Align-DETR: Improving DETR with Simple IoU-aware BCE loss
Align-DETR: Improving DETR with Simple IoU-aware BCE loss
Arxiv 2023.04, 2024-02-01 기준 5회 인용
Task
- Object Detection
- DETR
Contribution
- classification confidence 와 localization precision 가 서로 일치하지 않는 문제가 존재한다
- IoU-aware BCE Loss 를 제안하여 classification score 와 localization 결과가 일치하지 않는 문제를 다룬다
- Mixed-matching strategy 와 Prime sample weighting 을 제안하여 성능을 향상
Motivation
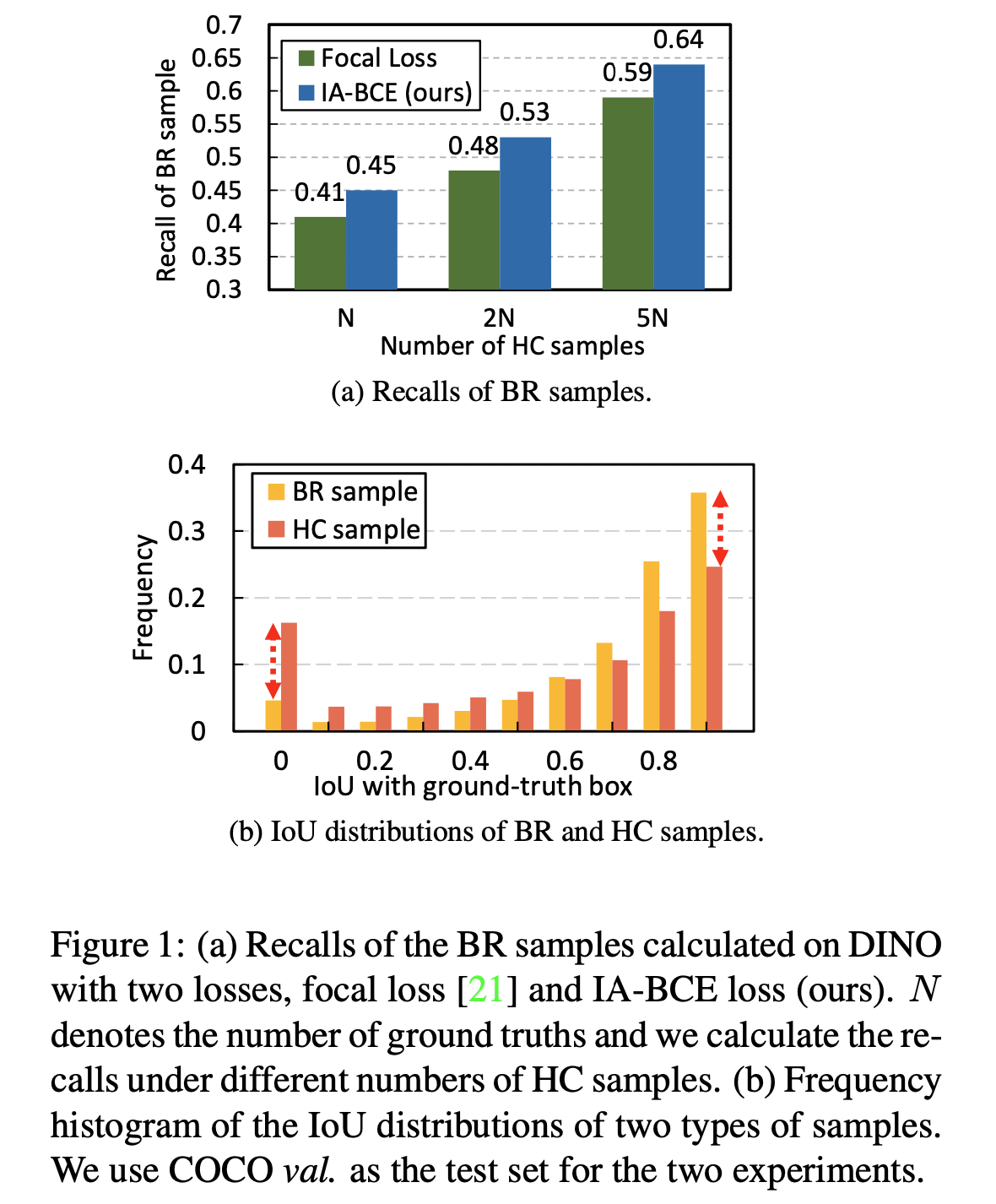
BR: Best-Regressed bounding boxes
HC: Highest Classification scores
DINO 에 실험
top-N, 2N 의 HC samples 에 대해서 Focal Loss 는 Recall of BR samples이 낮다
제안하는 방법을 적용할 경우 Recall of BR samples 값이 높아진다
IoU with GT box 에 따른 Frequency 를 비교해보았을 때 misalignment 문제를 확인할 수 있다
-> Classification score 값이 높지만 IoU가 낮고 IoU 값이 높지만 Classification score 값이 낮은 경우
