AdaMixer: A Fast-Converging Query-Based Object Detector
AdaMixer: A Fast-Converging Query-Based Object Detector
CVPR 2022 , 2024-01-01 기준 70회 인용
Task
- Object Detection
- DETR
Contribution
- 기존의 DETR, Deformalbe DETR 방법들은 query를 adaptive 하게 decode 하는 능력이 부족하다
- Each query adaptively samples features over space and scales based on estimated offset
- Dynamically decode these sampled features with an adaptive MLP-Mixer
본 논문에서 제안한는 방법인 AdaMixer가 기존의 방법들보다 더 빠르게 학습되고 성능이 좋은 것을 보여준다
Proposed Method
Object Query Definition
semantic 정보를 담고 있는 query와 positional view 정보를 담고 있는 query를 사용
- content vector $\boldsymbol{\text{q}}$
- positional vector $(x, y, z, r)$
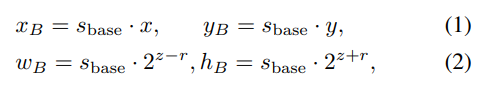
$(x, y, z, r)$ 과 $s_{base}$를 기반으로 원래 scale 이미지에 대한 bounding box로 decode
Adaptive Location Sampling
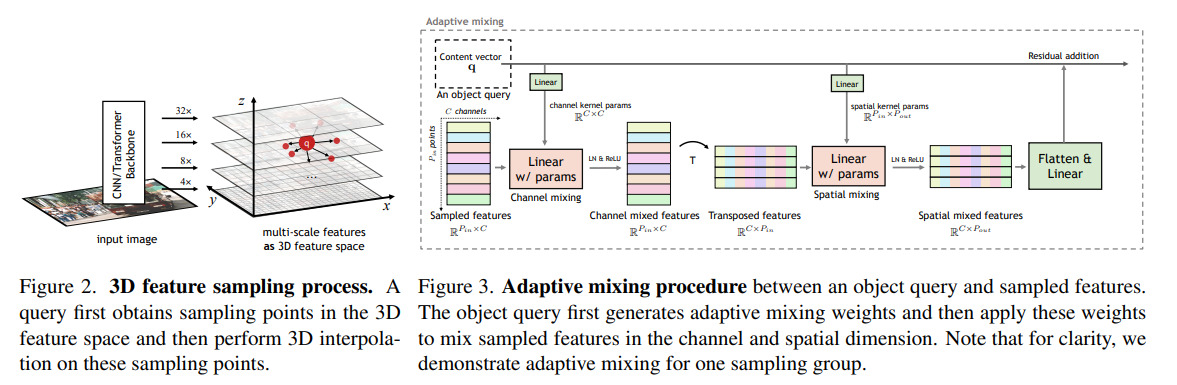
Multi-scale features as the 3D feature space
먼저, backbone 으로 부터 오는 multi-sacle feature 를 linear layer를 통해서 같은 채널 수 $d_{feat}$ 으로 조절해준다.
그리고 $H/s_{base}$ , $W/s_{base}$ 으로 rescale 한다. Figure 2 와 같이 align 시킨다.
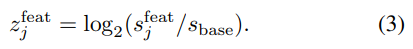
서로 다른 stride에 따른 각 scale feature map 에 따른 $z^{feat}_j$ 를 계산
Adaptive 3D feature sampling process
content query vector $\boldsymbol{\text{q}}$ 로 부터 offset vectors를 얻어낸다.
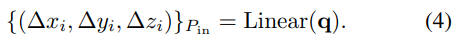
$P_{in}$ 개수 만큼 얻어낸다. 본 논문에서는 32를 사용한다.
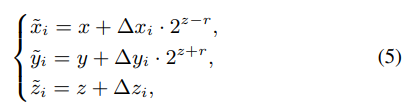
얻어진 $P_{in}$ 개의 offset 을 기반으로 기존 positional query $(x, y, z)$ 로 부터 $(\tilde{x}_i, \tilde{y}_i, \tilde{z}_i)$ 를 얻어낸다.
그 후 해당 points 들을 $(x, y)$ space 로 bilinear interpolation 하여 features를 sampling 한다.
- 각 scale의 feature map 에 대해서 수행후 더해준다 (code를 통해서 확인한 부분)
- 그 후 아래 (6) 번식을 통해서 scale $z$ 에 대한 weight를 연산하고 곱해준다. (code를 통해서 확인한 부분)
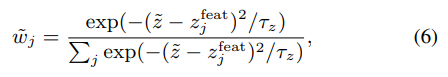
앞서 (3) 번식으로 구한 $z^{feat}_j$ 을 기반으로 gaussian weighting
이를 통해서 최종적으로 samplied feature matrix $\boldsymbol{\text{x}}$ 를 얻어낸다. 크기는 $\mathbb{R}^{P_{in}\times d_{feat}}$ 이다.
Adaptive Content Decoding
With features sampled, how to adaptively decode them is another key design in our AdaMixer decoder.
