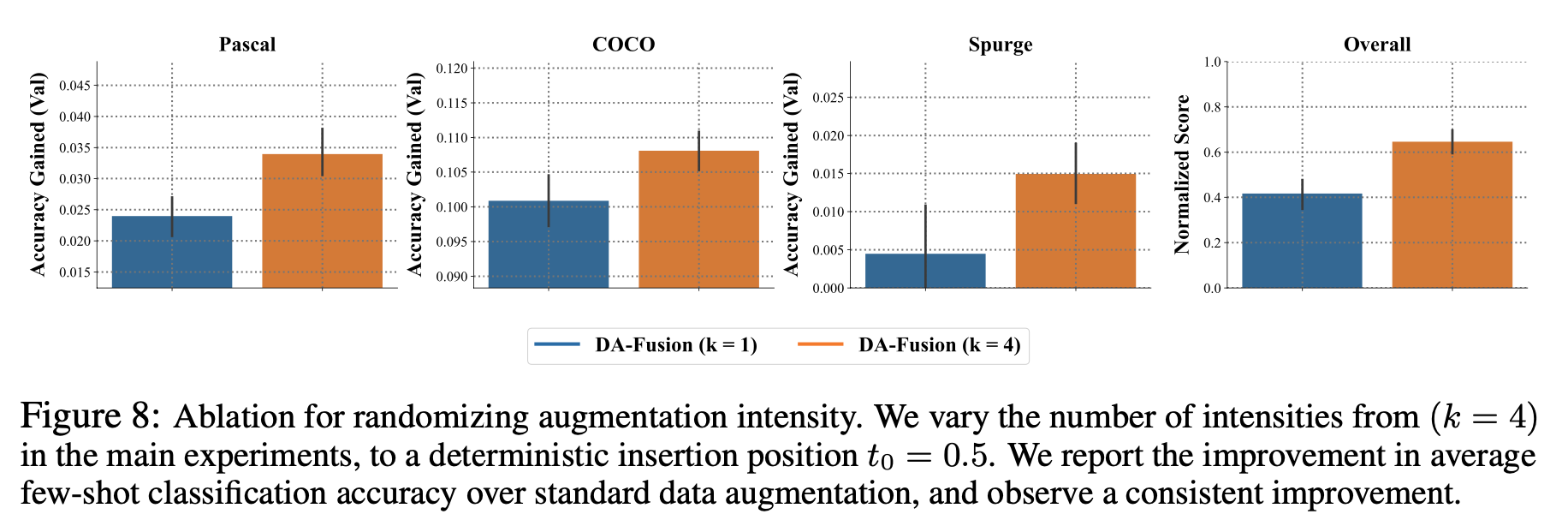
reverse diffusion 시작 timestep 을 고정으로 주었을 때와 다양하게 주었을 때 ablation study
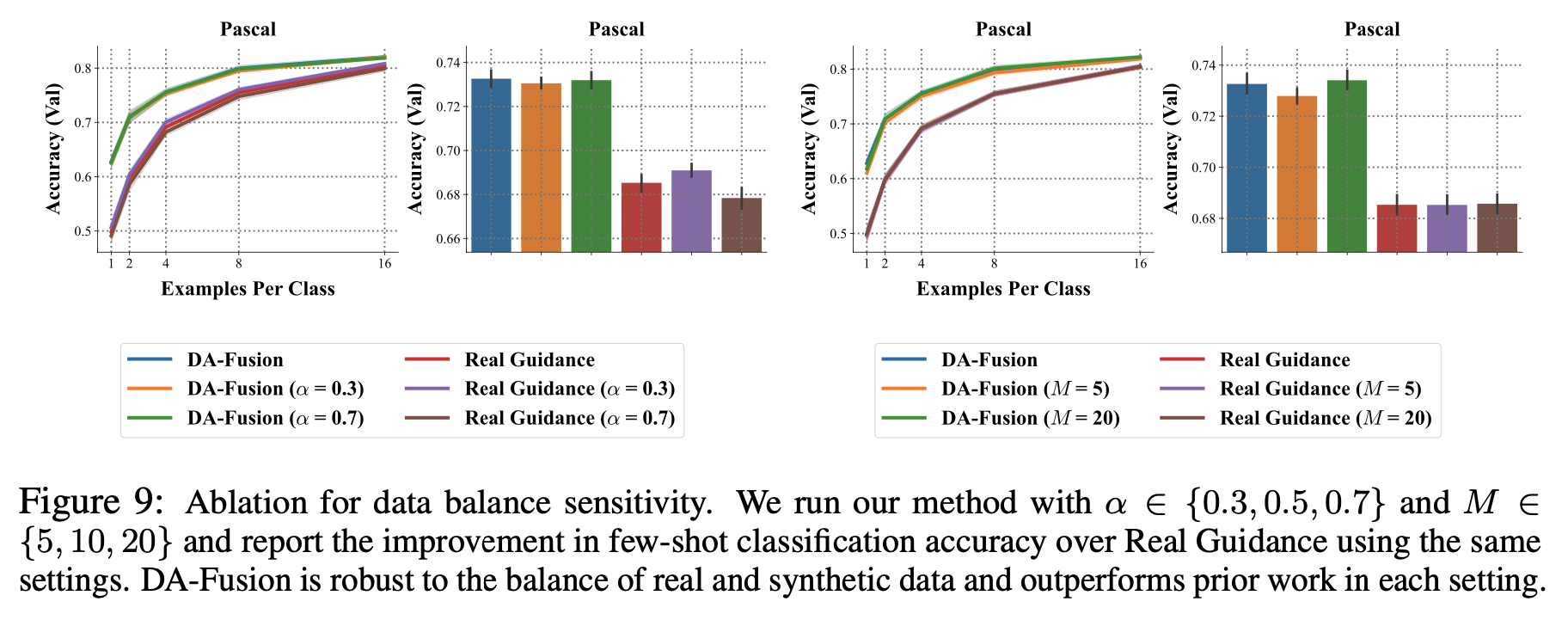
batch 구성할 때 비율, 이미지당 synthetic image 를 생성하는 수에 대한 ablation study