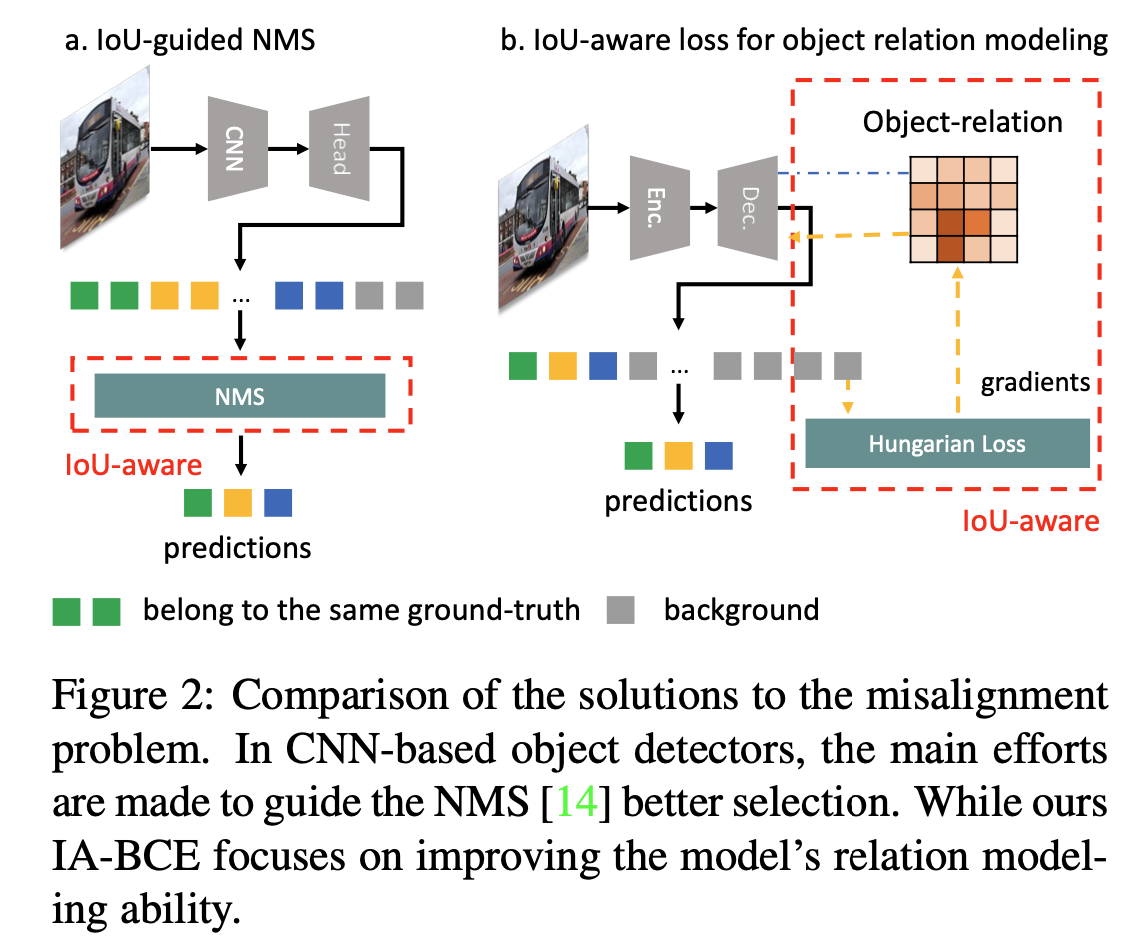
기존의 CNN-based Detector 들은 NMS 를 사용해서 IoU-aware 한 처리를 해주었다
본 논문에서는 DETR 에서 IoU-aware 하는 학습 방법을 제안
Proposed Method
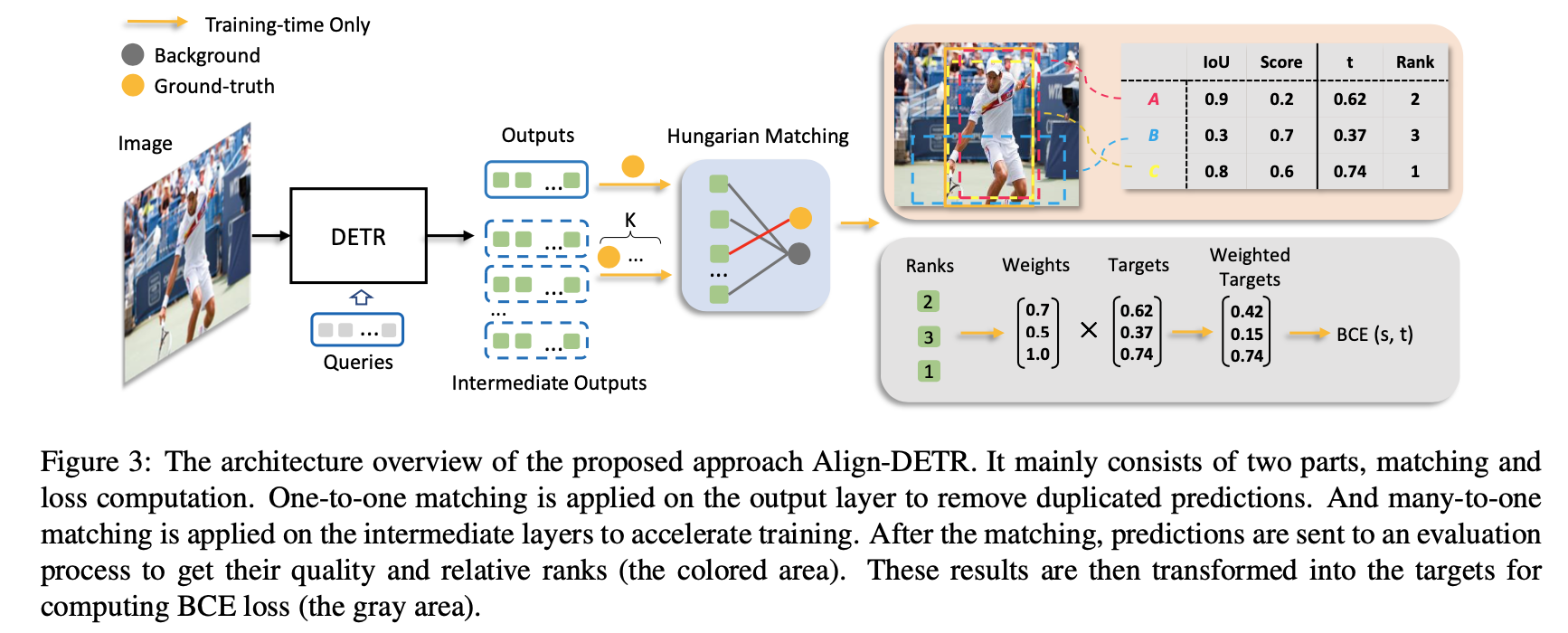
제안하는 방법의 Overview
기존의 DETR 계열의 구조와 동일하고 Loss 하는 부분만 변경
Iou-aware Classification Loss
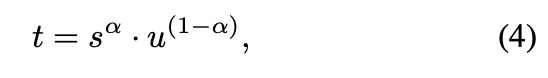
