LLMs Meet VLMs: Boost Open Vocabulary Object Detection with Fine-grained Descriptors
LLMs Meet VLMs: Boost Open Vocabulary Object Detection with Fine-grained Descriptors
ICLR 2024 , 2024-04-01 기준 0회 인용
Task
- Object Detection
- Open Vocabulary Object Detection (OVOD)
Contributions
- 기존 방법들은 VLM knowledge 를 활용해서 open-vocabulary object detection 성능을 향상
- 하지만 categorical labels 에 대한 것만 사용하고 fine-grained text description 은 활용하지 않음
- LLM 을 활용한 descriptors 를 기반으로 설계된 Descriptor-Enhanced Open Vocabulary Detector (DVDet) 구조를 제안
Motivation
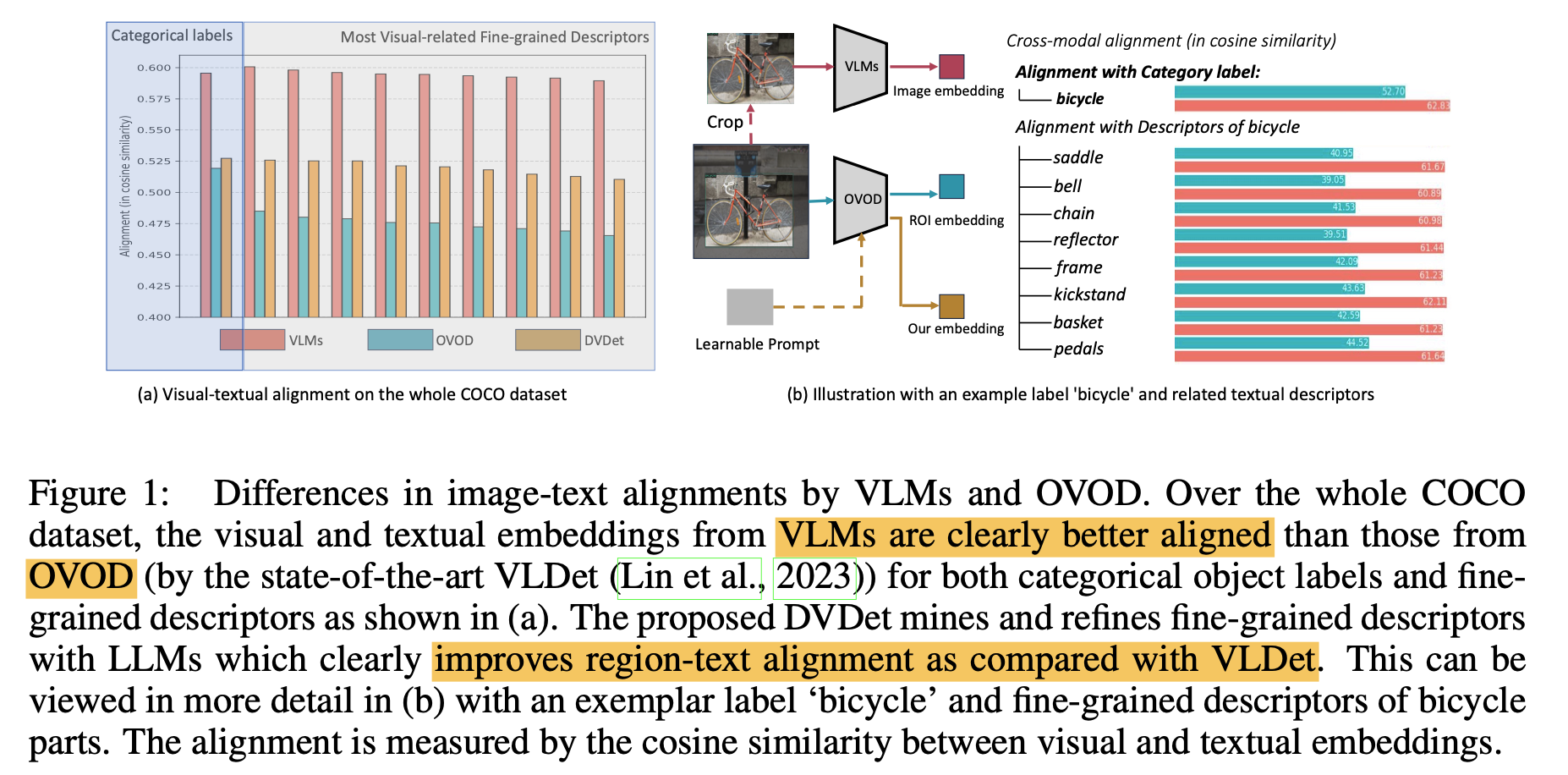
VLM 과 기존의 OVOD 방법의 image-text alignments (cosine similarity)
VLM 은 category label 과 descriptors 와의 similarity 가 대부분 높다
기존의 OVOD 방법은 category label 과의 similarity 에 비해서 다른 descriptors 와의 similarity 는 현저히 낮다
제안하는 DVDet 구조는 기존 OVOD 방법보다 향상된 값들을 보여준다
Proposed Method

OVOD Problem setup
