AlignDet: Aligning Pre-training and Fine-tuning in Object Detection
AlignDet: Aligning Pre-training and Fine-tuning in Object Detection
ICCV 2023, 2024-01-23 기준 1회 인용
Task
- Object Detection
- DETR
Contribution
- 기존의 방법들은 pre-training 과정과 fine-tuning 과정이 서로 불일치하는 문제가 존재한다
- data, model, task 관점에서 discrepancies 가 존재한다
- Pre-training 과정을 image-domain 과 box-domain 으로 two-stage 로 나눈 구조를 제안
- 제안하는 방법을 다양한 Detector 에 적용할 수 있으며, 유의미한 성능향상을 보여준다
Motivation
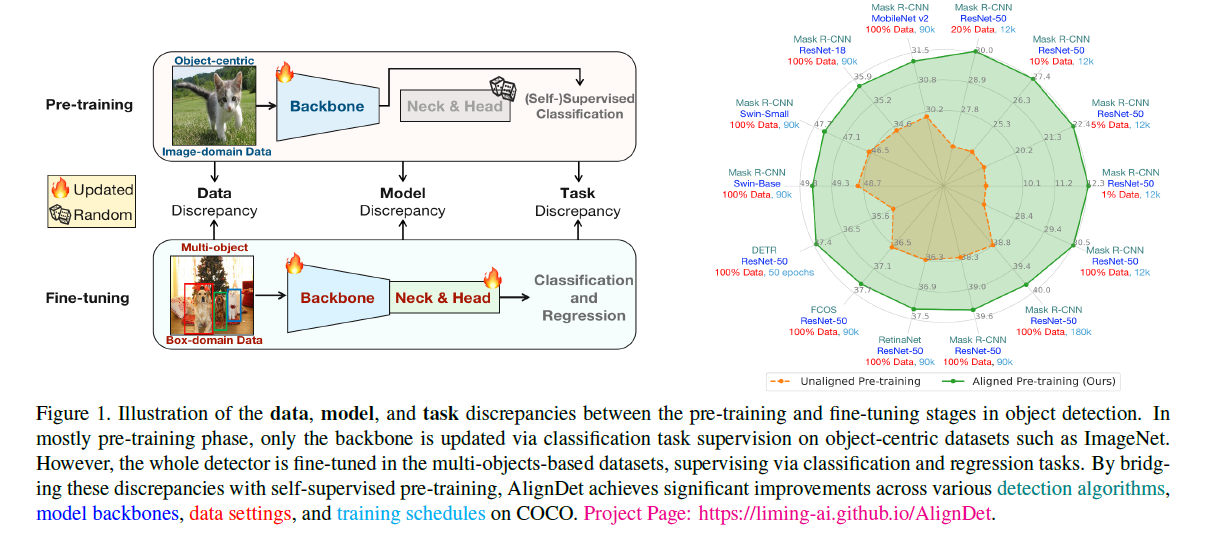
- Data Discrepancy
- Pre-training 에서 학습에 사용되는 데이터셋은 ImageNet과 같이 하나의 Object가 중심이 데이터셋을 활용
- Fine-tuning 에서는 Multi-object 들이 존재하는 데이터셋을 활용
- Model Discrepancy
- Pre-training 과정에서는 Backbone 만 학습하고 Detector 에서 중요한 Neck&Head는 random initialization 되고 Fine-tuing
- Task Discrepancy
- Pre-training 에서는 classification task 로 학습되기 때문에 object detection 에서 필요한 object-aware positional context 정보를 포함하지 못함