classification loss를 위한 target 을 confidence score $s$ 와 IoU score $u$ 를 활용
$\alpha$ 는 hyper-parameter 로 0.25 를 사용
$\alpha$ = 0 -> fully IoU-dependant $\alpha$ = 1 -> no IoU-dependant
smooths the training target and strengthens the correlation between classification and regression
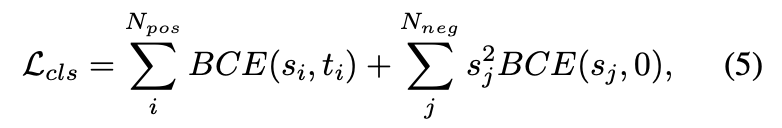
Positive sample 에 대해서는 Focal Loss 를 사용하지 않는다
DETR 에서는 positive sample 이 상대적으로 rare 하기 때문
we do not use the focal loss term to suppress “easy“ positive samples, since positive samples in DETR are relatively rare, and we want to keep their influence
Mixed Matching Strategy
$L-1$ decoder layers 까지의 결과들은 one-to-many 로 loss 연산
GT set 을 $k$ 개 복제
$L$ 번째 decoder layer 의 결과는 일반 GT set 과 one-to-one
-> 이렇게 하는 이유는 학습에 조금 더 많은 positive sample 들을 참여시키기 위해서
Prime sample weighting
