Efficient Decoder-free Object Detection with Transformers
Efficient Decoder-free Object Detection with Transformers
ECCV 2022, 2024-04-23 기준 10회 인용
Task
- Object Detection
- Transformers
Contribution
- DETR 의 등장은 많은 hand-designed componets 를 제거했지만, decoder stage를 위한 긴 학습시간과 더 큰 GFLOPs 를 필요로하게 되었다.
- Decoder-Free Fully Transformer (DFFT) 구조를 제안
- Encoder-only single-level anchor-based dense prediction problem
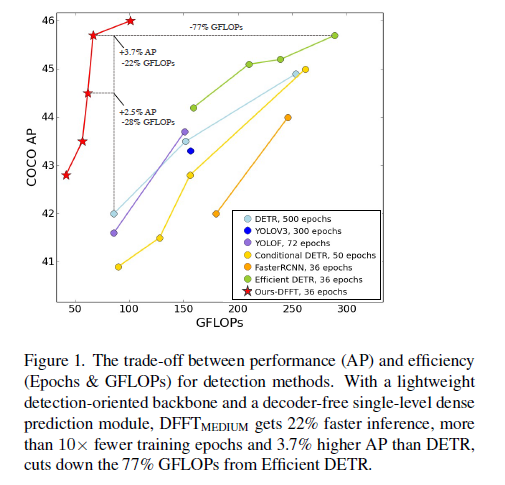
GFLOPs 를 크게 줄이면서 성능도 향상시켰다
Proposed Method
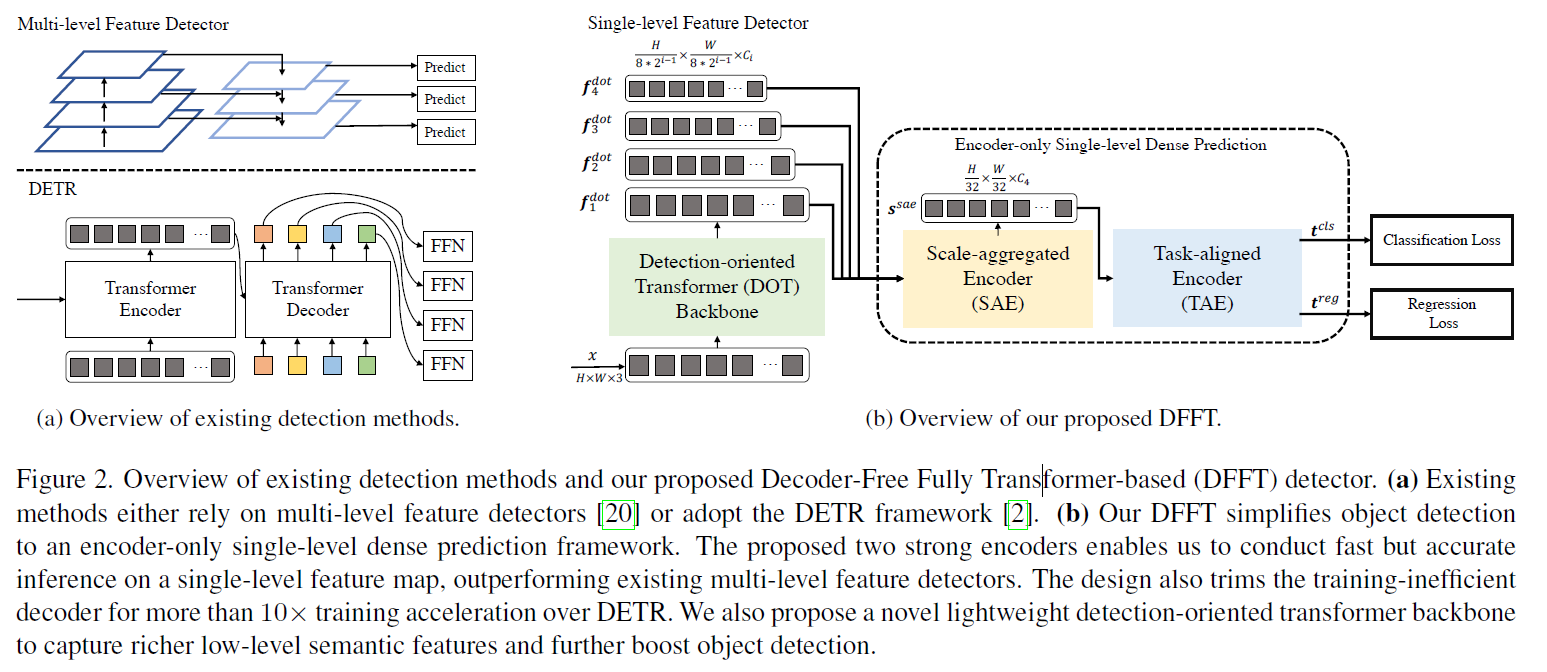
Detection-oriented Transformer Backbone
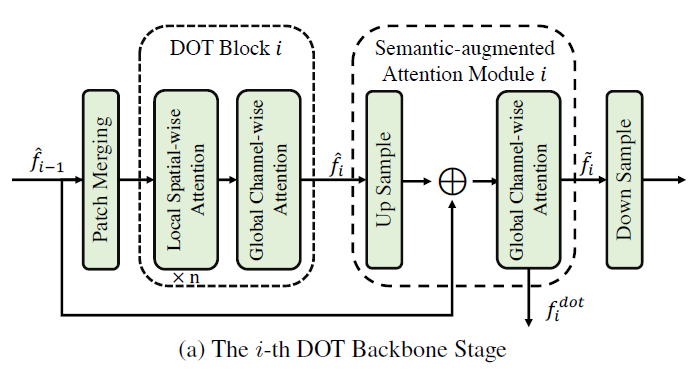
Backbone 으로 DETR 처럼 CNN을 사용하는 것이 아닌 Transformer Block 기반 Detection-oriented Transformer (DOT) 구조를 제안
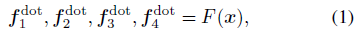
