DETRDistill: A Universal Knowledge Distillation Framework for DETR-families
DETRDistill: A Universal Knowledge Distillation Framework for DETR-families
ICCV 2023 , 2024-01-09 기준 5회 인용
Task
- Object Detection
- DETR
- Knowledge Distillation
Contribution
- DETR-families 를 위한 knowlege distillation method 를 제안
- Hungarian-matching logits distillation
- Target-aware feature distillation
- Query-prior assignment distillation
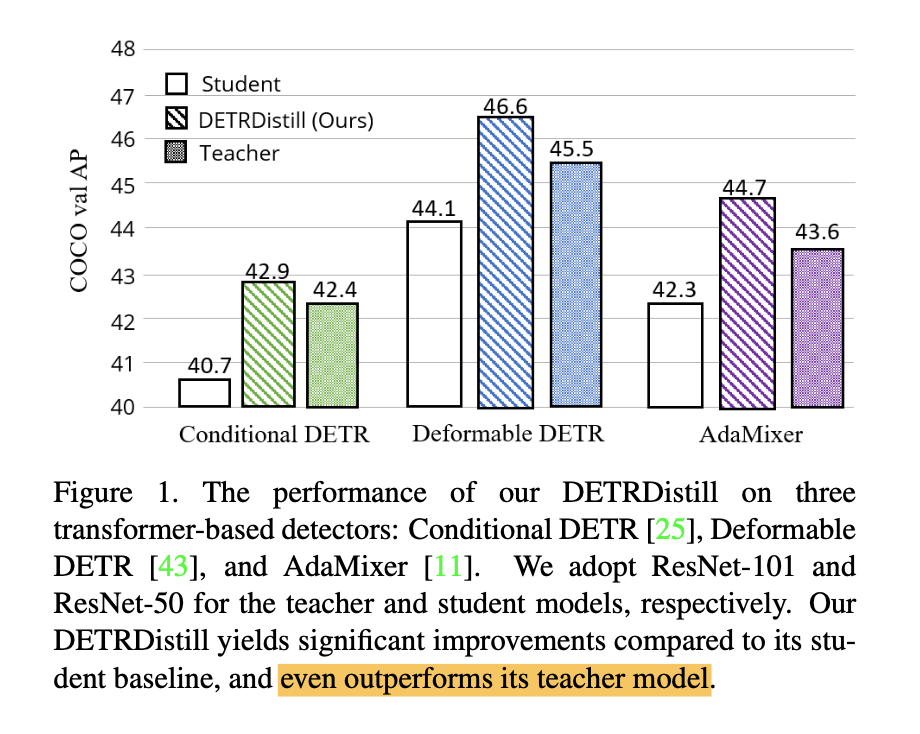
Teacher: ResNet-101
Student: ResNet-50
본 논문에서 제안하는 방식으로 DETR 방법들에 대해서 KD를 적용했을 때 Teacher 를 뛰어넘는 Student 성능을 보여준다
Proposed Method
Analyze KD methods desigend for convolution-based detectors