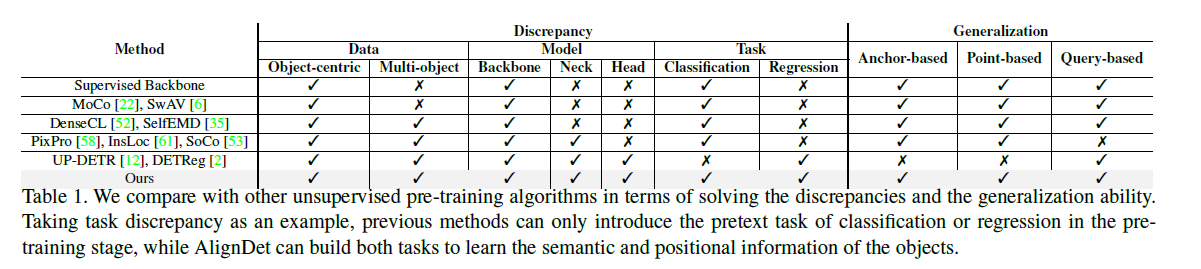
Data, object, model discrepancies 를 해결하는 방법을 제안
- Image-domain pre-training
- Box-domain pre-training
- 다양한 Detector 에 적용할 수 있는 Generalization 도 갖추었다
Proposed Method
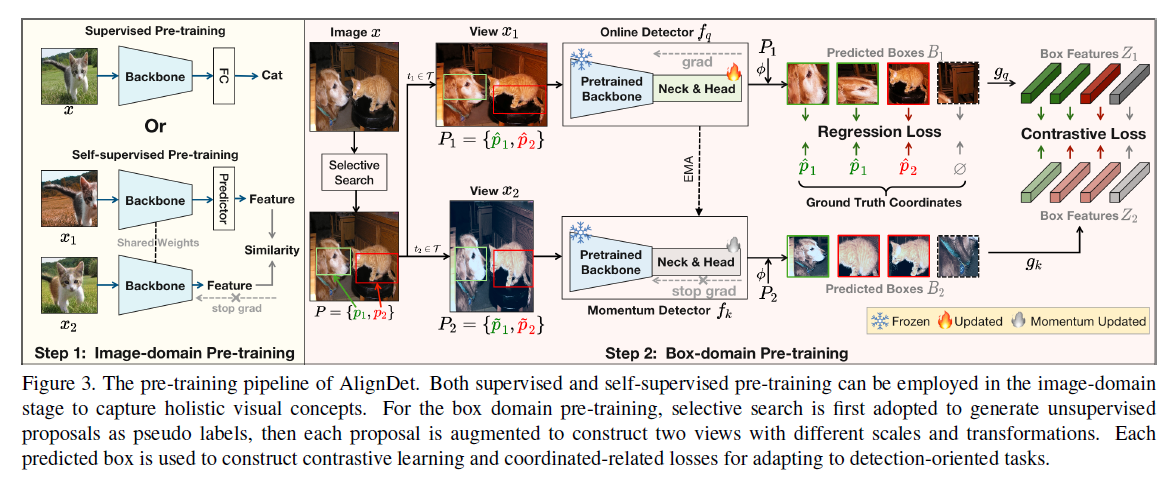
Image-domain Pre-training
optimizes the backbone to extract high-level semantic
ImageNet 데이터셋으로 backbone 부분만 pre-training
supervised 로 진행하거나 self-supervised 으로 학습
Box-domain Pre-training
Selective search 으로 물체 위치를 대략적으로 예측
두 가지 view 로 augmentation -> Figure 3 에서의 $P_1, P_2$
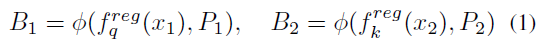
$P_1, P_2$ 를 GT로 두고 Online Detector $f_q$ 와 Momentum Detector $f_k$ 으로 얻어지는 prediction box 를 matching -> IoU 를 기준으로
Box-domain Contrastive Learning
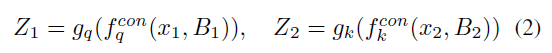
Contrastive Learning 을 위해 feature 를 추출한다
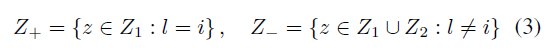
Positive set 와 Negative set 을 구한다
Eq 3. 에서 아무리 봐도 $z \in Z_1$ 이 $z \in Z_2$ 가 되어야할 것 같다..

