BoxeR: Box-Attention for 2D and 3D Transformers
BoxeR: Box-Attention for 2D and 3D Transformers
CVPR 2022, 2024-02-20 기준 29회 인용
Task
- Object Detection
- DETR
Contribution
- simple attention mechanism Box-Attention 을 제안
- Spatial interaction between grid features 정보 파악 가능
- Box transformerR (BoxeR-2D) 를 제안
3D 에도 적용하지만 2D에 관해서만 다룰 예정
Proposed Method
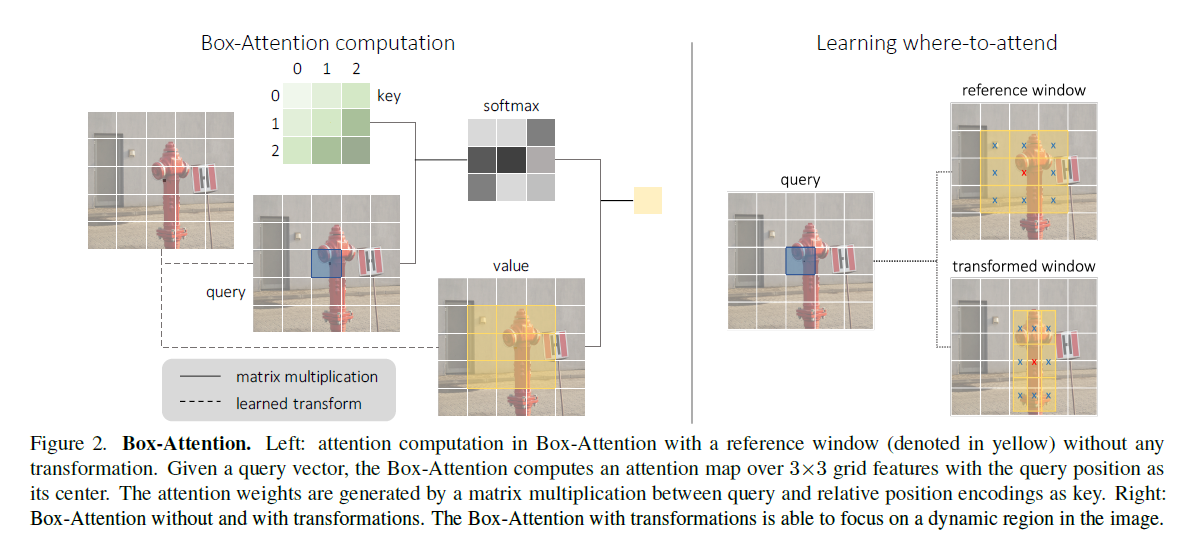
Box-Attention

Query 를 center point 로 두고 size m 으로 reference window 를 생성
–> Value 로 사용
Key 는 $m \times m$ learnable vecotrs 로 구성
queries 끼리는 share
vector represents a relative position in the grid structure, followed by a softmax function.
Where-to-attend
reference window 의 offset 을 학습해서 dynamic 하게 조절

쿼리에 대한 linear projection 을 통해서 offset parameter 를 학습
이를 기반으로 reference winodow 를 transform
our box-attention to effectively attend to necessary regions
BoxeR-2D: A Box Transformer
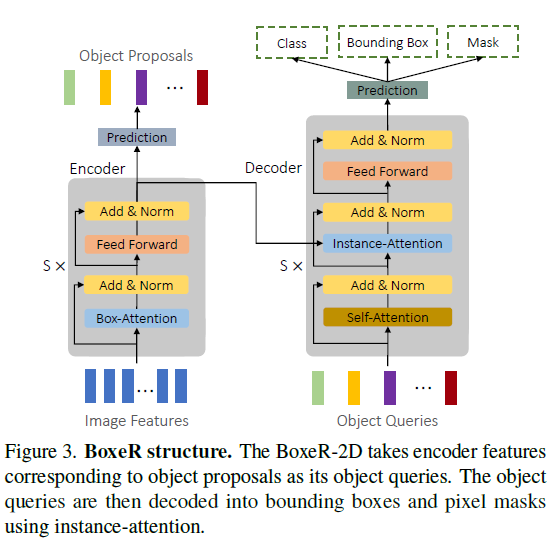
DETR Encoder 부분의 self-attention 부분을 Box-Attention 사용
DETR Decoder 는 여러 DETR methods 와 같이 Encoder 의 output 을 Decoder 의 Input 으로 활용
Decoder 에서는 Encdoer 에서의 Object Proposals 를 reference window 으로 사용
Instance-Attention 을 Box-Attention 과 동일하나 Instance Segmentation 을 위해서 Mask head 가 뒤쪽에 붙어서 Instance-Attention 으로 명칭을 부여한 것 같다
Experimental Results
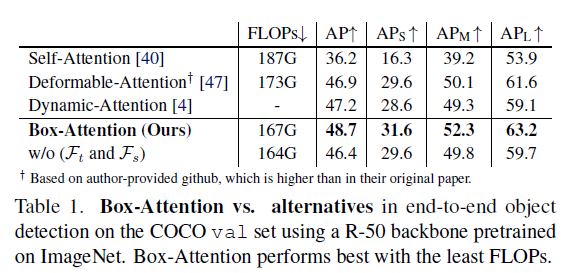
다른 DETR 방법들과 비교했을 때 더 좋은 성능을 보임

DETR 의 Decoder Layer 마다 box 를 refinement 하는 것보다 Box-Attention을 사용해서 attention 할 refernece window를 refine 하는 것이 성능이 더 좋다
Instance segmentation 과 함께 학습했을 때 COCO datasets 의 성능이 향상

COCO test-dev 에 대한 성능
제안하는 방법이 좋은 성능을 보여줌