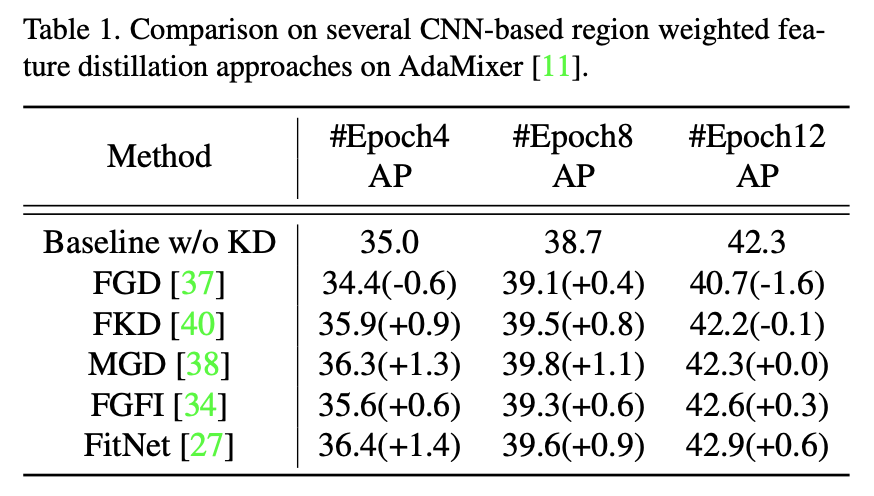
기존의 convolution-based detectors에서 제안된 KD 방법들을 AdaMixer 에 적용했을 경우 성능이 오히려 떨어지거나 크게 향상되지 않는다
logits-level distillation methods
DETR 방법들은 decoders 으로 인해서 unordered 상태로 box predictions이 된다
Teacher의 predictions과 Student의 predictions을 one-to-one으로 대응하기가 어렵다
no natural one-to-one correspondence of predicted boxes between teacher and student for a logits-level distillation
feature-level distillation methods
generation mechanism being different between convolution and transformer
feature 생성하는 mechanism 이 convolution 과 transformer 가 서로 다르다

Therefore, directly using previous feature-level KD methods for DETRs may not necessarily bring performance gains