visual backbone encoder, class-agnostic region proposal network (RPN), open vocabulary classification module 로 구성
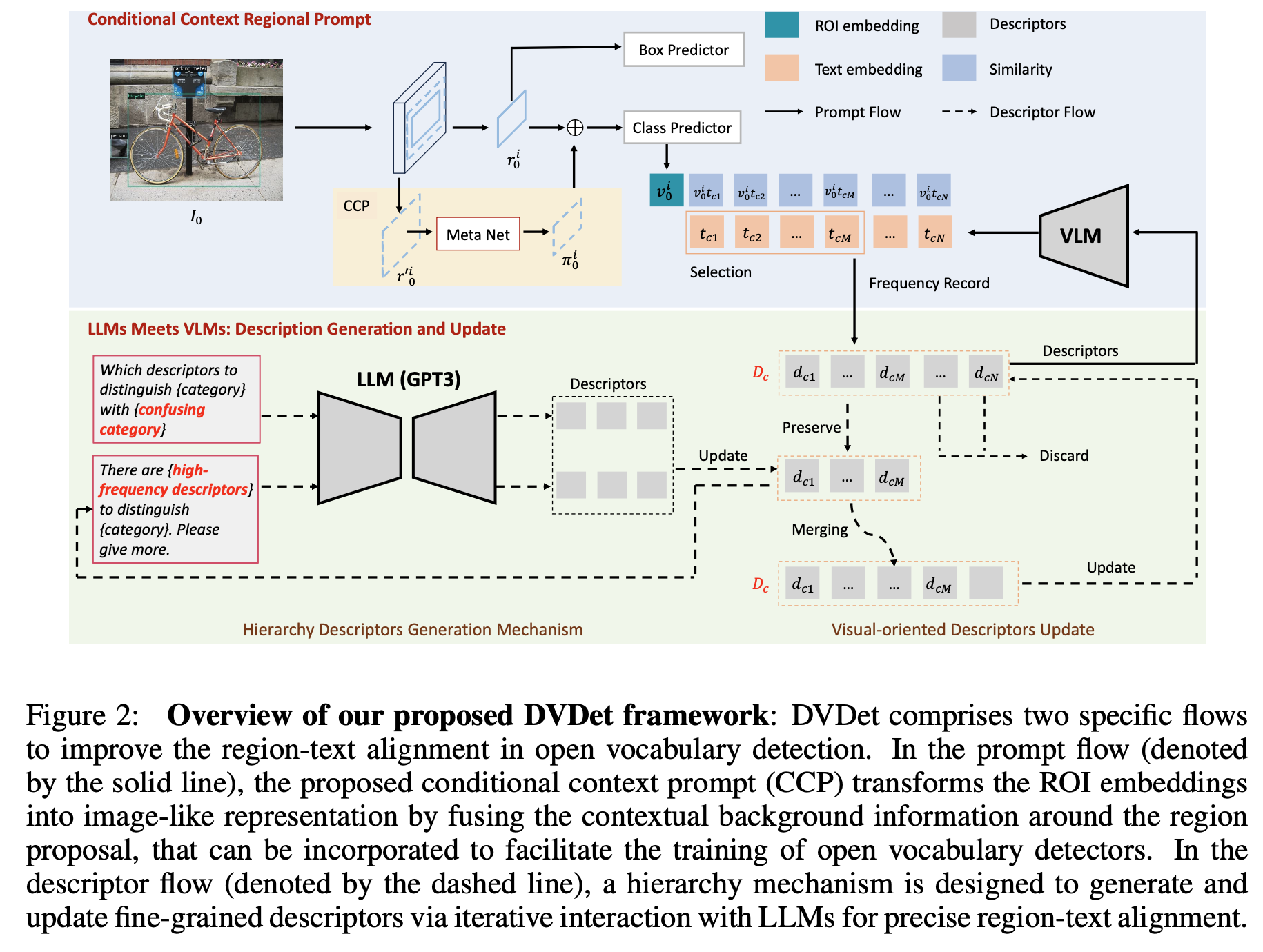
Conditional Context Regional Prompts
bridge the gap between pretrained foundational classification models and downstream detection tasks
foudation classification models 와 detection task 의 gap 을 줄이기 위해서
Conditional Context Regional Prompts method (CCP) 구조 제안