Adaptive channel mixing
Adaptive Channel Mixing (ACM) 구조를 제안
content query $\boldsymbol{\text{q}}$ 를 통해서 channel sematics 를 adaptively enhance 하기 위해서
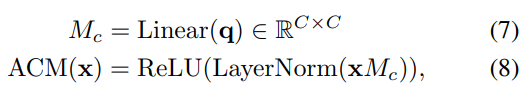
Adaptive spatial mixing
sampled features 의 spatial strucutes 에 query 에 mixing 될 수 있도록 하는 Adaptive Spatial Mixing (ASM) 구조를 제안
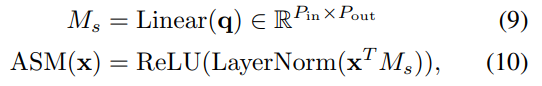
$P_{out}$ 은 spatial mixing out patters 수
Overall AdaMixer Detector
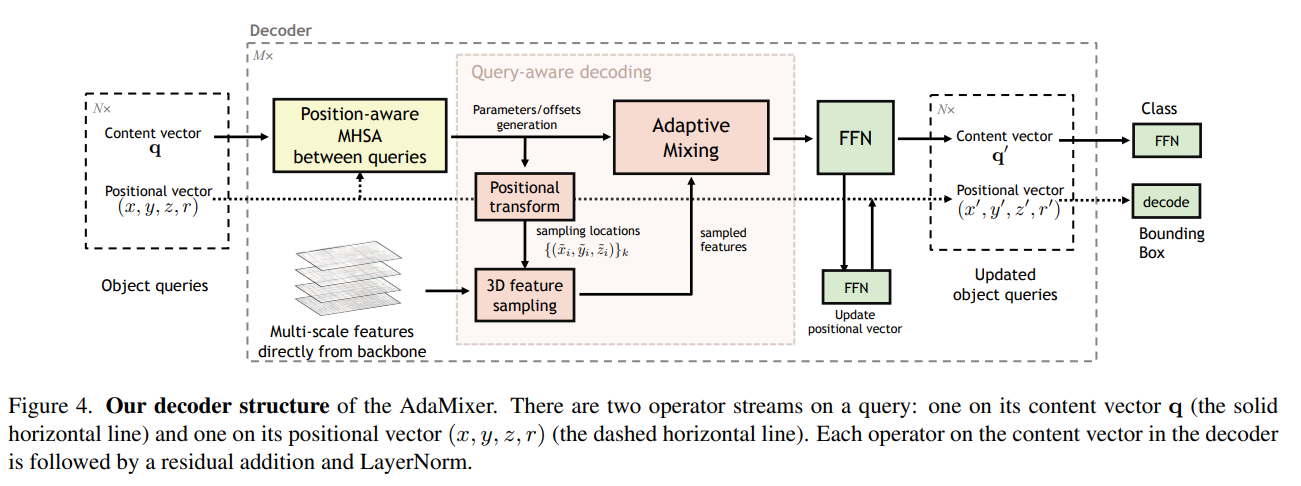
FFN을 통해서 새로운 content query vector $\boldsymbol{\text{q}}$ 를 얻어내고 또 다른 FFN 을 통해서 positional query vector 업데이트한다.

Position-aware multi-head self-attentions
저자들은 content query 와 position query 를 두개 나누어 사용하기 때문에 기존의 self-attention 방식으로는 geometric relation 을 파악하기 어렵다고 주장
$(x, y, z, r)$ 를 기반으로 positional embedding
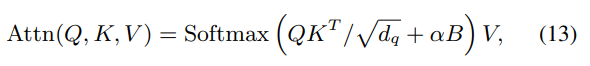

그리고 attention weight 에 intersection over foreground (IoF) 를 추가
- query box 들 간에 겹치는 관계들을 위주로 집중
Experimental Results
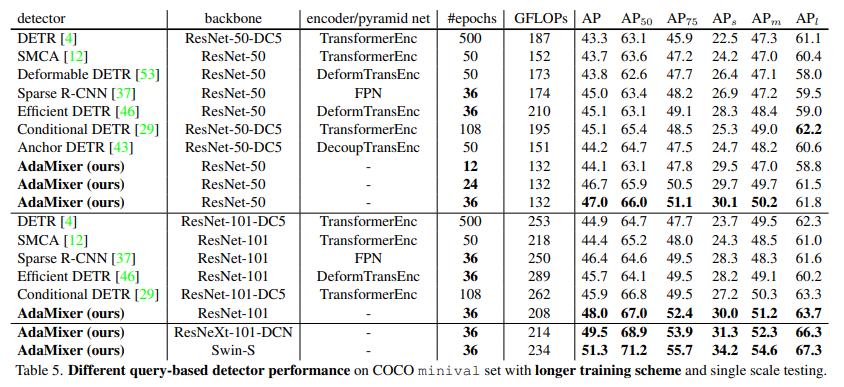
기존의 DETR 방법들과 비교하였을때 가장 좋은 결과를 보여준다.