이전의 feature-level KD 방법으로는 DETR에 바로 적용하기에 무리가 있다
Overview
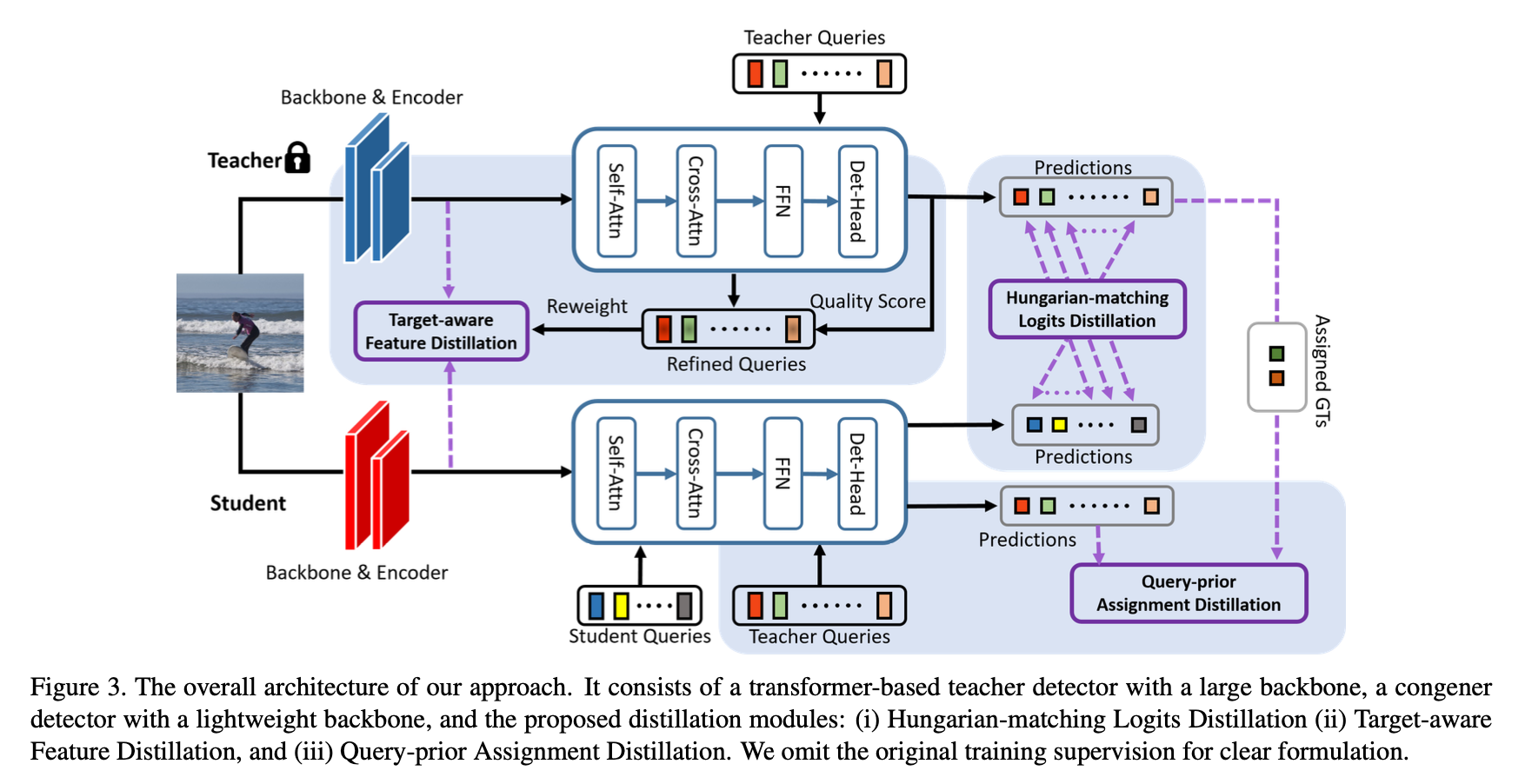
Hungarian-matching Logits Distillation
Teacher의 prediction 결과와 Student의 prediction 결과를 matching
Positive distillation
Since teacher’s positive predictions are target closely related
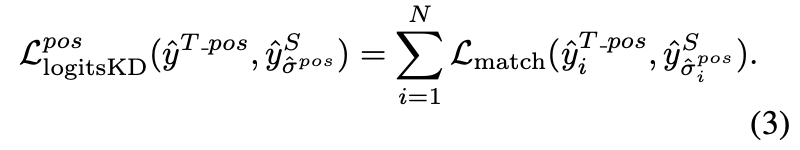
Teacher 에서 positive로 예측된 것들과 Student에서 positive로 예측된 것들과 matching (Teacher model 결과를 pseudo GT 로 활용)
하지만 Teacher model 에서 positive로 예측되는 수가 굉장히 제한적 (이미지에 평균 7개의 positive box가 있기 때문에)
-> 즉, Teacher model 의 수 많은 negative predictions 결과를 무시하는게 된다
Negative distillation
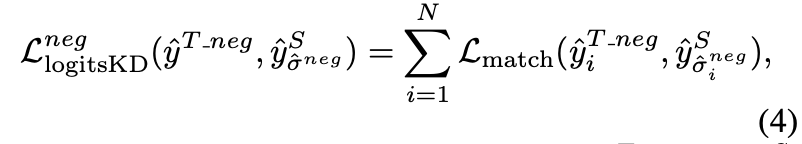