Low-rank 의 positive samples 에 대한 것은 background 와 유사
![]()
위 그림과 같이 rank에 따른 weights 를 부여해서 loss 연산
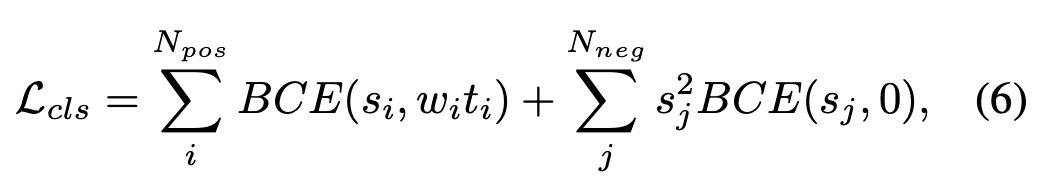
weights를 추가하여 classification loss를 재정의
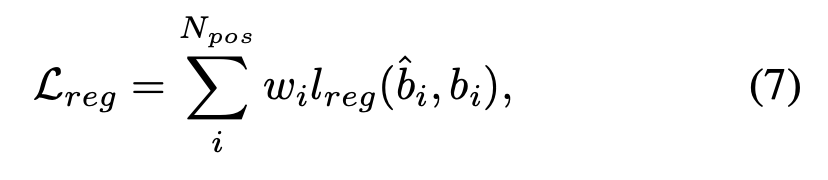
Regression loss 에도 weights 부여
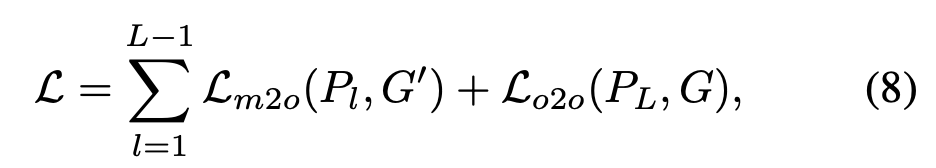
최종 Loss
$L-1$ 까지는 복제된 GT set $G’$ 에 대해서 one-to-many
$L$ 에 대해서는 GT 에 대해서 one-to-one
Experimental Results