하고 issue 를 찾아보니 오타라고 한다
Overall Loss
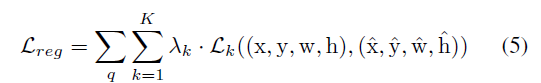
Regression Loss 는 Online Detector $f_q$ 의 prediction 결과와 $P_1$ 에 대해서 연산
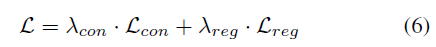
Experimental Results
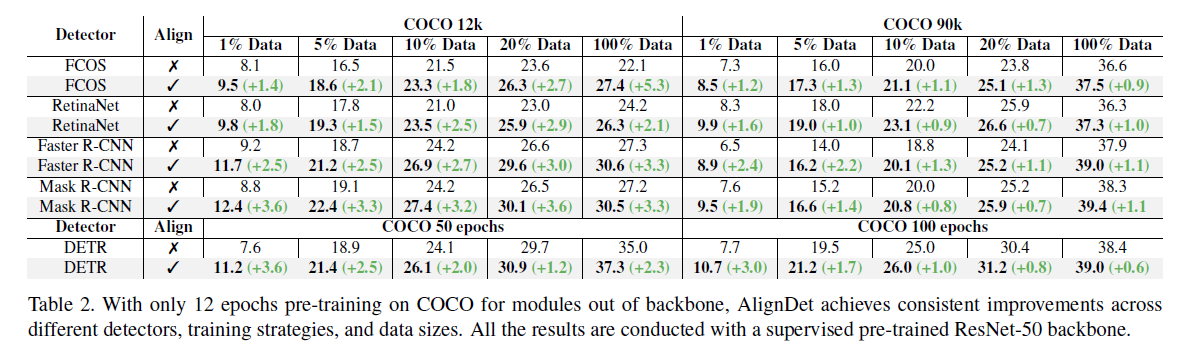
여러 Detector 방법들에 대해서 제안하는 pre-training 을 진행
1%, 5%, 10%, 20%, 100% 는 COCO 데이터셋에서 샘플링 비율\
To avoid over-fitting and demonstrate the advantage of faster convergence
제안하는 방법을 적용했을때 성능이 향상
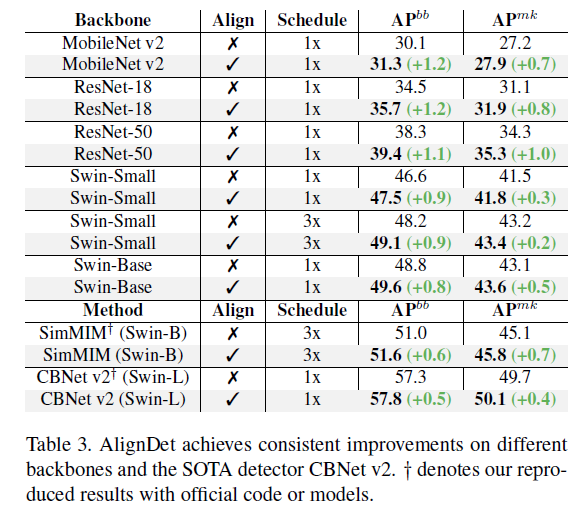
Mask R-CNN 에서 여러 backbone 에 대해서 적용해보았을 때
CVNet v2 에도 적용했을 때 성능 향상
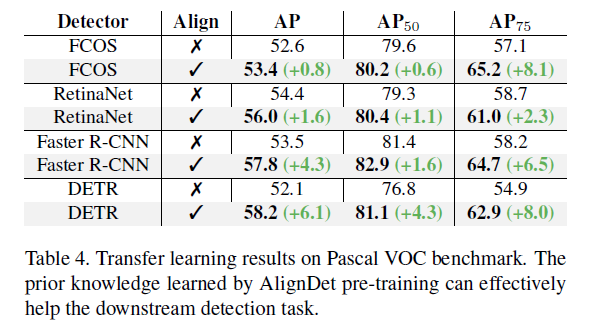
Pascal VOC 에 Transfer learning 해보았을 때도 성능 향상