Negative predictions 에도 똑같은 연산을 해준다
matching 하는 과정에서 classification 은 항상 background 이니 제외하고 box에 관해서만 해준다
Target-aware Feature Distillation
teacher model’s knowledge at the feature-level is necessary
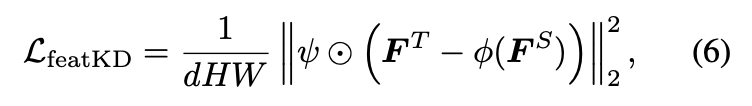
$\boldsymbol{F}^T \in R^{H \times W \times d}$ , $\boldsymbol{F}^S \in R^{H \times W \times d^S}$
Feature-level distillation
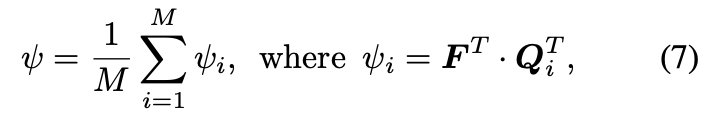
$\psi \in R^{H \times W}$
Teacher model 의 query와 Encoder output feature를 활용해서 selection mask를 생성

하지만 성능 향상이 없었고 저자들은 Figure 4 와 같은 분석을 한다
not all object queries of the teacher should be equally treated as valuable cues
Teacher query 마다 갖고 있는 정보들이 다르며 그것이 항상 valuable cues 는 아니다