region proposal 된 것에서 constants $m, n$ 으로 region 을 expand
convolutional layers 로 구성된 meta-network 로 regional visual prompt $\pi^i_0$ 를 계산
visual prompt 를 RoI feature 에 더해주고 Class predictor 로
LLMs Meets VLMs
Descriptors Initialization

각 class 별로 $K$ 개의 descriptors 를 생성
“Visual Classification via Description from Large Language Models” 논문 방법으로 Initialization


GPT-3 로 해당 category name 에 대한 description 생성
Descriptors Record
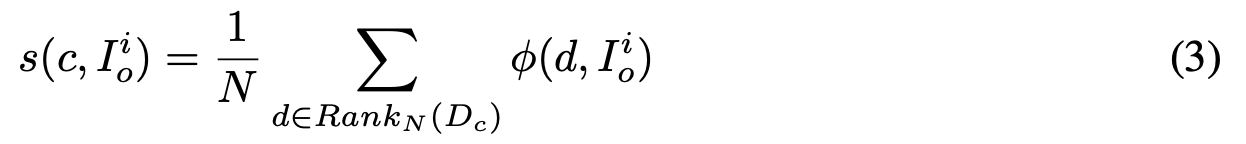
class predictor 를 통과한 값과 category name 별 descriptor 와의 similarity 계산
각 category 별로 해당 region 과 similarity 가 높은 top-N 개 추출
N 개의 평균값이 가장 높은 category 가 prediction 결과
이때 각 category 별로 사용되는 descriptor N 개를 record
추가적으로 예측된 category 가 잘못되었을때를 record, confusing 하는 categories 저장
confusing categories with high misclassification probability
Descriptors Hierarchy Generation and Update
$N$ iteration 마다 진행