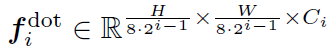
$F(x)$ 는 DOT Backbone function
stage 가 진행될 수록 downsample
$x \in \mathbb{R}^{H \times W \times 3}$
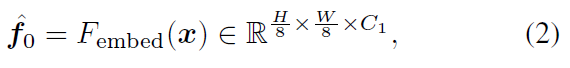
입력 이미지 $x$ 로부터 patch embedding
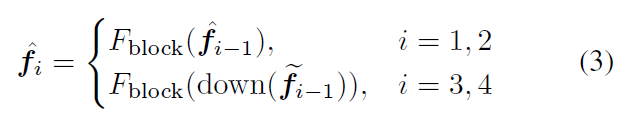
DOT Block
Local Spatial-wise Attention → SW-MSA (shifted window multi-head self-attention)
Global Channel-wise Attention - Query, key, value 를 transpose 해서 channel-wise 로 attention 되도록 → object semantic 정보를 파악
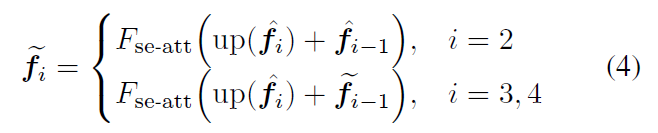
Semantic-Augmented Attention (SAA) block
2, 3, 4 stage에서만
연속되는 stage feature에 대해서 연산하는 block
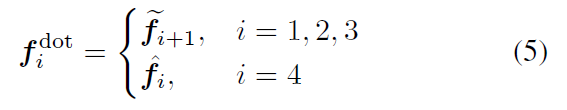
Encoder-only Single-level Dense Prediction
Scale-aggregated Encoder
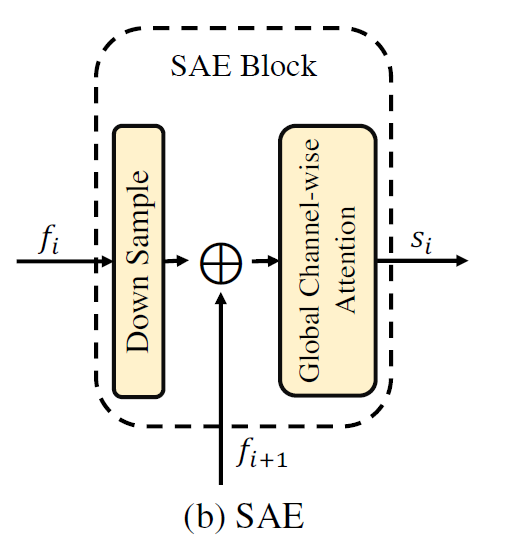