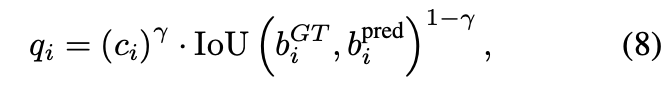
prediction 결과와 GT를 통해 연산한 quality score를 활용
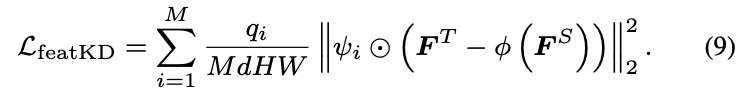
수식 (6) 을 위와 같이 확정하여 사용
Query-prior Assignment Distillation
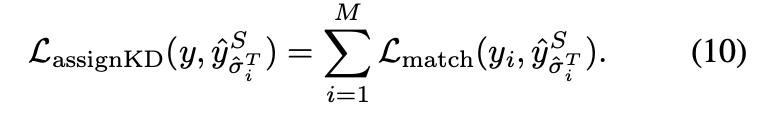
unstable bipartite grpah matching 은 convergence speed를 느리게 한다
-> student 모델도 똑같은 문제를 갖고 있을 것이다
studnet model 에 teacher 의 query를 입력으로 넣고 teacher model 에서의 매칭 조합을 활용해서 Loss 계산
help the student model treat the teacher queries as a prior and encourage the student detector to achieve a stable assignment
이를 통해서 student 모델이 stable assignment를 할 수 있도록 가이드를 받을 것이다
Overall Loss
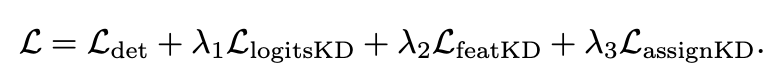
