Data Augmentation for Object Detection via Controllable Diffusion Models
Data Augmentation for Object Detection via Controllable Diffusion Models
WACV 2024, 2024-02-26 기준 3회 인용
Task
- Object Detection
- Generation
- Diffusion
Contribution
- Diffusion based synthetic images 으로 data augmentation 을 하겠다
- Visual priors 으로 contraollable diffusion models 를 설계
- CLIP 모델을 기반으로 post-filtering
Proposed Method
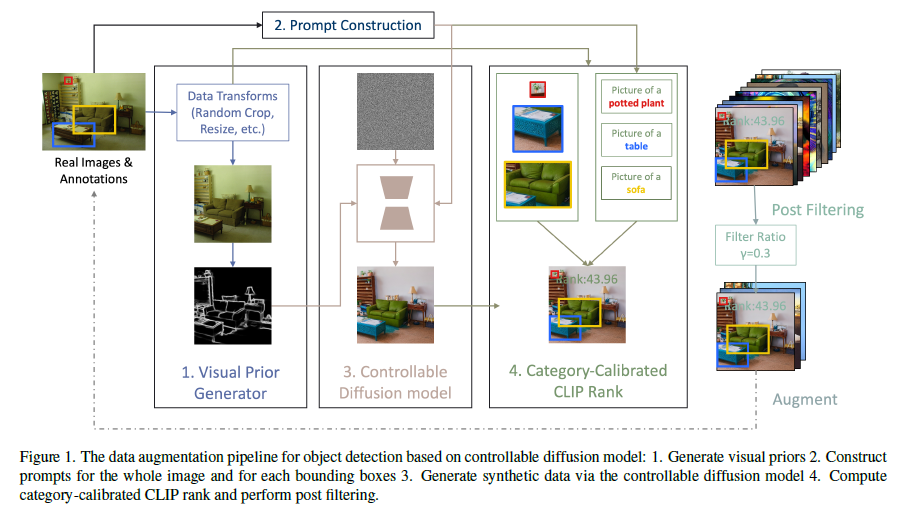
제안하는 구조의 전체 Overview
Visual prior generator
$N$ 개의 image-annotation pairs $(x_i, y_i)^N_{i=1}$ 에서 M 개의 pairs 를 radom select
M개의 pair 에 대해서 visual prior 를 구한다
visual prior extractor 로는 HED edge detector 를 사용
visual diversity 와 bounding box quality 를 위해서
Prompt constructor

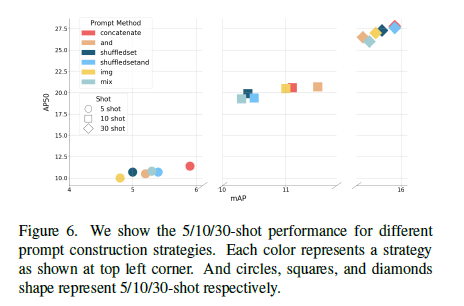
Object 내의 class 를 simple 하게 concatenate 해서 사용했을 때 성능이 가장 좋았음
Contraollable Diffusion Model
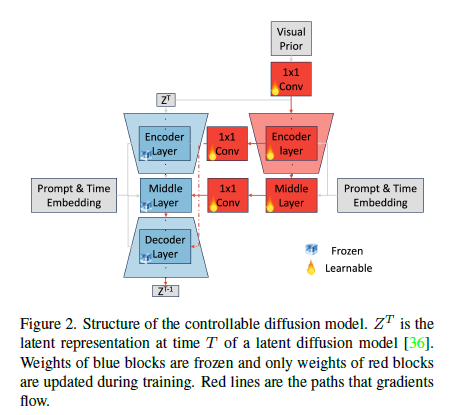
Adding conditionalcontrol to text-to-image diffusion models 논문 방법을 사용
Visual prior 를 처리하는 부분만 learnable 로 하고 해당 정보를 skip connection 으로 넣어주는 형식
Post Filter with Category-Calibrated CLIP Rank
CLIP simliarity score 를 활용
$S^k_j = CLIP(\hat x^k_j, p^k_j)$
bounding box 으로 crop 된 이미지와 object class 의 text prompt 에 대한 CLIP simliarity score
생성된 이미지의 내의 bounding box 들에 대해 cropping 하고 $k$ 개의 class 에 대해 score 계산
해당 score 들에 대한 평균을 사용하여 sorting
filtering ratio $\gamma$ 만큼 사용
Experimental Results
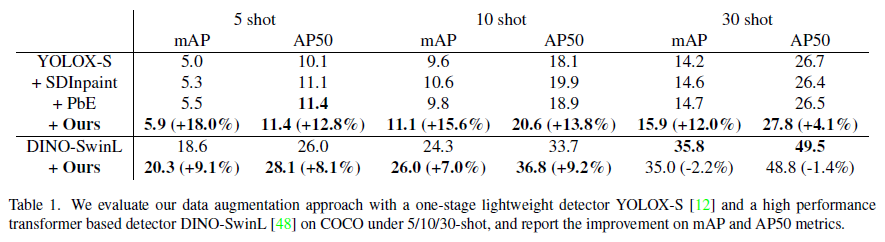
Few-Shot Object Detection (FSOD) setting 으로 실험
제안하는 방법으로 data augmentation 을 진행했을 때 성능 향상
available shot 이 증가할 수록 제안하는 방법의 성능이 하락하는 이유
데이터의 수가 적을 때에는 bounding box 에 완전히 fitting 하지 않는 생성된 object 일지라도 생성에 도움을 주지만 데이터의 수가 많아지면 일반 GT 가 더 좋다
This is because when the data size is limited, synthetic objects with loosely fitting bounding boxes can still yield favorable results for the model.
However, as the amount of real data grows, the accuracy of the ground truth bounding box becomes crucial, and the loose bounding boxes in synthetic data may even cause a performance degrade
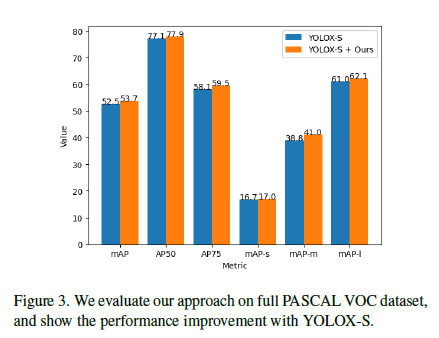
full PASCAL VOC 에 대해서는 향상
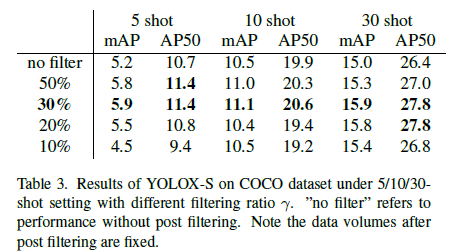
Post-Filtering 이 필요한 것이 맞는건가..?