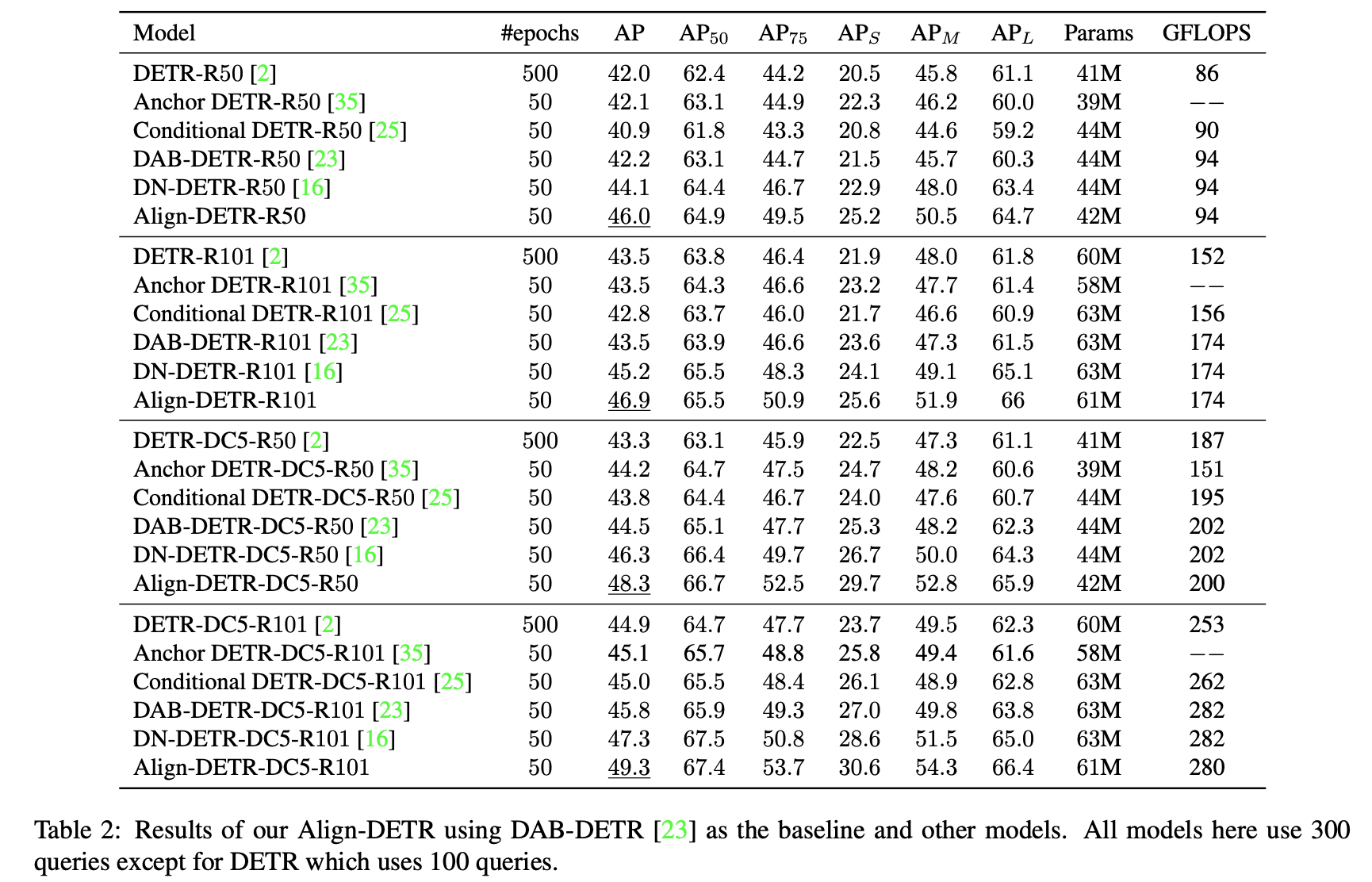
Single-scale 에서 비교
DAB-DETR 에 제안하는 방법을 적용
제안하는 방법을 적용했을 때 성능이 향상된다
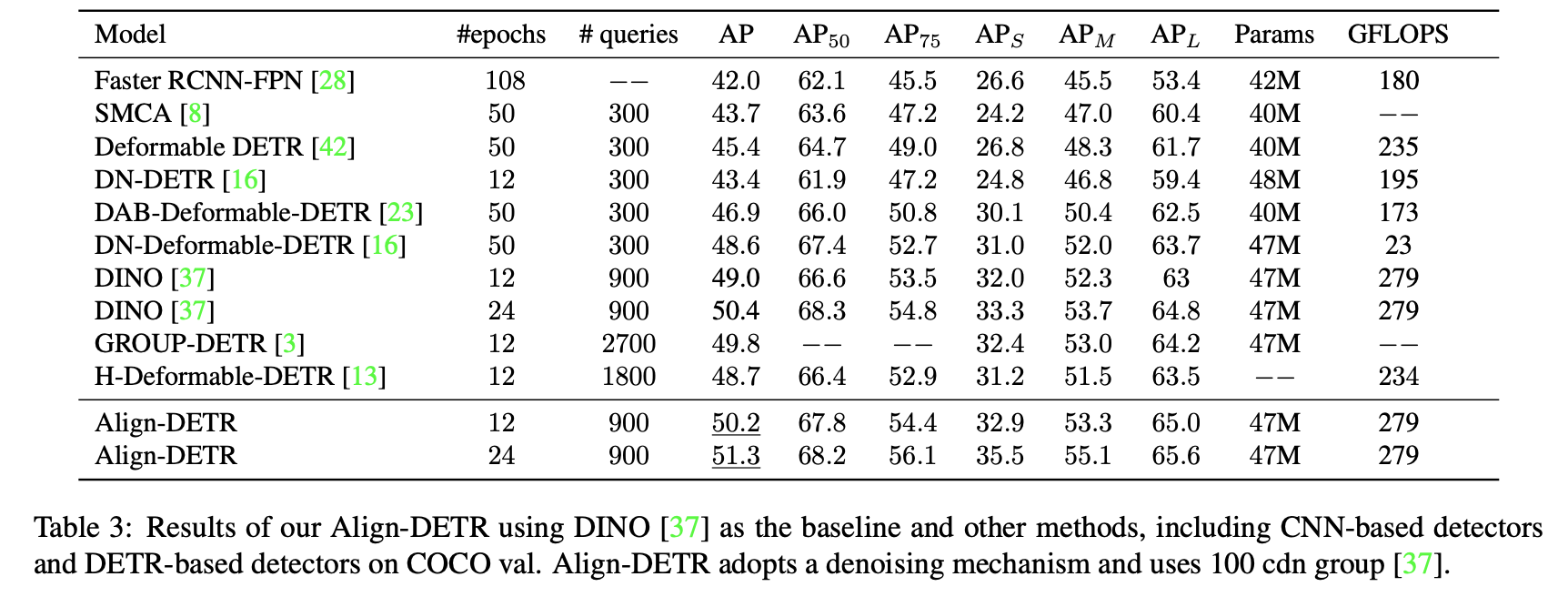
Multi-scale 방법들과도 비교
DINO 에 제안하는 방법을 적용
여기서도 마찬가지로 제안하는 방법을 적용했을 때 성능이 향상된다
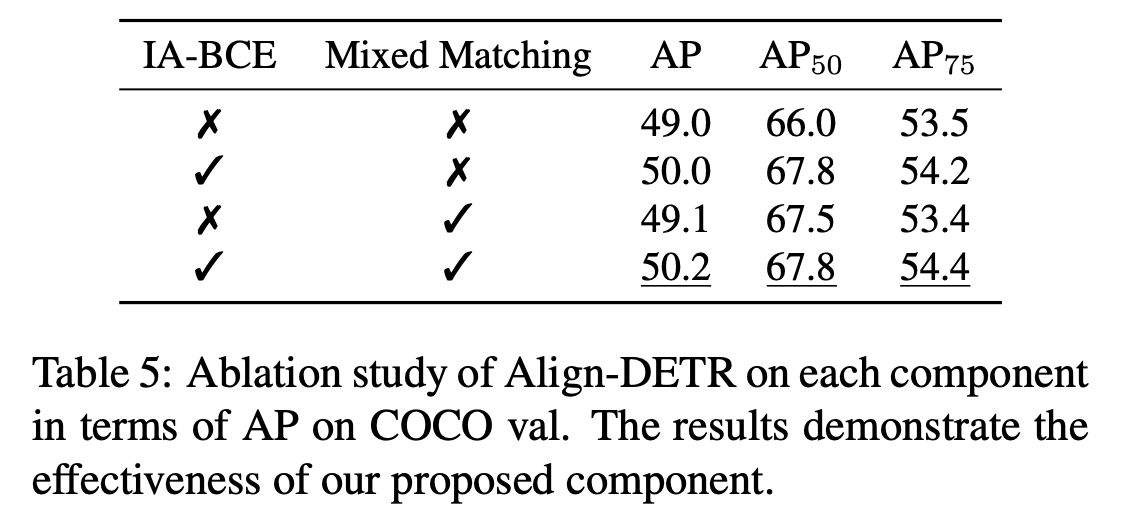
Mixed Matching 효과가 큰 것 같지는 않다
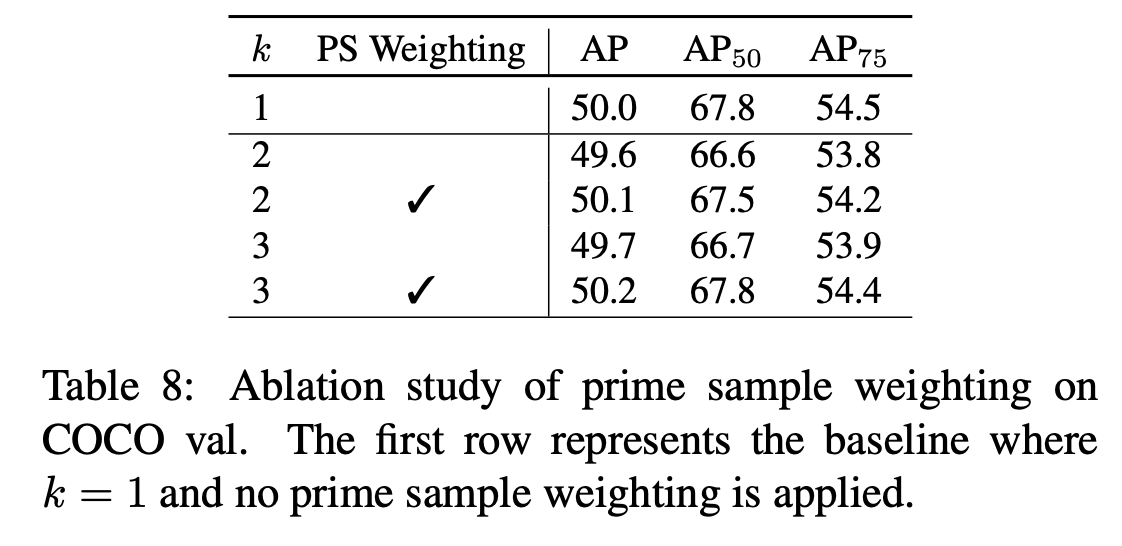
Prime sample weighting 도 효과가 큰 것 같지 않다