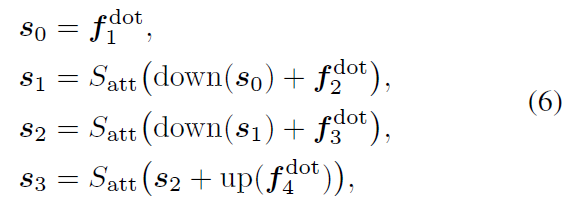
각 stage 에서의 서로 다른 scale 의 feature를 하나로 aggregation
stage 3 의 scale 인 H/32, W/32 으로
Task-aligned Encoder
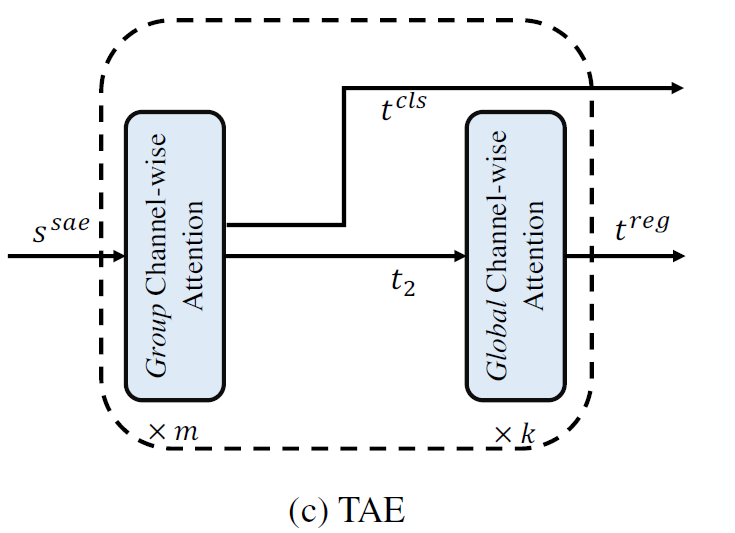
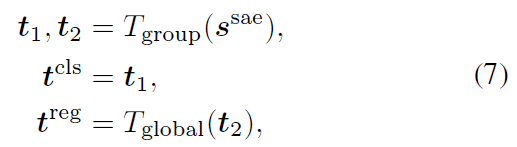
Group Channel-wise Attention (Code 기반)
- Global Channel-wise 와 거의 동일
- Attention 후 1x1 Conv 에서 group = 2 로 설정해서 연산
- Global Channel-wise 일반적인 1x1 Conv
그 후에 split
$t_1, t_2 \in \mathbb{R}^{\frac{H}{32} \times \frac{W}{32} \times 256}$
$t_1$ 에는 3x3 Conv 으로 anchor 개수 만큼으로 조절 - num_anchor X num_class X H/32 X W/32
$t_2$ 는 fc layer 로 512 로 채널수 키워준 후 3x3 Conv → num_anchor X 4 X H/32 X W/32
YOLOF 에서 제안한 uniform matching strategy 를 사용해서 학습
Experimental Results

GFLOPs 를 굉장히 크게 줄이며 좋은 성능을 보여준다
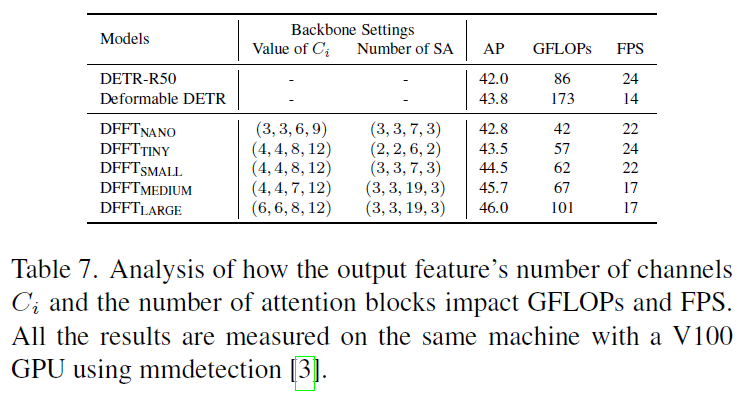
GFLOPs와 FPS 는 상관관계가 아니다