Student model 에 대한 DETR Loss + 본 논문에서 제안하는 KD Loss 3개
Experimental Results
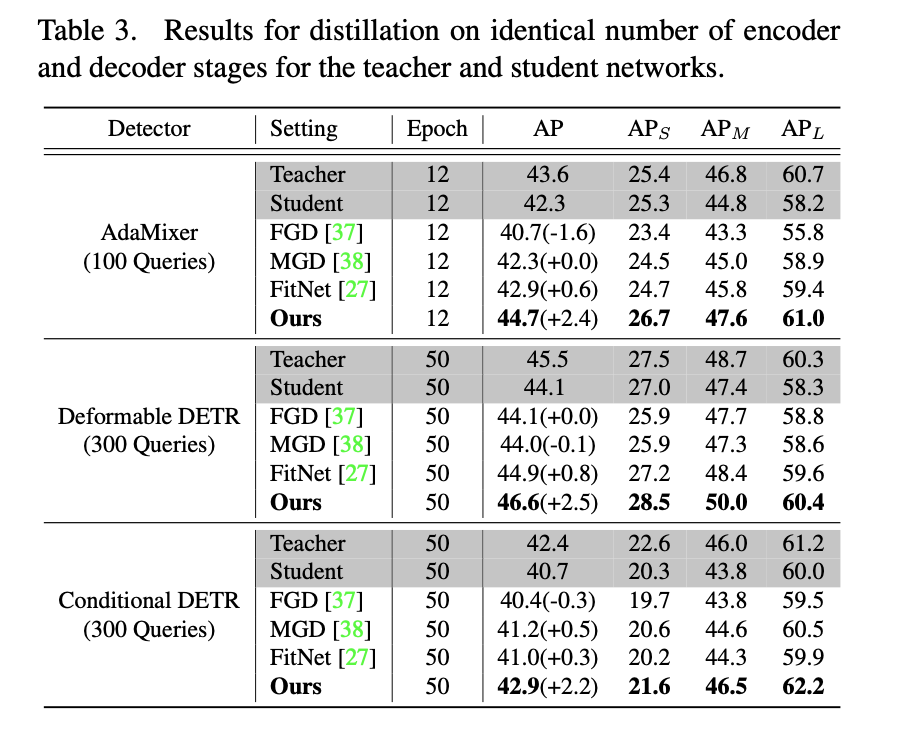
Teacher: ResNet-101
Student: ResNet-50
3가지 DETR (AdaMixer, Deformable DETR, Conditional DETR) 에서 기존의 KD 방법보다 제안하는 방법이 더 좋은 성능을 보여준다
심지어 Teacher의 성능도 뛰어넘는다
Conditional DETR
Teacher: ResNet-101
Student: ResNet-50
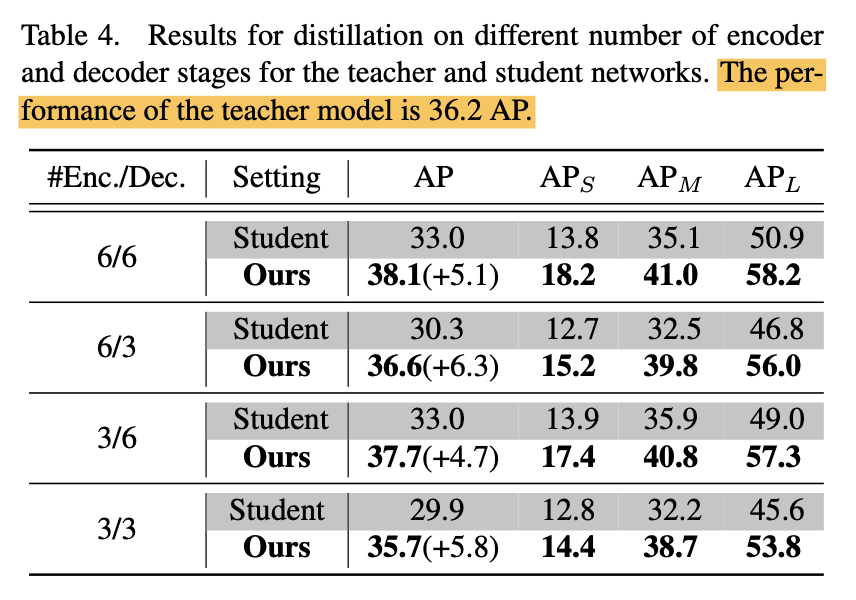
Encoder, Decoder 수에 따른 distillation 실험
저자들은 Encoder 수에 따른 영향은 크지 않다고 설명
student 의 decoder 수를 줄여도 성능을 보존
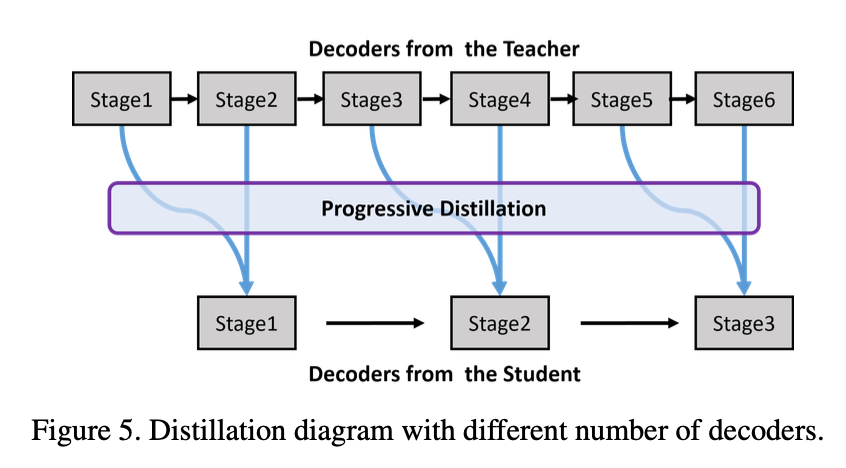
Teacher 모델의 decoder layer 수와 Student 모델의 decoder layer 수가 다를때 distillation 방법
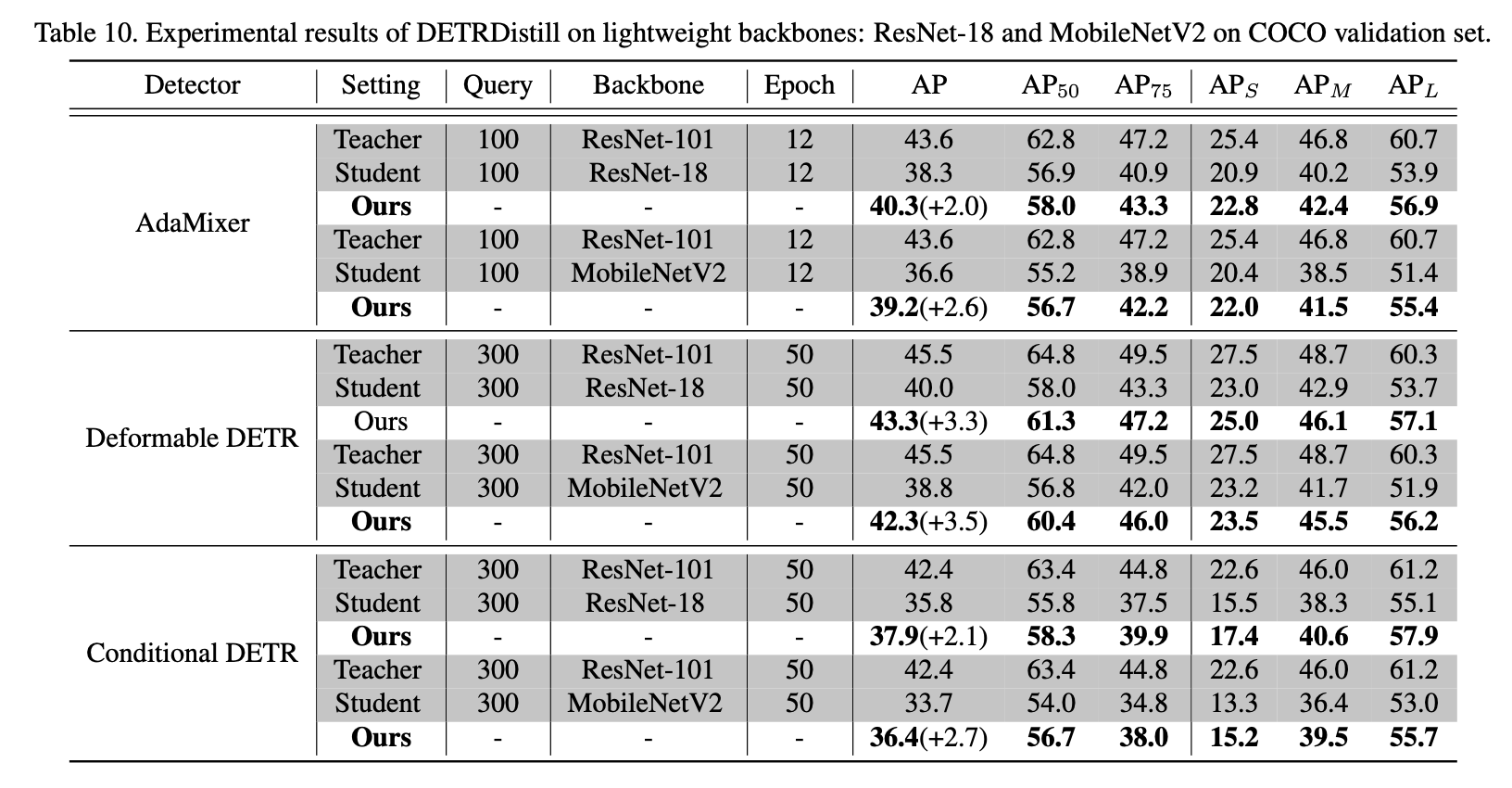
Student 모델의 backbone을 가벼운걸로 사용했을때도 성능을 어느정도 보존