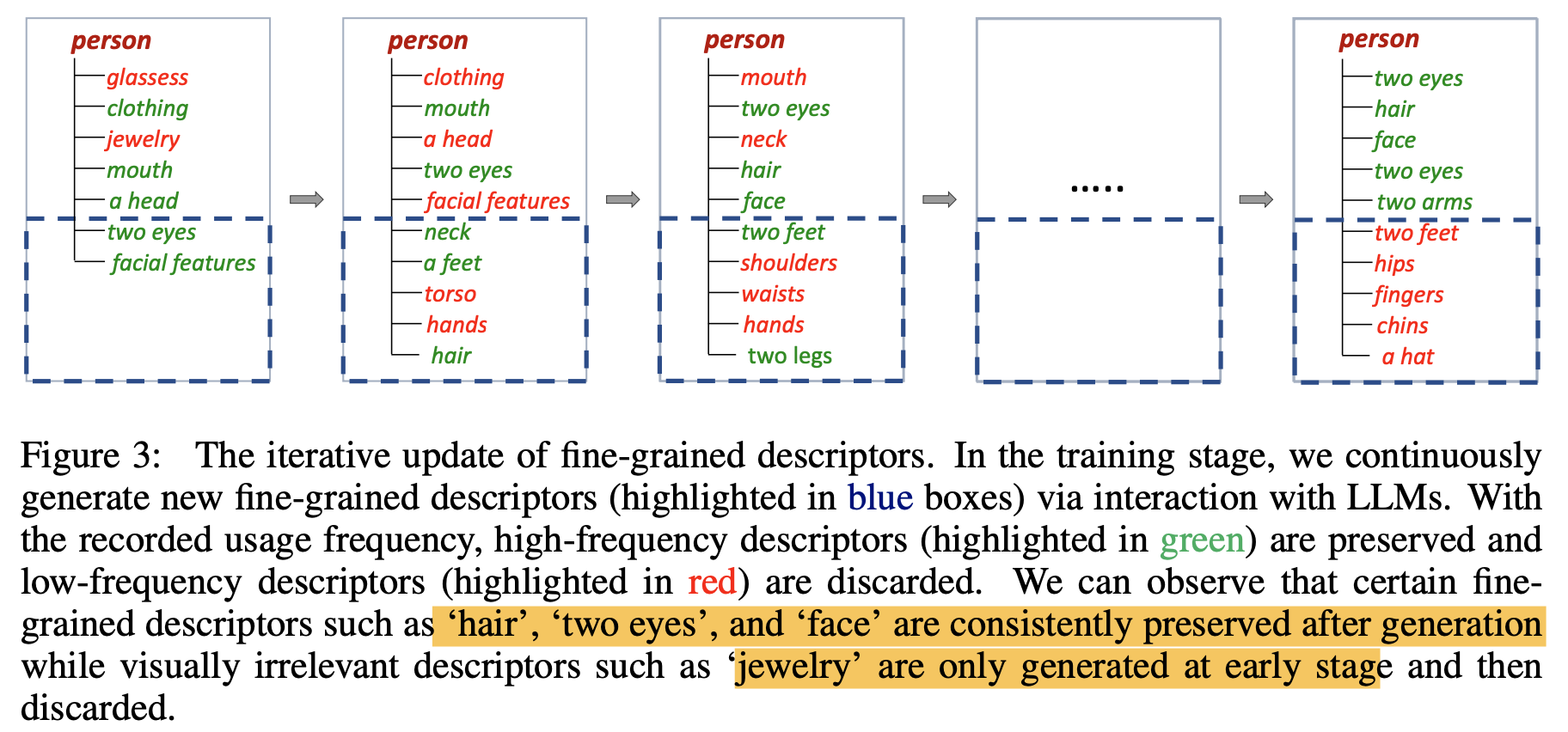
category 별로 사용된 frequency 가 낮은 descriptor 는 버리고 높은 것만 유지

그리고 많이 사용된 descriptors 로 질문지를 만들어서 새로운 descriptors 를 생성
confusing category 로도 질문지를 만들어서 descriptors 생성
새로 생성된 descriptors 가 기존에 존재할 수 있기 때문이 cosine similarity $s_{ij} > \lambda$ 를 비교해서 merge
$t_j = \alpha t_i + (1-\alpha) t_j$
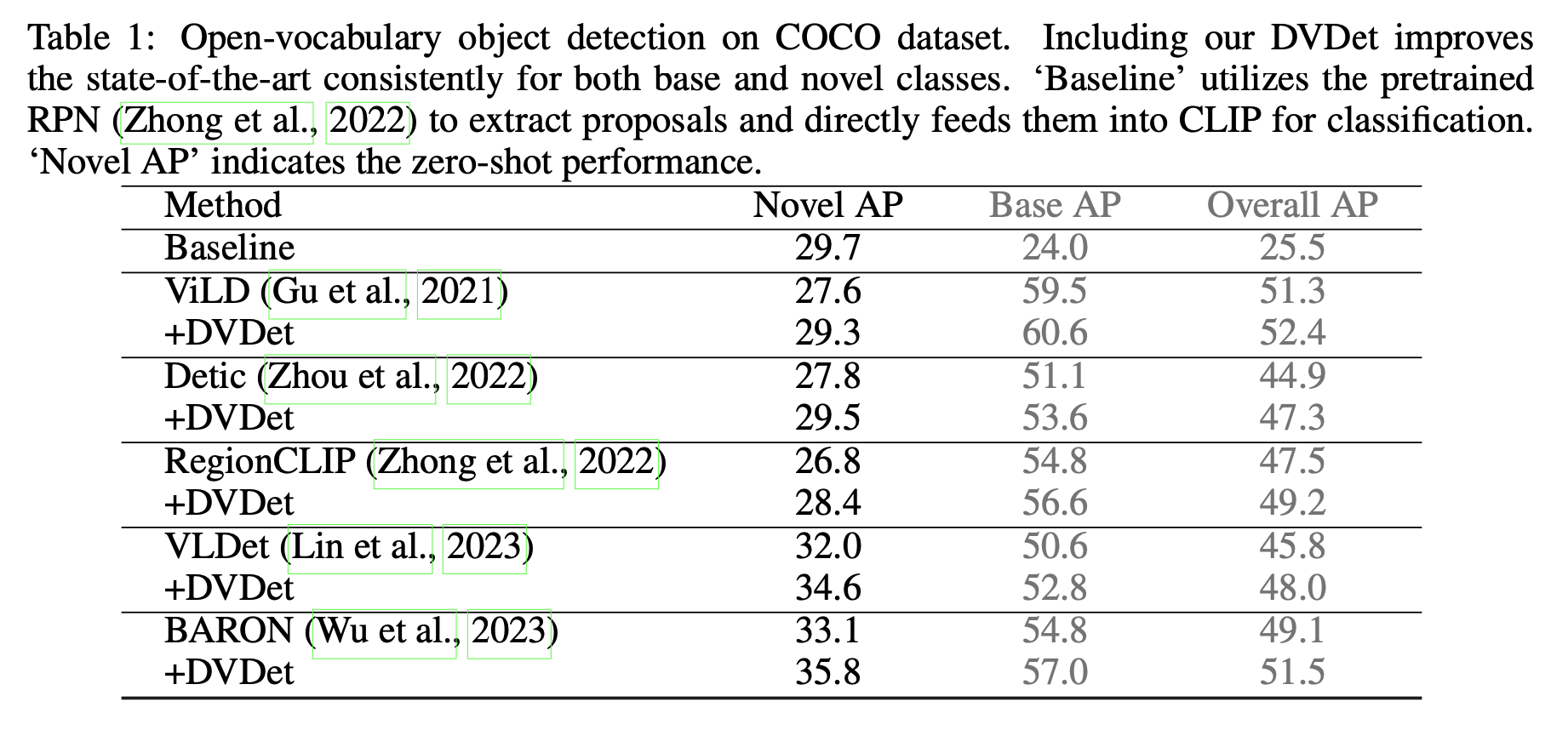
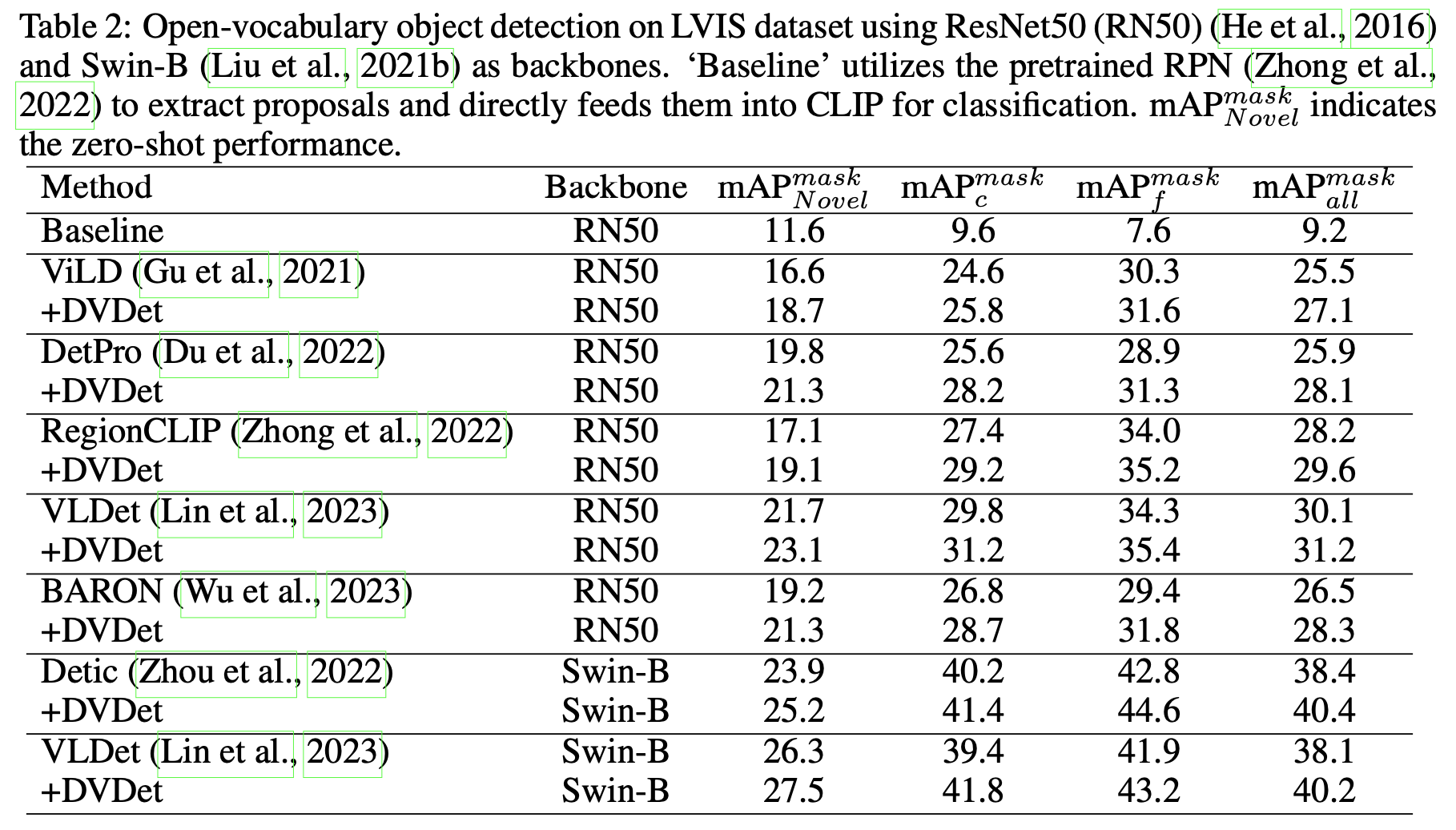
Experimental Results